Kaggleで学ぶ、モデルのブレンディングとスタッキング:僕たちのKaggle挑戦記(1/2 ページ)
Kaggle公式「機械学習」入門/中級講座の次は、本稿で紹介する動画シリーズで学ぶのがオススメ。記事を前中後編に分け、後編では交差検証を用いたモデルのスタッキングやブレンディングを試した体験を共有します。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
こんにちは、初心者Kagglerの一色です。昨日と今日で連日、本連載の記事を開いてくれてありがとうございます!
前々回と前回は、「筆者はどうやって『Titanicの次』に学ぶべき応用的な手法を次々と試せたのか」というテーマで、
- 前編(前々回)「Kaggleで学ぶ、k-fold交差検証と、特徴量エンジニアリング」:
- 交差検証(Cross Validation)のためにデータセットを加工
- さまざまな特徴量エンジニアリグやターゲットエンコーディングを試す
- 中編(前回)「Kaggleで学ぶ、Optunaによるハイパーパラメーター自動チューニング」:
- ハイパーパラメーターを自動チューニング
という記事を公開しました。引き続き同じテーマで、具体的には、
- 後編(今回):
- モデルのスタッキングや、それに類似のブレンディングという手法を試す
といった体験を共有します。冒頭は毎度同じ文章で恐縮ですが(※初見の読者のために記載しています)、この3本の記事を読めば、機械学習で精度を高めていくための、より現実的なステップについて知ることができると思います。少なくとも次に何を学ぶべきかの参考程度にはなるのではないかと思います。
詳しくは前々回書きましたが、前中後編の3本では、「Titanicの次」という初心者の壁を突き破る方法【第二弾】として、Abhishek Thakur氏によるYouTube動画「Kaggle's 30 Days of ML」を視聴することをオススメしています(関連:【第一段弾】)。動画は6本あり、そのPart-1〜3が前編、Part-4が中編、Part-5〜6が後編(今回)に対応してします。
筆者は各YouTube動画に1つずつ取り組んだ結果、Kaggleの公式プログラム“30 Days of ML”参加者限定の特別なコンペティション「30 Days of ML」の成績を着実に向上させることができました。

モデルのブレンディングやスタッキングで、コンペのランクも少し上がりました。本連載第2回で紹介したAzure AutoMLでもスタッキングされたモデルが約50個中の2位だったので、多くのケースで効果はかなり高いと思います。Kaggleのコンペでは試す価値がありますね。[一色]
それではさっそく、モデルのブレンディングやスタッキングの実体験を紹介していきます。今回も、筆者がYouTube動画を視聴しならがら試した体験内容を、読者の皆さんが追体験するイメージで書いていきます。ターゲットとなる読者は、Kaggle未経験者〜私と同じような初心者Kagglerを想定しています。
なお本稿のコードは、これまでの連載内容を踏まえた機械学習の実装全体をそのまま掲載しているので長めになっています。注目ポイントを太字にしていますので、太字に着目して他はざっと流し読みすることで、効率的に読んでいただけるとうれしいです。
4日目(Top 20%):モデルブレンディング
- モデルブレンディング(Model Blending)
を紹介していました。これはアンサンブル学習の一種です。
ブレンディング/スタッキングとは
アンサンブル学習(Ensemble Learning)とは、「複数のモデルによる各予測結果」をアンサンブルして(=組み合わせて)「最終的な1つの予測結果」を得るテクニックです。要するに、良いスコアが出たモデルの良いとこ取りをしようというわけです。Kaggleのような精度競争では非常に強力な武器となります。
アンサンブル学習については、前々々回も平均/投票について簡単に紹介しましたが、それらと本稿で紹介するブレンディング/スタッキングとの違いをあらためて説明しておきます。まとめると、以下のように定義できます。
- 平均(Averaging)法: 複数のモデルによる各予測結果を「平均」する方法(回帰の場合)
- 投票(Voting)法: 複数のモデルによる各予測結果で「多数決」(=「投票」)を取る方法(分類の場合)
- ブレンディング(Blending)法:
- 【Level 0】複数のモデルによる各予測結果を、
- 【Level 1】線形モデル(回帰の場合:線形回帰、分類の場合:ロジスティック回帰)などで「ブレンド」する方法
- スタッキング(Stacking)法:
- 【Level 0】複数のモデルによる各予測結果で、
- 【Level 1】複数の新たなモデルを構築し、その予測結果を、
- 【Level 2】線形モデル(回帰の場合:線形回帰、分類の場合:ロジスティック回帰)などでブレンドするという形で、
- Level 0〜2の3層を「スタッキング」する(=積み重ねる)方法(※中間のLevel数はもっと増やすことも可能)
平均/投票がシンプルな算術計算でアンサンブルするのに対し、ブレンディングでは統計/機械学習モデル(一般的には線形モデル)でアンサンブルするという違いがあります。つまりブレンディングの方がより効果的なアンサンブルになるケースが多いでしょう。
