誰もが知っておくべき画像生成AI「Stable Diffusion」の仕組みと使い方:Stable Diffusion入門
Stable Diffusionの概要と基本的な仕組み、それを簡単に使うための公式なWebサービスである「DreamStudio」を紹介し、Stable Diffusionで画像生成する際に行われていることについて駆け足で見ていきましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
今、画像生成AIが「革命」と言えるほど盛り上がっているのをご存じでしょうか。2022年8月前後 からDALL・E 2(ダリ・ツー)やImagen(イマジェン)、それからもちろんMidjourney(ミッドジャーニー)など、多数の画像生成系AIが登場し、世の中を騒然とさせていました。が、それらを一足飛びで追い越して多くの人が熱中しているのがStable Diffusion(ステーブルディフュージョン)です。最初はSNSで大きな話題となりましたが、2022年9月ではテレビで紹介されるまでになっています。
特にStable Diffusionは、「誰もが必ず知っておくべき」重要なAIだと、Deep Insider編集部では考えており、この「Stable Diffusion入門」連載を企画しました。本連載では、AI/機械学習エンジニアやデータサイエンティストや、最新の話題が好きな人ではなく、「今、画像生成AIがはやっているみたいだけど、何ができて、何がすごいのかよく分からない」という普通の人に向けて、Stable Diffusionの概要と基本的な仕組み、それを簡単に使うためのサービスなどをできるだけ分かりやすくコンパクトに紹介していきます。一部の説明では、Pythonというプログラミング言語を使ったコードによる説明も行っていますが、分からない部分はスキップして読んでも大丈夫です。
Stable Diffusionって?
これらの画像生成系AIに共通するのは、プロンプトとか呪文とか呼ばれるテキストを入力することで、高解像度のグラフィックが生成されることです。このプロンプトをどう工夫すれば、生成される画像をよりよいもの(ユーザーが望む理想に近いもの)をできるかに興味を持つ人も多く、「プロンプトエンジニアリング」と呼ばれる分野があっという間に確立されてもいます。呪文の詠唱の仕方を変えることで、その効果をビジュアルに確認できることが人々のハック魂に火を付けたともいえるでしょう。

その一方で、上に挙げたような高精度な画像生成AIが多数登場したことで「イラストレーターの仕事はなくなってしまうのか」とか「AIが生成した画像の著作権はどうなってんの」とか「自分の絵を勝手に学習に使われたくない」などの観点から議論が巻き起こってもいます。特にStable Diffusionはソースコードが公開されていることから画像生成AIとユーザーとの距離がグッと近づいた結果、こうした問題も多くの人にとって身近なものになったといえるでしょう。実際、Stable Diffusionのソースコードが公開された後は、これをベースとした多くのサービスやアプリがこれでもかというほど、一気に登場していますよね。

が、こうした点については本連載では取り上げずに、あくまでも「Stable Diffusionとは?」「試してみるには?」「コードを書いてみたい」といった観点で話をしていくことにします(かわさき)。

私は「Stable Diffusion登場前と後で世の中は変わってしまった」と考えています。それほどStable Diffusionの登場はAIの歴史の中で重要な出来事で、だからこそ「誰もがStable Diffusionのことを知っておくべきだ」と考えています。世の中には既に、Stable Diffusionの概要や、画像生成例、呪文の書き方などを書いたブログ記事が毎日のように多数出てきています。この連載は、そういったバラバラの情報が1本の連載の中でまとめられており、誰もが基礎から学べるもの、いわゆる教科書みたいなものになればよいなと思っています。そういうまとまったものが必要ですよね?
なお、「変わってしまった」とそこまで強く主張する理由は、Midjourneyまではソースコードが非公開でしたが、Stable Diffusionはオープンソースだからです。しかもStable Diffusionの方が高性能という話もあります。オープンソースということは、誰もが手元で使えるようになったということです。私の目には、Stable Diffusionを基点にさまざまな企業や人がこの技術を使って何かしらのサービスを作ったりしてさらに発展していくように映りました。覆水盆に返らず。始まった大きなうねりはもう止められない、というのが主張の理由です(一色)。
最初に述べておきたいことは、Stable Diffusionとは「画像を生成するための訓練済みのモデル」であるということです。極端なことをいえば、モデルを使う上ではその詳細な理解は(とてもありがたいことに)必要ないともいえます。Webサイトが提供しているサービスを利用したり、ローカルPCやGoogle Colab上の環境にモデルをインストールしてスクリプトを実行したりプログラムコードを記述/実行したりすることで、多くの人が比較的簡単にその恩恵にあずかれるということです。
使う分には知っておく必要はありませんが、中の仕組み、アーキテクチャーについても簡単に触れておきます。その後で使い方について紹介します。
今も述べたようにStable Diffusionは訓練済みモデルなのですが、このモデルは「潜在拡散(latent diffusion)」と呼ばれるアルゴリズムを実装したものです。ちなみに「潜在拡散モデル」はその前身ともいえる「拡散モデル(diffusion model)」と呼ばれるモデルをより効率的にしたものと考えられます(ちなみに最初に述べたAIの多くも拡散モデル/潜在拡散モデルの系譜に連なるものです)。
「潜在拡散」など、仕組みの話は何やら難しそうな単語が出てきますね。「難しくて理解できない」と思ったらスキップして大丈夫だと思います。後で出てくるVAEというのは機械学習のモデルアーキテクチャーの一つで専門用語になります。
拡散モデルと潜在拡散モデルはどちらも基本的な考え方は同じです。つまり、「純粋なノイズから少しずつノイズを取り除いていくことで、最終的に何らかの画像を得る」というものです。

