第1回勉強会:なぜ今MLOpsなのか、先駆者や実際の現場からMLOpsを学ぼう:MLOpsイベントレポート
MLOpsコミュニティーのイベントレポート連載。今回は「MLOpsとは何で、今なぜそれが必要なのか」「実際にMLOpsでやることとは何か」「機械学習モデルの開発から運用におけるMLOpsがなぜうまくいかないのか、どうすればよいのか」について学ぶ。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
MLOpsコミュニティーは「全ての機械学習モデルが現場で実運用化される世界」を目指して2020年夏に始まりました。月1回程度の頻度での活動を目指し、勉強会やワークショップ、ディスカッションなどを行うことで、今後のAI技術の発展に非常に重要な、MLOps(機械学習の実運用化)の普及に貢献していきます。
このレポートでは、2020年8月に行われた第1回勉強会の様子をお伝えします。300人以上の参加者がリモートで参加し、大盛況のイベントとなりました。当日の様子はツイッターでも盛んにつぶやかれ、こちらにそのまとめがあります。
なぜ今MLOpsなのか by シバタアキラ
はじめに、オーガナイザーチームの一人である、DataRobot Japanのシバタアキラから、なぜ今MLOpsが注目されているのかをお話しました。まず300人以上にGoToWebinarのアンケート機能を使って質問しました。
「今までにいくつの機械学習モデルを構築したことがありますか?」
という質問に対して下記のような結果が返ってきました:

それに対して「自分の作ったモデルで現在実運用されている数は?」という質問にはこのような結果が返ってきました:

このようにたくさんの機械学習モデルが構築されながら、そのほとんどが使われずに終わっている現状が浮き彫りになりました。これは驚きではなく、世界中のML利用者の中で指摘されてきたことです。機械学習の利用にはモデル構築の技術的なハードルを越えることができたとしても、まだまだたくさんの障壁があるのです。それをどうやって解決したらよいのかを考えていくことが、このコミュニティーの最大のミッションではないかと思っています。
この問題に関して理解を深めるために「10,000-Year Clock(1万年時計)」のお話をさせていただきました。このプロジェクトは、AIの生みの親とも言われるMarvin Minskyのもとで学んだDanny Hillsにより提案された、「1万年動き続ける(機械式)時計を作る」というプロジェクトです。この時計のプロトタイプは1999年に完成され、2000年になった瞬間に1000年に一度しかならない鐘の音を響かせました。その後、アマゾン創設者のJeff Bezosの協力の下、フルサイズ版が現在テキサス州に建設中です(動画1)。
動画1 YouTube「Time-lapse reveals inside of 10,000-year clock built by Amazon's Jeff Bezo」を引用
一方でこのプロジェクトに新しい観点から取り組んだのが、作家のNeal Stephensonです。彼は『ANATHEM』という小説(図3)で、1万年動き続ける時計の形として、時を神として崇(あが)め、儀式として時を刻み続ける宗教集団の物語を生み出しました。時計は機械式なのですが、その運用は人の手によって営まれ、高い地位に有る僧侶が100年、1000年などのより長い期間の時計を動かすことを担当しています。

