テキストから「3D画像」生成、Googleなどが開発したAI「DreamFusion」の仕組みとは:トレーニング用3Dデータが不要な手法を開発
Google Researchとカリフォルニア大学バークレー校の研究チームは、テキストから3次元(3D)オブジェクトを生成するAI「DreamFusion」を開発した。2次元(2D)拡散モデルを用いる。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
Google Researchとカリフォルニア大学バークレー校からなる研究チームは、入力されたテキストから3次元(3D)オブジェクトを生成するAI「DreamFusion」を開発した。2次元(2D)拡散モデルを用いる。2022年9月29日(米国時間)、このAIに関する論文をオープンアクセスリポジトリ「arXiv」に提出した。論文は同日から公開されている。
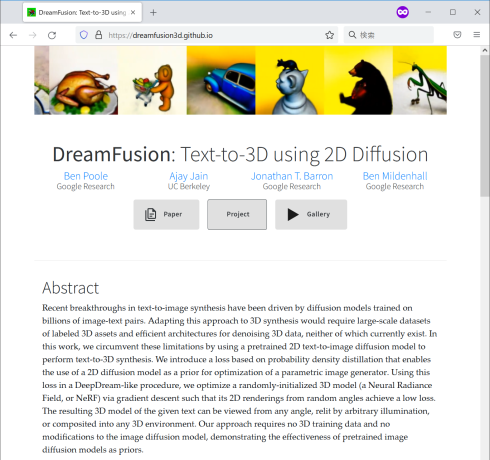
テキストから2D画像を生成するAIの最近のブレークスルーは、何十億もの画像とテキストのペアでトレーニングされた拡散モデル(diffusion model)によってもたらされた。拡散モデルは、純粋なノイズから少しずつノイズを除去していき、最終的に何らかの画像を得るという考え方に基づいている。
このアプローチを3D画像の生成に適用するには、ラベル付けされた3D資産の大規模データセットと、3Dデータの効率的なノイズ除去アーキテクチャが必要だが、どちらも2022年9月末時点では存在しない。
ではどうやって3D画像を生成するのか
研究チームはこの制約を回避するために、テキストから画像を生成するトレーニング済みの2D拡散モデルを用いて、テキストから3D画像を生成するアプローチを採用し、DreamFusionを開発した。このアプローチでは、「確率密度蒸留」に基づく損失を導入する。確率密度蒸留はパラメトリック画像生成の最適化のために、2D拡散モデルを事前に使用することを可能にするものだ。
研究チームは、Googleのコンピュータビジョンプログラム「DeepDream」のような手順でこの損失を使用し、ランダムに初期化された3Dモデル(NeRF:Neural Radiance Field)を勾配降下法によって最適化することで、ランダムな角度からの2Dレンダリングが低損失となるようにした。その結果、与えられたテキストの3Dモデルを、任意の角度から見たり、任意の照明で照らしたり、任意の3D環境に合成したりすることが可能になった。
このアプローチに従うと、トレーニング用の3Dデータや画像拡散モデルの改変が不要になり、トレーニング済み画像拡散モデルの事前使用の有効性を実証していると、研究チームは述べている。
 テキスト入力から生成した3D画像の例 どの方向から見ても自然な3D画像が生成されている。テキストが与えられると、DreamFusionが高い忠実度を備えた外観、奥行き、法線を持ち、再照明可能な3Dオブジェクトを生成する。オブジェクトはNeRFとして表現され、テキストから画像を生成するトレーニング済み拡散モデルを事前に利用する(クリックで再生、提供:Google)
テキスト入力から生成した3D画像の例 どの方向から見ても自然な3D画像が生成されている。テキストが与えられると、DreamFusionが高い忠実度を備えた外観、奥行き、法線を持ち、再照明可能な3Dオブジェクトを生成する。オブジェクトはNeRFとして表現され、テキストから画像を生成するトレーニング済み拡散モデルを事前に利用する(クリックで再生、提供:Google)DreamFusionはどのように動作するのか
入力テキストが与えられると、DreamFusionは、テキストから画像を生成するモデル「Imagen」を用いて、3Dシーンを最適化する。研究チームは、損失関数を最適化することで拡散モデルからサンプルを生成する方法の一つ「Score Distillation Sampling」(スコア蒸留サンプリング:SDS)を提案している。
SDSでは、画像に微分的にマップバックできる限り、3D空間のような任意のパラメーター空間においてサンプルを最適化できる。研究チームはこの微分可能なマッピングを定義するために、NeRFに似た3Dシーンパラメーター化を使用している。
SDSは単独で、シーンの理にかなった外観を生成するが、DreamFusionは正規化と最適化によって形状を改善する。その結果、トレーニングされたNeRFはコヒーレントなものになり、高品質な法線、表面形状、奥行きを持ち、ランバートシェーディングモデルによって再照明が可能になった。
 DreamFusionの仕組みを説明する動画(クリックで再生、提供:Google)
DreamFusionの仕組みを説明する動画(クリックで再生、提供:Google)DreamFusionのプロジェクトページでは、DreamFusionの機能を示す次のようなインタラクティブなサンプルが掲載されている。
・リスの3D画像について、「何をしているのか」「何を着ているのか」「木の彫刻か、金属の彫刻か」を記述したさまざまなテキストリンクが用意されており、クリックに応じて画像が変わる
・DreamFusionで生成された3Dオブジェクトのギャラリー(テキスト検索可能)
・8種類の3Dモデルが用意され、それぞれロードして、マウス操作によってさまざまな角度から見ることができる
関連記事
 誰もが知っておくべき画像生成AI「Stable Diffusion」の仕組みと使い方
誰もが知っておくべき画像生成AI「Stable Diffusion」の仕組みと使い方
Stable Diffusionの概要と基本的な仕組み、それを簡単に使うための公式なWebサービスである「DreamStudio」を紹介し、Stable Diffusionで画像生成する際に行われていることについて駆け足で見ていきましょう。 「Stable Diffusion」でノイズから画像が生成される過程を確認しよう
「Stable Diffusion」でノイズから画像が生成される過程を確認しよう
ホントにノイズからノイズを除去していくとキレイな画像が生成されるのか。これを今回は自分の目で確認してみましょう。 無料で誰でも簡単に、テキストから画像を生成できる「Craiyon(旧名:DALL・E mini)」を使ってみよう
無料で誰でも簡単に、テキストから画像を生成できる「Craiyon(旧名:DALL・E mini)」を使ってみよう
テキストプロンプト(文章)から画像を生成するAIサービス「craiyon.com」。その概要と使い方、サンプル実行例のギャラリーに加えて、「どういった文章を入力すればよいか?」や「生成した画像は使ってもいいのか?」といった気になる点も紹介する。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。