ブレンディングとスタッキングは、上記の定義を見ると分かるように、Level数が異なるだけでほぼ同じものです。スタッキングとは、3層以上のLevel数でブレンディングをブレンドしていくこと、と言い換えることもできますね。
ちなみに「ブレンディング」は、主にKaggleのようなコンペティションで使われる(学術的というよりも)口語的な用語で、シンプルな(=Level 0〜1など2層の)スタッキング構造を意味しています(※ゆえに2層でも「スタッキング」と呼ばれることはあります)。この言葉が注目されて使われるようになったのは、2008年に開催された「Netflix Prize」というコンペで100万ドルの賞金を獲得した解法(Solution)が、さまざまな100以上のモデルを「ブレンド」したものだったからと言われています(参考:2008年の論文「The BellKor 2008 Solution to the Netflix Prize」)。翌2019年の「Netflix Prize」で人気のテクニックとなり、その優勝者の解法は複数のLevelでのブレンディング、つまりスタッキングでした(参考:2009年の論文「Feature-Weighted Linear Stacking」)。
以上が、広義のブレンディング/スタッキングの定義となります。しかし、具体的な応用法に限定した狭義の定義もあり、ブレンディング/スタッキングの違いとしては、むしろその用例で説明されていることがよくあります(※そのため、「ブレンディング」と言った場合に、人によって指す内容が広義の意味か狭義の意味かで異なる可能性があるので注意してください)。そこで、ここでも狭義の定義を紹介しておきます。
- ブレンディング: 「ホールドアウト法」(データを固定的に訓練データと検証データに分割する方法。なおテストデータは別に取っておく)により固定的に分割した検証データ*1を、Level 0での複数のモデルに入力して予測する。その他は上記の定義と同じ
- スタッキング*2: 「k-fold交差検証」(前々回の解説)で分割したフォールド(fold)ごとに各検証データを、Level 0での複数のモデルに入力して予測する*3。その他は上記の定義と同じ
*1 現在は、削除されてしまっていてソースを確認できませんが、「mlwave: Kaggle Ensembling Guide」というドキュメントには、「データの10%などで小さなホールドアウト・セット(=検証データ)を作成する」と記載されていました(残りの約90%が訓練データになります)。
*2 スタッキングアンサンブルは、少し古い呼び方でStacked Generalization(スタックによる一般化)とも呼ばれます(参考:1992年の論文「Stacked generalization」)。
*3 交差検証における、フォールドごとの検証データを使った各予測(結果)は、Out-of-Fold Predictionsとも呼ばれます。この名称はよく使われていますので、覚えておいた方がよいです。
上記の違いのポイントは、スタッキングがフォールドごとの検証データを予測に用いる(※フォールドを切り替える結果、全ての検証データ分→全データが使われる)のに対し、ブレンディングは固定的に分割した検証データしか予測に使わないという点です。
適切にk-fold交差検証できる状況(=前々回説明した「リーク:Data Leakage」を起こさないよう細心の注意で分割データを活用できる状況)で、「データ量があまりにも膨大で交差検証だと計算時間がかかりすぎる」というわけでもないなら、狭義のブレンディングよりも広義のブレンディングもしくはスタッキングを採用した方がいいよね、と思った。
さて、前置きはこれくらいにして、モデルブレンディングの実装体験を説明していきます。なお本稿で実装する「ブレンディング」は、狭義のホールドアウト法ではなく、k-fold交差検証したデータセットを使った広義のブレンディングを指すこととします。
モデルブレンディングの構成について
実装に入る前に、全体構成について示しておきます。
なお、ブレンディング/スタッキングにおける「モデル」には、下記の2種類があります。以下ではこれらの用語を使って説明していきます。
- ベースモデル(Base Model): さまざまな複数の機械学習モデル、つまり上記のLevel 0で作成したモデルのこと
- メタモデル(Meta Model): 複数のモデルによる各予測結果を用いて訓練された新たな上位モデルのことで、つまり上記のLevel 1やLevel 2で作成したモデルのこと
ここでのブレンディングでは、「Level 0」と「Level 1」の2層の構成になるように、以下の手順でモデルやデータセットを作成していきます。
- Level 0層: ベースとなる、複数(今回は5つ)の機械学習モデルを作成
- Level 0→1の間: ベースモデルによる予測結果から新たなデータセット(訓練/検証/テスト)を作成
- Level 1層: 最終的な予測を行うための、1つのメタモデルを作成
この構成と流れを図にすると、図1のようになります。下から上に積み上げる形で図を描きました。


この図でかなりいろいろと分かった気がします(何をや)。[かわさき]
それでは、Level 0層から実装していきましょう。
[Level 0]ベースとなる、複数の機械学習モデルを作る
