PyTorchのRNNクラスとRNNCellクラスを再発明しよう:作って試そう! ディープラーニング工作室(2/2 ページ)
MyRNNクラスを使っての学習と評価
次に、今定義したMyRNNクラスとNetクラスを使って、学習と評価を実行してみましょう。学習するコードは関数として、この後にも使うことにします。
def train(epocs, net, X_train, y_train, criterion, optimizer):
losses = []
for epoch in range(EPOCHS):
print('epoch:', epoch)
optimizer.zero_grad()
hidden = torch.zeros(num_batch, hidden_size)
output, hidden = net(X_train, hidden)
loss = criterion(output, y_train)
loss.backward()
optimizer.step()
print(f'loss: {loss.item() / len(X_train):.6f}')
losses.append(loss.item() / len(X_train))
return output, losses
前回の学習を行うコードを関数として、エポック数、ニューラルネットワークモデル、訓練データと正解ラベル、損失関数と最適化アルゴリズムを受け取るようにしたところ以外は変更点はほぼありません。が、強調表示で示した「hidden = torch.zeros(num_batch, hidden_size)」という行だけが、少し違っています。PyTorchのRNNクラスは、複数のRNN層を積み重ねることが可能ですが、今回のMyRNNクラスではこれをサポートしていません。そのため、隠れ状態の初期値となるテンソルの初期化が少し変わっています(詳細な説明は省略します)。
後は、学習に必要な要素(訓練データ、正解ラベル、Netクラスのインスタンス、損失関数、最適化アルゴリズム)を生成して、上記のtrain関数に渡すだけです。
num_div = 100 # 1周期の分割数
cycles = 2 # 周期数
num_batch = 25 # 1つの時系列データのデータ数
X_train, y_train = make_train_data(num_div, cycles, num_batch)
input_size = 1 # 入力サイズ
hidden_size = 32 # 隠れ状態のサイズ
output_size = 1 # 出力層のノード数
net = Net(input_size, hidden_size, output_size)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.05)
最後にエポック数と共に、これらをtrain関数に渡します。戻り値は最後の学習結果の出力と平均損失を含んだリストになっています。
EPOCHS = 100
output, losses = train(EPOCHS, net, X_train, y_train, criterion, optimizer)
実行結果を以下に示します。
 実行結果
実行結果損失がどんな状態をグラフにプロットしてみましょう。
plt.plot(losses)
実行結果を以下に示します。
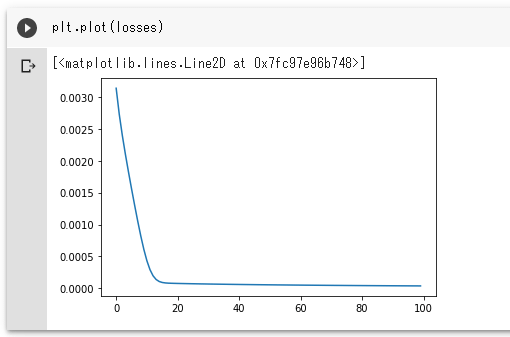 実行結果
実行結果前回と同様なグラフとなりました。最後の学習結果を基に、サイン波の推測ができているかも確認してみましょう。
output = output.reshape(len(output)).detach()
sample_data, _ = make_data(num_div, cycles)
plt.plot(range(24, 200), output)
plt.plot(sample_data)
plt.grid()
実行結果を以下に示します。
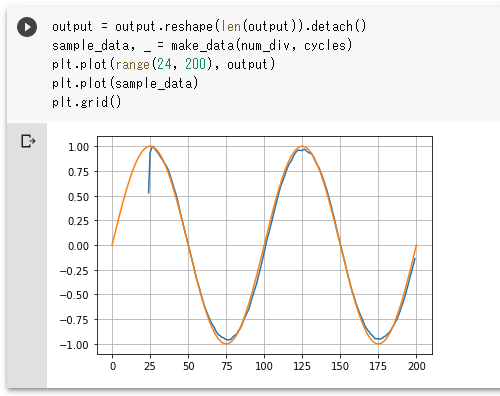 実行結果
実行結果こちらに関しても前回と同様な結果となりました。
MyRNNCellクラス
ここでRNNクラスを置き換えるMyRNNクラスができたので、ここで終わってもよいのですが、PyTorchが提供するRNNCellクラスを使っている点にはちょっと不満もあります。そこで、最後にRNNCellクラスを置き換えるMyRNNCellクラスも定義してみましょう。