なぜ1万年時計の2つの解決方法がMLOpsに関係しているのか? それは機械学習モデルの実運用化には重要な二面性があるからです。
一方では、動き続けるモデルを作ることには技術的なチャレンジがあります。最新のデータを収集し、モデルに入力するためのデータパイプラインの構築。定期的に、もしくは外部からのリクエストに応じて予測を行うためのAPIサーバーや、それを安定して運用していくためのインフラおよび監視&管理オペレーションの構築などがそれに当たります。
他方では、機械学習モデルのビジネス、R&D、サービスへの導入には人間的な側面があることが無視できません。業務AI化への不信から導入に反対する現場、どれだけ説明しても理解しようとしてくれない意思決定者、モデルのデプロイ作業への協力に消極的なIT部門の巻き込み、などなど、AIを実運用化していくためには人間も動かしていかなくてはならない重要な部分です。前述の小説に習えば、いま組織全体をMLOps教に入信させる必要があるのかも知れません(笑)。
このコミュニティーではAIを現場で本当に使っていくために必要とされている技術と人の両側面から今必要とされているMLOpsについて理解を深めていきたいと思っています。
先駆者に学ぶMLOpsの実際 by Mobility Technologies 渡部さん、齋藤さん
シバタアキラに続き、Mobility Technologiesの渡部さん、齋藤さんが登壇されました。渡部さんは2019年にニューヨークで開催された“MLOps NYC 19”カンファレンスに参加されるなど精力的にこの分野の情報を収集されており、また齋藤さんと共に実際にMobility Technologies(旧JapanTaxi)での機械学習モデルの運用に取り組まれています。
渡部さんはまず「MLOpsにはまだ固定的、確定的な定義はない」と問題提議をしつつ、これまでのMobility Technologiesでのモデル運用のご経験から、
MLOpsとは「システム開発においてデータサイエンティストがやらないこと全て」である
という定義をされました。
データサイエンティストはモデルを作り、使えるようにする。つまりデータから特徴量を生成し、モデルを作成し、予測を行えるようにすることが守備範囲となります。
その一方、その作業のためにはDWH(データウェアハウス)への接続を定義してデータを抽出する作業、抽出されたデータのバージョンを管理する作業、モデル開発のために利用されたコード管理(バージョニング)、これらを実際に実行するためのITインフラ環境の準備など(図4を参照)、背後には多くのタスクが隠れていると渡部さんは指摘しています。
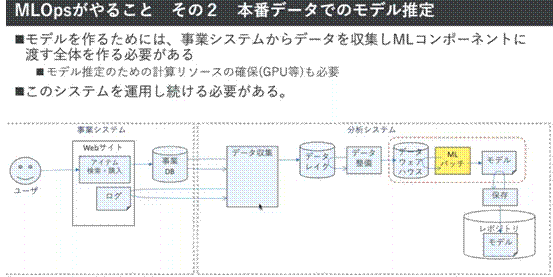 図4 「MLOpsがやること」その2:本番データでのモデル推定
図4 「MLOpsがやること」その2:本番データでのモデル推定また、モデルを開発するところまでを整備し、予測ができたとしても「1円も儲(もう)からない」ことから、最終的に利用されるシステム(ビジネスの仕組み)に組み込み、利用しなければならないこと。また、そのためにはシステム間連携をAPIを利用して整備するなど、システム開発そのものについても整備する必要があること。さらに、これらが24時間365日、安定して動き続けるためには、冗長性の設計などの高度なインフラ整備もこのタイミングで必要になることを指摘しました。
また、システムに組み込むことができたとしてもそれで完結することはできず、モデルの効果測定の枠組み(A/Bテストなど)や実装、そしてそれらについてのモニタリングについての仕組みまでが必要であり、これらがMLOpsの実際の姿であると結びました。
次に、MLOps NYで講演があったWalmartやNetflixなどの発表内容に基づき、これらの企業内にも上記のMLOps同等の仕組みがあることが示されました。例えばWalmartの場合、6〜8割のモデルが実装に頓挫(とんざ)しています。その原因となっているのも、データサイエンティストと、ビジネス側やITとの連携がうまくいかなかったことに原因があると紹介されました(図5)。

また、NetflixではMLOpsに必要な仕組みをMetaflowというオープンソースプロジェクトとして公開しています。加えて、「Strata Data Conference 2019 NewYork」というカンファレンスの会場で掲げられたJob board(求人ボード、図6)では、これらを担当する職種である「データエンジニア」が多く求められていることも、「MLOps=データサイエンティストがやらないこと全て」を担当できる技術者が求められていることの証しだといえます。

同じくMobility Technologies齋藤さんからは、実際に機械学習モデルを利用しているプロジェクトの事例として、「タクシーの到着時間予想」というテーマでの取り組みについてご紹介いただきました。齋藤さんは、Mobility Technologiesにてデータサイエンティストとデータエンジニアを兼務する形で働いており、生々しい技術的詳細までお話しいただきました。
到着時間予測プロジェクト(図7)は、Mobility Technologies社が提供しているJapanTaxi(ジャパンタクシー|旧:全国タクシー)のサービスにおいて、利用者がリクエストした乗車場所に基づいて割り当て可能なタクシーの探索を行うために利用するものであると同時に、利用者の画面には割り当てられたタクシーが乗車場に到着する時間を予測して表示するものです。