まずは、性能(=精度)が高くなりそうな機械学習の手法を用いて、ベースとなるモデルを複数作ります。筆者の場合は、以下の5つを作りました。
- [Level 0]モデル1: XGBoost(ターゲットエンコーディングのバージョン)
- [Level 0]モデル2: ランダムフォレスト
- [Level 0]モデル3: XGBoost(標準化のバージョン)
- [Level 0]モデル4: XGBoost(多項式と交互作用の特徴量のバージョン)
- [Level 0]モデル5: XGBoost(ワンホットエンコーディングのバージョン)
いずれもこれまでの連載で書いた内容で作れるモデルです。前々回紹介した1位の解法では、XGBoost/CatBoost/HistGradientBoostingRegressorなど多様な手法が使われていました。こういった多様な手法の知識も、Kaggleや機械学習の精度向上には欠かせないかなと思います。エンコーディングも変数ごとに細かく行った方がよいのですが、ここでは全ての数値変数とカテゴリー変数に同じエンコーディングを施しました。
実際に機械学習モデルを作るコードの説明に入る前に、前提条件となる「事前の実装」について知っておく必要があります(※長くなってしまうので、コードの再掲は行いません)。
- 「k-fold交差検証用に、新たな訓練&検証データセット」(train_folds.csvファイル)を作成しました。このデータセットは、「元々の訓練&検証データセット」(train.csvファイル)に[kfold]列を追加し、そこに0〜4という各フォールド(fold:分割)のインデックス番号を格納したものです。詳しくは、前々回の「リスト1 交差検証用に5分割したデータセットを作成してCSVファイルに保存」を参照してください。
- 「機械学習モデルごとに、ハイパーパラメーターのチューニング」を行いました。詳しくは、前回の「リスト2 Optunaを使って最適なハイパーパラメーターを探索するコード」を参照してください。前回のコードに従うと、study.best_paramsプロパティにより、最良の性能(=精度)だった試行の各パラメーター値を辞書形式で取得できますが、今回は変数paramsに辞書型でパラメーター名と値を直書きすることにします。
機械学習モデルを作るコード(リスト1)の書き方は、基本的に前々回の「リスト2 5フォールドの交差検証を行いながらXGBoostモデルを作成するコード例」と同じです。違うのは、検証データとテストデータで予測して、それを保存する点です。下記のリスト1のコードだけ見ると長くて難解に思えるかもしれませんが、実際には特に難しいメソッドやロジックは使っていません。今回のポイントである太字部分に着目してください。
# [Level 0]ベースモデル3: XGBoost(標準化のバージョン)
import numpy as np
import pandas as pd
from sklearn.preprocessing import OrdinalEncoder, StandardScaler
from sklearn.metrics import mean_squared_error
from xgboost import XGBRegressor
# 事前にハイパーパラメーターのチューニングをしておく(参考:前回のリスト3)
# params = study.best_params
params = {
'learning_rate': 0.02164416532115273,
'reg_lambda': 1.5360131023800562e-08,
'reg_alpha': 16.67878863017435,
'subsample': 0.7586782390870352,
'colsample_bytree': 0.13555581566462735,
'max_depth': 4,
'min_child_weight': 16
}
# 「5分割済みの訓練&検証データ」と「テストデータ」のロード
df_train = pd.read_csv('../input/30days-folds/train_folds.csv')
df_test = pd.read_csv('../input/30-days-of-ml/test.csv')
# サンプルのSubmission用ファイルもロード
df_sample_submission = pd.read_csv('../input/30-days-of-ml/sample_submission.csv')
# 利用する特徴量の選択
useful_features = [c for c in df_train.columns if c not in ('id', 'target', 'kfold')]
# カテゴリ変数と数値変数の選択
categorical_cols = [c for c in useful_features if df_train[c].dtype == 'object']
numerical_cols = [c for c in useful_features if df_train[c].dtype in ['int64', 'float64']]
valid_scores = [] # 「検証データに対する評価スコア」を保存する変数
