PyTorchでオートエンコーダーによる画像生成をしてみよう:作って試そう! ディープラーニング工作室(1/3 ページ)
画像生成の手始めとして「オートエンコーダー」と呼ばれるニューラルネットワークを作って、MNISTの手書き数字を入力して、復元してみましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
前回までは、ニューラルネットワークの基本となる要素(全結合型のニューラルネットワーク、CNN、RNN)について見てきました。基礎知識編は取りあえず前回までとします。今回からは、もう少し高度な話題にチャレンジしていこうと思います。
本題に入る前に、応用実践編のスタートとして、本連載の成り立ちや趣旨、目的について、あらためて簡単に紹介しておきます。筆者自身、@IT/Deep Insiderフォーラムが始まってから、ディープラーニングを本格的に学び始めた者の一人です。そんな筆者が、まるで「工作室や実験室、ガレージ」で何か面白いものを作りながら、ディープラーニングについての理解を深めていき、その体験や知見を読者と共有していこう、というのが本連載の趣旨/目的です。連載名「作って試そう! ディープラーニング工作室」にはそういった意味があります。読みやすさを考え、一部、解説記事として同じような書き方にしていますが、本連載は何も「教科書」のように肩肘を張って読む必要はありません。筆者の体験談や失敗談、そこから得た知見を楽しみながら読んでみてください。できれば筆者が通った道をぜひ手を動かしながら追体験してみてください。頑張って一緒に学んでいきましょう。
さて、いきなり余談から入ってしまいましたが、今回は基礎卒業後の応用編として画像生成に挑戦してみます。
今回の目的
画像生成といっても、何も分からないところからいきなりリアルな人の画像を生成できたり、2次元(または異次元)の世界に住んでいそうなかわいい女の子の画像を生成できたりはしないでしょう、たぶん。そこで今回は手始めにMNISTの手書き数字を読み込んで、同じ数字の画像を復元できるようなニューラルネットワークを作ってみることにしました。本当はCIFAR-10というデータセットが提供する画像をサンプルにしようと思ったのですが、まあそれについては後で見てみることにしましょう。
一口に画像生成といってもそのやり方はたくさんです。Googleで「ディープラーニング 画像生成」として検索してみると、今は「GAN」(Generative adversarial networks、敵対的生成ネットワーク)が検索結果の上位を占めています。

はやりに乗ってこっちを攻めてみようかとも思いましたが、もっと簡単そうなものはないものかと思って探してみたのが今回取り扱うオートエンコーダー(Autoencoder)です(GANについては、画像生成の話を続けていく中で手を付けてみたいと思っています)。
今回はこのオートエンコーダーを使って、MNISTの手書き数字(と似た画像)を生成しながら、オートエンコーダーの基本構造、PyTorchを使った簡単な実装、オートエンコーダーがどんなことをしているのかを考えてみることにしましょう。
オートエンコーダーとは
「Autoencoder」の「Auto」はもちろん「自動」といった意味です。次の「encoder」は「エンコード(符号化)するもの」という意味で、日本語では「符号化器」と表記されることもあります。つまり、「自動的に符号化を行うもの」がオートエンコーダーということです。「自動符号化器」のように表記されることもあるようです。
そういってもよくは分かりませんよね。ここで少し、Pythonの文字列というか文字について考えてみましょう。例えば、文字「0」という数字を画面に表示するにはもちろん次のようにすればよいだけです。
print('0')
このコードは、Pythonの処理系に「'0'という文字を表示してくれ」と命令するものですが、これが可能なのは、文字「0」に固有の番号が割り振られているからです。実際に試してみましょう。
print(ord('0')) # 48
これを実行すると、「48」という整数値が返されます。文字「0」には「48」という整数値が割り振られていて、「print('0')」を実行すると、Pythonは「ああ、48番の文字を表示すればいいのね」と解釈し、それを画面に表示してくれているというわけです(プログラマーがchr関数を使って、特定の文字に割り振られた番号を指定して、その文字を得ることもできます)。これにより、例えば「8×16」=128ピクセルで表現される文字「0」を1個の整数値として扱えるようになっています。このような「何かを何かに割り振る」ことがエンコードだと考えればよいでしょう。
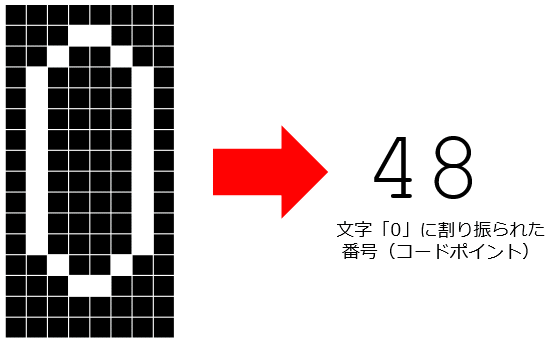 文字「0」は整数値「48」にエンコードされている
文字「0」は整数値「48」にエンコードされているこのとき、文字「0」の各ピクセルが黒(0)と白(1)のどちらかで構成されているとしましょう。文字「0」が横方向に8ピクセル、縦方向に16ピクセルで表されているとすると、横方向に0か1が8個=1バイト、縦方向に1バイトのデータが16個並んでいるとも考えられます。つまり、8×16ピクセルの2値(黒か白)の文字を表すには16バイトが必要となるのに、これに割り振られた番号である「48」という数値は1バイト(0〜255)の範囲に収まります。エンコードをしなければ、表現に16バイトが必要だったものが、エンコードをすればその16分の1のデータ量=1バイトで表現できるというわけです。このようにもともとのデータ(文字「0」のピクセル表現)が持つデータ量を削減することを、機械学習の世界では「次元削減」と呼んだりもします。

そして、この整数値「48」を「文字として画面に表示してくれ」とPythonに伝えると、8×16ピクセルで表現される文字「0」が見事に復元されて、画面に表示されます(もちろん、現代のコンピューティング環境では同じ文字でも、異なるフォント、異なるフォントサイズで表示されるので、これはあくまでも例え話です)。このように、エンコード後のデータからエンコード前のデータに復元することを「デコード」(decode)と呼びます。
オートエンコーダーがすることもこれと似ています。ここで例とするMNISTデータセットでは、以前にも話したように、手書き数字は28×28のサイズを持ち、その各要素が0〜255の範囲の数値で表現されます。これをもっと小さなサイズのデータへと「次元削減」して、削減後のデータから元の手書き数字を復元してみようということです。
これを実際に行う手順はだいたい次のような図で説明されます。

ところで、学習を行う際の正解ラベルには何を使えばよいでしょう。これは手書き数字を入力して、手書き数字を出力するニューラルネットワークです。となると、正解ラベルとなるのは、元の手書き数字です。そのため、ここでは正解ラベルを使わずに、出力と元の手書き数字とを比較して、損失を求めることになるのは覚えておきましょう。
今回は、上の図に示したような手順で、784個(784次元)の入力から段階的に次元削減を行いながら、最終的に2次元のデータとなるまで次元を削減していきます。この処理を行う部分を「エンコーダー」(encoder)と呼びます。その後、次元削減とは逆に段階的に次元を増やしていきながら最終的に784個の出力を得ます。この処理を行う部分を「デコーダー」(decoder)と呼びます。そして、その全体をつかさどるのがオートエンコーダーになります。
次ページでは、これを実際に行うクラス、学習を行うコードなどを見ていきましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。