これらの表示機能は、利用者の利便性を高めるだけでなく、配車を効率的に行うことにも寄与しています。A/Bテストなどによる評価では、実際にユーザーのキャンセル率を1%低下させ、配車率においては20%増加させた、という驚きの成果を達成したそうです。
図8は、到着時間予測プロジェクトのシステム構成と処理プロセスのうち、データエンジニアが担当するプロセスです。

実際のシステム構成は、
(1)GCP(Google Cloud Platform)上のBigQueryからデータを抽出し
(2)AWS上のAmazon S3に一時保存、ここでデータのバージョン管理などを行い
(3)その後、AWS上のSageMakerでモデルを開発。なお、モデル開発を行ったコードについては、AWSのS3上に保存して再現性を担保すると同時に、バージョンを管理しています
(4)実際に予測を行った後には実績と評価するために出力はS3に保存しておく
など、モデルを運用するためのデータフローで必要としているコンポーネントの詳細を説明されました。
(5)作成したモデルの利用
においては、利用アプリケーションに対してAPIゲートウェイを用意し、AWS Lambdaを利用してリアルタイムな特徴量変換を介して利用しています(図9)。

齋藤さんは、
データサイエンティストはあくまで「サイエンティスト」であり、システム運用についてはあまり考えず、モデルの開発に注力すべきである。
そしてデータエンジニアは「エンジニア」の視点でシステム運用上から見たときに修正すべき点を洗い出し、そしてデータハンドリング含めて運用設計すべきである。
と結びました。
本講演はまさに、MLOpsとは「システム開発においてデータサイエンティストがやらないこと全て」を行うプロセスだということを、実例をもって示された内容でした。
MLOps ― 実装の現場から by Smart Analytics 畠さん
続いて、Smart Analyticsの畠さんがご登壇。ソフトウェアベンダーを渡り歩いてきた視点から、MLOpsについて俯瞰(ふかん)していただきました。
まず、「モデルの開発から運用までを通して考えるというのは、古くからある概念でもある」と指摘されました。現在、MLOpsと呼ばれているものは、かつてはDevOpsまたCRISP-DMといったフローで表されてきたものに近似しているという指摘です。
次に、「これまでの経験から、実態として運用されないモデルが多いのはなぜか」という点について考察を深められていきました。

MLOpsがうまくいかない原因として、図10のようなケースが取り上げられました。ここでは、データ準備の視点、モデリング上での問題点、そして組織上での活用の視点と、モデルが実運用されるに至っては多くの考慮点があるとまとめられています。
また、モデル活用の対象が人、モノ、カネと変わるにつれて、それぞれのフローでの問題点のあり方についても変わっているのが実情であると分析されました。機械学習を行うためのデータ準備については、多くの労力がかかるため、これまで多くが議論され、サポートするための多くの方法論、レシピが開発されてきたことを考えると、今後はモデルの運用についても方法論、ツールの整備が必要です。
図らずも渡部さんが紹介した「Netflixの試み」と合致することになった「MLOps分野におけるツール面での整備」ですが、気を付けなければならないこととして、日本的な業務プロセスの慣習が弊害になり得ることを指摘しました(図11)。ツール、方法論が標準化できたとしても、業務側がそのやり方に即する努力をしなければ、モデル運用は実現しないということです。

この課題を解決するためには、モデルの運用管理に必要なことを組織横断で俯瞰し、変えるべきものを変革することができるチームビルディングも技術的な解決以上に必要となると指摘しています。
むすびに
今回は、勉強会の終了後に多くの質問も寄せられ、オンラインとはいえ熱気のある勉強会を開催することができました。第2回勉強会では、今回の大規模勉強会から一転して、小規模なディスカッションセッションを予定しています。
面白い話を聞くためのイベントを開催するだけでなく、今後は教育を目的としたワークショップなどの幅広い活動も行うべく、「現在、MLOpsに必要とされていることは何なのか」を広い視点で捉えながら話し合い、今後の活動方針を決めていきたいと思っています。
MLOpsの今後に関して思いをお持ちの方は、第2回勉強会にぜひご参加ください! ご応募はこちらから:イベントページ
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。