valid_predictions = {} # 「検証データに対する予測結果」を保存する変数
test_predictions = [] # 「テストデータに対する予測結果」を保存する変数
for fold in range(5):
X_train = df_train[df_train.kfold != fold].reset_index(drop=True)
X_valid = df_train[df_train.kfold == fold].reset_index(drop=True)
X_test = df_test.copy()
# 検証データのIDを保存しておく
valid_ids = X_valid.id.values.tolist()
y_train = X_train.target
y_valid = X_valid.target
X_train = X_train[useful_features]
X_valid = X_valid[useful_features]
X_test = X_test[useful_features]
ordinal_encoder = OrdinalEncoder()
X_train[categorical_cols] = ordinal_encoder.fit_transform(X_train[categorical_cols])
X_valid[categorical_cols] = ordinal_encoder.transform(X_valid[categorical_cols])
X_test[categorical_cols] = ordinal_encoder.transform(X_test[categorical_cols])
scaler = StandardScaler()
X_train[numerical_cols] = scaler.fit_transform(X_train[numerical_cols])
X_valid[numerical_cols] = scaler.transform(X_valid[numerical_cols])
X_test[numerical_cols] = scaler.transform(X_test[numerical_cols])
# XGBoost(標準化のバージョン)モデルの訓練(fit)
model = XGBRegressor(
#n_jobs=-1, # CPUを使う場合
tree_method='gpu_hist', gpu_id=-1, predictor='gpu_predictor', # GPUを使う場合
random_state=24,
n_estimators=10000,
**params)
model.fit(
X_train, y_train,
early_stopping_rounds=300, eval_set=[(X_valid, y_valid)],
verbose=1000)
# 検証データをモデルに入力して予測する
preds_valid = model.predict(X_valid)
# 検証データのIDと、それに対する予測値をセットで、ループ外の変数に保存する
valid_predictions.update(dict(zip(valid_ids, preds_valid)))
# 「検証データに対する評価スコア」を取得してループ外の変数に保存し、スコアを出力
score_valid = mean_squared_error(y_valid, preds_valid, squared=False)
valid_scores.append(score_valid)
print(fold, score_valid)
# 出力例: 0 0.7169737498911609
# 同様に、テストデータをモデルに入力して予測する
preds_test = model.predict(X_test)
# 予測結果をループ外の変数に保存
test_predictions.append(preds_test)
# 5回分の「検証データによる評価スコア」を平均する
score_validation = np.mean(valid_scores)
print('score_validation:', score_validation)
# 出力例: score_validation: 0.7255378561950397
# 「検証データに対する予測結果」をCSVファイルに保存
valid_predictions = pd.DataFrame.from_dict(valid_predictions, orient='index').reset_index()
valid_predictions.columns = ['id', 'pred_3'] # 列名を[id]と[pred_3]にする
valid_predictions.to_csv('valid_preds3.csv', index=False)
# 5回分の「テストデータに対する予測結果」を平均し、それをCSVファイルに保存
X_sample_submission = df_sample_submission.copy()
X_sample_submission.target = np.mean(np.column_stack(test_predictions), axis=1)