不思議なことにMyRNNCellクラスのコードは、MyRNNクラスのコードと似たものになりますが、その理由は、MyRNNクラスは時系列データのシーケンスを取り扱い、MyRNNCellクラスは時系列データを取り扱うからです(時系列データもまた数値が連続するシーケンスです)。今回の実装ではどちらもforループを使って、MyRNNクラスではシーケンスを取り出して、MyRNNCellクラスは時系列データを構成する個々の値を取り出して、それらを処理するという形式は同じです。
そうはいっても、違うところはあります。MyRNNクラスではRNNCellクラスを呼び出して、時系列データを処理していました。では、MyRNNCellクラスではどうすればよいでしょうか。ここではちょっと手抜きをして、RNNCellクラスのドキュメントなどを基にコードを書きました。以下にRNNCellクラスのドキュメントの冒頭を示します。

要するに、「h' = tanh(Wih+bih+Whh+bhh)」を計算すればよいということです。ここで「h'」は「RNNCellが受け取った時系列データの各要素について、その次の要素を使って計算を行うときに使用する隠れ状態が集められたもの」です(ここでは25×32サイズのテンソルとなります)。
また、「Wih」と「bih」は「入力(時系列データ)に対して用いる重みとバイアス」を意味します。「Whh」と「bhh」は「RNNCellに入力される隠れ状態に対して用いる重みとバイアス」です。
重みやバイアスを使った計算を囲んでいる「tanh」はもちろん活性化関数です。PyTorchのRNNクラスやRNNCellクラスでは、インスタンス生成時に特に指定をしなければ、デフォルトでtanh関数が使われるようになっています。
難しいようにも見えますが、これは入力層からの入力(ここでは1個の数値)と隠れ状態(ここでは32個の数値)に対して、重みとバイアスを使用した計算をするというだけのことです。そこで、ここでは入力と隠れ状態を1つのテンソルにまとめて、PyTorchのLinearクラスを使った全結合型の計算を行うことにしました。この計算結果が次の隠れ状態の値となるので、その出力の数は隠れ状態のサイズと同じです。
ということで、入力数として「入力層のノード数+隠れ状態のサイズ」を、出力数として「隠れ状態のサイズ」を指定して、Linearクラスのインスタンスを作れば、上に示した計算が実現できそうです。
後は、計算するたび(Linearクラスのインスタンスを呼び出すたび)にその結果(時系列データに含まれる一つ一つの値に対応した隠れ状態です)を戻り値用のテンソルに蓄積していき、最後にそのテンソルを返送することでRNNCellクラスと同様な処理を実現できるでしょう。
これをコードにまとめたのが以下です。
class MyRNNCell(torch.nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.fc = torch.nn.Linear(input_size + hidden_size, hidden_size)
def forward(self, x, hidden):
count = len(x) # batch num
output = torch.Tensor()
for idx in range(count):
x_tmp = x[idx].reshape(1, -1)
h_tmp = hidden[idx].reshape(1, -1)
tmp = torch.cat((x_tmp, h_tmp), 1)
tmp = torch.tanh(self.fc(tmp))
output = torch.cat((output, tmp))
return output
__init__メソッドでは、入力サイズと隠れ状態のサイズをインスタンス変数に保存して(どちらも使ってはいませんが)、それらを使ってLinearクラスのインスタンスを生成しているだけです。インスタンス生成時に指定する入力数が「入力サイズ+隠れ状態のサイズ」に、出力数が「隠れ状態のサイズ」になっている点には注意してください。
forwardメソッドでは、時系列データを構成する要素の数を調べて、その数だけforループを実行しています。forループの内部では、その後の処理で都合が良くなるようにテンソルの形状を変更した後に、全結合型の計算を行って、それらをtorch.catメソッドで変数outputに蓄積するようにしました。最後に、それを呼び出し側に戻します。