X_sample_submission.columns = ['id', 'pred_3'] # 列名を[id]と[pred_3]にする
X_sample_submission.to_csv('test_preds3.csv', index=False)
リスト1で出力している2つの「予測結果のCSVファイル」(検証データに対する予測結果:valid_preds3.csv、テストデータに対する予測結果:test_preds3.csv)の中身は、図2のように[id](ID)列と[pred_3](予測値)列の2列だけになります。後述の手順でID番号を手掛かりにマージするため、[id]列は不可欠かつ重要です。
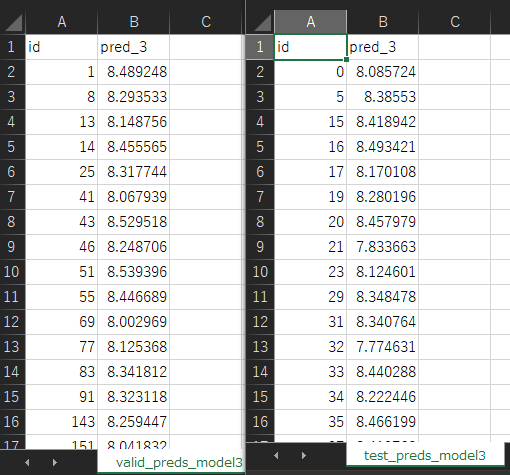 図2 検証データ(左)とテストデータ(右)での予測結果を保存したCSVファイル
図2 検証データ(左)とテストデータ(右)での予測結果を保存したCSVファイルなお、列名が[pred_3]と3なのは、リスト1が前述の「モデル3」に当たるコードだからです。リスト1と同じように、モデル1〜5ごとにCSVファイルを作成していき、列名も[pred_1]〜[pred_5]のように命名します。
以上が、Level 0層のベースモデルの作成になります。
[Level 0→1]予測結果から新たなデータセットを作る
Level 1層のメタモデルを作る前に、そのモデルに入力するためのデータセットを作る必要があります。このデータセットは、先ほど作成したベースモデルの予測結果から作成します。
上記の手順に従うと、
- 【モデル1】検証データ:valid_preds1.csv、テストデータ:test_preds1.csv
- 【モデル2】検証データ:valid_preds2.csv、テストデータ:test_preds2.csv
- 【モデル3】検証データ:valid_preds3.csv、テストデータ:test_preds3.csv
- 【モデル4】検証データ:valid_preds4.csv、テストデータ:test_preds4.csv
- 【モデル5】検証データ:valid_preds5.csv、テストデータ:test_preds5.csv
という10個の予測結果のCSVファイルが作成されています。
まずは、このうちの5つの「検証データに対する予測結果」のCSVファイルをマージして、新しい1つの訓練&検証データを作成します。それぞれのCSVファイルの列項目は次のようになっています。
- valid_preds1.csv: [id, pred_1]
- valid_preds1.csv: [id, pred_2]
- valid_preds1.csv: [id, pred_3]
- valid_preds1.csv: [id, pred_4]
- valid_preds1.csv: [id, pred_5]
ただし、マージ先は元々の「5分割済みの訓練&検証データ」(=リスト1や後述のリスト2で記述した変数df_trainに格納されているデータ)にしましょう。というのも、このdf_train(pandasデータフレーム)の[kfold]列に、交差検証のフォールドインデックスが格納されているからです。k-fold交差検証したデータセットを使った広義のブレンディングやスタッキングでは、各Levelにある各モデル間でも訓練&検証データのフォールド(=分割)を一致させる方が無難です(※リークの危険性を可能な限り減らすため。ちなみに『Kaggle Grandmasterに学ぶ 機械学習 実践アプローチ』でもその方法が解説されています)。[id]列の値(ID)を手掛かりに[pred_1]〜[pred_5]列をマージしていくことで、「フォールド(=分割)を一致させる」ことを実現します。先ほど「[id]列は不可欠かつ重要」と記載したのはこのためです。
なお、このdf_trainには全ての列情報が含まれておりムダが多いように思えますが、問題ありません。大は小を兼ねる的な考え方で、実際にデータを使用する場面で「必要な列だけを絞り込んで使用する」ことにします。
ここまでが、次のLevel用に新しい1つの訓練&検証データを作成する処理の流れです。
次に、5つの「テストデータに対する予測結果」のCSVファイルをマージして、1つの新しいテストデータを作成します。とはいえ、先ほどと同様の処理の流れになるので、説明は省略します。
ここまでの処理を行っているコードがリスト2です。
import pandas as pd
# 「5分割済みの訓練&検証データ」と「テストデータ」のロード
df_train = pd.read_csv('../input/30days-folds/train_folds.csv')
df_test = pd.read_csv('../input/30-days-of-ml/test.csv')
# 検証データに対する、5つのモデルによる予測結果のCSVファイルをロード
valid_preds1 = pd.read_csv('valid_preds1.csv')
valid_preds2 = pd.read_csv('valid_preds2.csv')
valid_preds3 = pd.read_csv('valid_preds3.csv')
valid_preds4 = pd.read_csv('valid_preds4.csv')
valid_preds5 = pd.read_csv('valid_preds5.csv')
# 5分割済みの訓練&検証データに、5つのモデルによる予測値をマージ
df_train = df_train.merge(valid_preds1, on='id', how='left')
df_train = df_train.merge(valid_preds2, on='id', how='left')
df_train = df_train.merge(valid_preds3, on='id', how='left')
df_train = df_train.merge(valid_preds4, on='id', how='left')
df_train = df_train.merge(valid_preds5, on='id', how='left')
print(df_train.head()) # 後掲の図3がその出力例
# テストデータに対する、5つのモデルによる予測結果のCSVファイルをロード
test_preds1 = pd.read_csv('test_preds1.csv')
test_preds2 = pd.read_csv('test_preds2.csv')
test_preds3 = pd.read_csv('test_preds3.csv')
test_preds4 = pd.read_csv('test_preds4.csv')
test_preds5 = pd.read_csv('test_preds5.csv')
# テストデータに、5つのモデルによる予測値をマージ
df_test = df_test.merge(test_preds1, on='id', how='left')
df_test = df_test.merge(test_preds2, on='id', how='left')
df_test = df_test.merge(test_preds3, on='id', how='left')
df_test = df_test.merge(test_preds4, on='id', how='left')
df_test = df_test.merge(test_preds5, on='id', how='left')
print(df_test.head()) # 後掲の図4がその出力例
# 必要な列だけを絞り込んで使う例
useful_features = ['pred_1', 'pred_2', 'pred_3', 'pred_4', 'pred_5']
train_sel = df_train[useful_features]
test_sel = df_test[useful_features]
print(test_sel.head()) # 後掲の図5がその出力例
リスト2ではmerge()メソッドでマージして新しいデータセットを作成し、これまでと同様にuseful_featuresというリストで絞り込みを行っています。難しいところはないと思います。
リスト2を実行した結果、print()関数により出力されたのが、図3、図4、図5です。



確かに、df_train(=5分割済みの訓練&検証データ)やdf_test(=テストデータ)に[pred_1]〜[pred_5]列がマージされており、useful_featuresリストにより変数train_selやtest_selに必要な列だけを絞り込むこともできていますね。
ここで参考までに、予測結果の一つである[pred_3]列のヒストグラムを表示して(リスト3)、その分布を確認してみましょう(図6)。
test_sel.pred_3.hist()
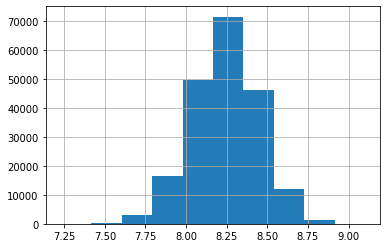 図6 ヒストグラムの表示結果
図6 ヒストグラムの表示結果図6を見ると、正規分布に近い山形のきれいな予測結果となっていることが分かります。
[Level 1]最終となる、1つのメタモデルを作る
最後に、Level 1層のメタモデルを作成します。
といっても、既に新たなデータセットを準備済みで、基本的な機械学習モデルの構築方法は、先ほど見たリスト1などとほぼ同じです。違いは、scikit-learnのLinearRegressionという線形回帰クラスを使用している点くらいです(リスト4の太字部分)。なお、線形モデルが必須というわけではなく、ここでリスト4と同じXGBRegressorクラスなど他の機械学習手法を用いても問題はありません。
# [Level 1]最終メタモデル: 線形回帰
import numpy as np
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
# 新しい「5分割済みの訓練&検証データ」と「テストデータ」のロード
# は、前掲のリスト2で実行済み。
# サンプルのSubmission用ファイルもロード
df_sample_submission = pd.read_csv('../input/30-days-of-ml/sample_submission.csv')
# 利用する特徴量の選択
useful_features = ['pred_1', 'pred_2', 'pred_3', 'pred_4', 'pred_5']