ここまでのコードを見ると、「MyRNNクラスでは全ての時系列データを個々の時系列データにほどいて、MyRNNCellクラスではほどかれた時系列データをさらに個々のデータにほどいて処理をして、その中で隠れ状態を使って、あるデータが別のデータに影響を及ぼしていく」いう感覚が掴めるかもしれません。
PyTorchのRNNクラスは、こうした面倒くさい処理をプログラマーがほんのわずかな行数を書くだけで、高速に実行してくれるので、RNNでどんな処理が行われているのかを知りたいという事情でもない限り、PyTorch(に限らず機械学習/ディープラーニングのフレームワーク)を使うのであれば、通常は既に用意されているものを使うのが正解です。
では、このMyRNNCellクラスを使って、先ほどのMyRNNクラスを書き換えます。といっても、変更点は以下のコードで強調書体で表示されているところだけです。
class MyRNN(torch.nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = MyRNNCell(input_size, hidden_size)
def forward(self, x, hidden):
count = len(x) # sequence length
output = torch.Tensor()
for idx in range(count):
hidden = self.rnncell(x[idx], hidden)
output = torch.cat((output, hidden))
output = output.reshape(len(x), -1, self.hidden_size)
return output, hidden
この後は、Netクラスのインスタンスを生成して(生成時点で修正後のMyRNNクラスのインスタンスがNetクラス内部で使われます)、その他もろもろの要素を用意し、train関数を呼び出すだけです。
num_div = 100 # 1周期の分割数
cycles = 2 # 周期数
num_batch = 25 # 1つの時系列データのデータ数
X_train, y_train = make_train_data(num_div, cycles, num_batch)
input_size = 1 # 入力サイズ
hidden_size = 32 # 隠れ状態のサイズ
output_size = 1 # 出力層のノード数
net = Net(input_size, hidden_size, output_size)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.05)
EPOCHS = 100
output, losses = train(EPOCHS, net, X_train, y_train, criterion, optimizer)
このコードは上で紹介したのと全く同じなので、説明と実行結果は省略します。最後に損失と最後の学習結果を基にしたサイン波の推測結果を表示しておきましょう。こちらもコードは上で見たのと同じです。
plt.figure()
plt.plot(losses)
plt.figure()
output = output.reshape(len(output)).detach()
sample_data, _ = make_data(num_div, cycles)
plt.plot(range(24, 200), output)
plt.plot(sample_data)
plt.grid()
実行結果を以下に示します。
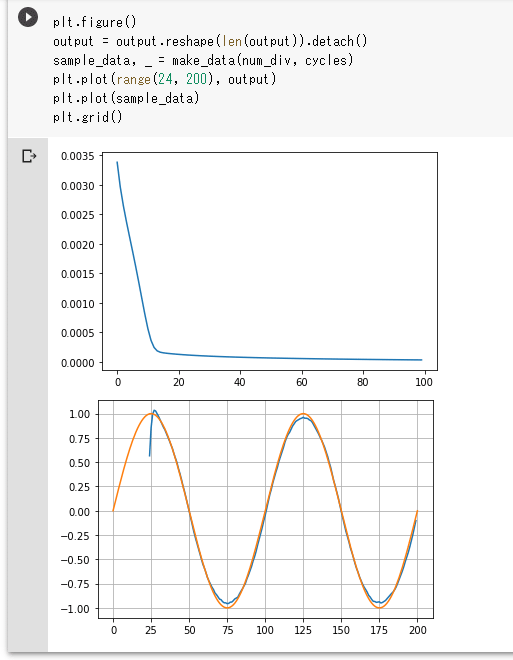 実行結果
実行結果先ほどと同様な結果が得られたことから、MyRNNCellクラスもある程度は機能しているといえるでしょう。
今回はRNNを実現するために2つのクラスを自分で作りながら(車輪の再発明)、PyTorchのRNNクラスではおおよそこんな感じのことが行われているのだろうというところを見ました。冒頭にも述べましたが、PyTorchのRNNクラス/RNNCellクラスはより複雑で高度な処理を実現しているので、今回のコードはあくまでもその基礎となる考え方をPythonで書き表したものです。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。