valid_scores = [] # 「検証データに対する評価スコア」を保存する変数
test_predictions = [] # 「テストデータに対する予測結果」を保存する変数
for fold in range(5):
X_train = df_train[df_train.kfold != fold].reset_index(drop=True)
X_valid = df_train[df_train.kfold == fold].reset_index(drop=True)
X_test = df_test.copy()
y_train = X_train.target
y_valid = X_valid.target
X_train = X_train[useful_features]
X_valid = X_valid[useful_features]
X_test = X_test[useful_features]
# 線形モデルの訓練(fit)
model = LinearRegression()
model.fit(X_train, y_train)
# 検証データをモデルに入力して予測する
preds_valid = model.predict(X_valid)
# 「検証データに対する評価スコア」を取得してループ外の変数に保存し、スコアを出力
score_valid = mean_squared_error(y_valid, preds_valid, squared=False)
valid_scores.append(score_valid)
print(fold, score_valid)
# 出力例: 0 0.7169737498911609
# 同様に、テストデータをモデルに入力して予測する
preds_test = model.predict(X_test)
# 予測結果をループ外の変数に保存
test_predictions.append(preds_test)
# 5回分の「検証データによる評価スコア」を平均する
score_validation = np.mean(valid_scores)
print('score_validation:', score_validation)
# 出力例: score_validation: 0.7175808541640771
# 5回分の「テストデータに対する予測結果」を平均し、それをCSVファイルに保存
X_sample_submission = df_sample_submission.copy()
X_sample_submission.target = np.mean(np.column_stack(test_predictions), axis=1)
# 列名は[id]と[target]のまま、コンペにSubmisison用のファイルを作成する
X_sample_submission.to_csv('submission.csv', index=False)
print(X_sample_submission.head())
# 出力例:
# id target
# 0 0 8.088913
# 1 5 8.399929
# 2 15 8.410170
# 3 16 8.517239
# 4 17 8.159943
以上が交差検証を用いた(広義の)モデルブレンディングです。機械学習モデルを何個も作ることになるので、コードは非常に長くなっていますが、やっていること自体はそれほど難しくありません。
個人的な体感からも、ブレンディングやスタッキングは構造が多層で多数のステップがあるので、文章ではイメージが湧きにくく、なかなか理解できないような感覚に陥るのではないかと思います。わたしの場合は、文章ではなかなかスッキリしませんでしたが、コードを書いてみることでかなりスッキリと理解できました。上記のブレンディングがあまりよく分からなかったという人は、実際に手を動かしてコードを書いてみることを強くお勧めします。
手を動かすのは大事ですよねー。でも、似たようなことを何度もやることになりそうなので、コードの共通化とかを考えるのが大事になるのかもしれませんね。
ホールドアウト法を用いたモデルブレンディングについて
YouTubeの動画にはありませんが、ホールドアウト法を用いた狭義のブレンディングについても簡単に触れておこうと思います。
とはいえ、コードなどは広義のブレンディングとほとんど変わりません。変わるのは、交差検証用にデータセットを複数に分割(今回は5分割)するのではなく、scikit-learnのtrain_test_split(X, y, test_size=0.1, random_state=42)関数を使うなどして10%を検証データに分割することなどです(残りの約90%が訓練データになります)。交差検証しないので、for fold in range(5):といった形でフォールド(分割)を変えながらループ処理するコードも不要になります。
というわけで、これまでのコードよりもむしろ簡単になります。よって詳しい説明も割愛します。興味がある人は、上の段落の説明を参考に自分でコードを書き直してみてください。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。