これを行うには、モデルは実際の画像に少しずつノイズを付加しながら最終的に純粋なノイズ(ガウシアンノイズ)を得る過程(順方向の拡散プロセス)を基に、その逆に純粋なノイズから少しずつノイズを除去しながら最終的に元の画像を得る過程(逆方向の拡散プロセス)において、どんなノイズを純粋なノイズから除去していけば画像を得られるか(画像を生成できるか)を学習する必要があります。つまり、拡散モデル/潜在拡散モデルはこの除去されるノイズを推測し、初期値となるガウシアンノイズ(とは元の画像にノイズを適用して最後に得られたガウシアンノイズでもあります)から、逆方向の拡散プロセスの各ステップで推測したノイズを徐々に除去していき、最終的に何らかの画像を生成するものです。
拡散モデルではピクセル空間を直接操作して、この処理を実現していましたが、これは多くの計算資源を必要として、訓練や推測にも時間がかかるという弱点がありました。そこで、潜在拡散モデルではVAEでおなじみの潜在空間を用いることでこの弱点を克服し、より効率的に(訓練と)推測を行えるようにしたものといえます。
なぜ「(訓練と)」がかっこ付きかといえば、Stable Diffusionは訓練済みのモデルなので、モデルを利用するだけであれば訓練の部分はあまり関係ないからです。
というのが、Stable Diffusionの概要となるのですが、先ほどもいったように使う分にはこんなことは知っている必要はないといえばないのです。そこで、次にこれを実際に試してみることにしましょう。
Stable Diffusionを試してみたい
Stable Diffusionを実際に試してみたいという場合、大きく分けて以下の2つのやり方があります。
- 多数のWebサイトやアプリケーションがサービスを提供しているのでそれらを使用する
- 手元のPCやクラウド上のノートブック環境(Google Colabなど)でStable Diffusionをインストールしてコマンドラインでプロンプトを入力したり、プログラムコードを書いたりする
前者の方法としては以下のようなものがあります(後者については次回に試してみることにしましょう)。他にも同様なサービスやアプリは多数あるので、これらはあくまでも代表的なものでしかありません。
Hugging Faceで提供されているStable Diffusionのデモページは以下のようにとてもシンプルで、テキストボックスにプロンプトを入力して[Generate Image]ボタンをクリックするだけで画像が生成されます。

ただし、画像が生成されるまでの待ち時間が長くなることもありますし、画像の大きさや最終的な画像を生成するまでに上で見た逆方向の拡散処理を行うステップ数の指定などのオプションを できないなど、使い勝手についてはあまりよいとはいえません。
画像生成にかかる時間を短くしたい、さまざまなパラメーターを変更してみたいといった場合には、公式なWebサービスである「DreamStudio」がよいでしょう。2022年9月14日の時点ではこのサイトはあくまでもベータ版の状態であることには注意してください。また、Stable DiffusionとDreamStudioで生成された画像の著作権はCC0 1.0 Universal Public Domain Dedicationとのことです。

こちらは登録した時点で200単位(単位は「generation」)のポイントが割り当てられています。そのポイントを使い果たすと、有償でメンバーシップを購入可能です。1枚の画像を生成するのに必要なコストは、その大きさとステップ数で決まっていて、512×512ピクセルで50ステップを指定した場合のコストが1となっています(つまり、200 generationsのポイントがあれば今述べたサイズとステップ数の画像を200枚生成できるということでしょう)。
コストについてはDreamStudioのFAQページで確認できます。
基本的な使い方としては画面下部にあるテキストボックスにプロンプト(どんな絵を生成したいかを記述したテキスト)を入力して、[Dream]ボタンをクリックするだけです。
![プロンプトを入力するテキストボックスと[Dream]ボタン](https://image.itmedia.co.jp/l/im/ait/articles/2209/16/l_di-sdfn0107.gif)
ここに入力するテキストが生成される画像のだいたいの方向性を条件付けます。それをカスタマイズしていくのが、ウィンドウ右側の部分です。プロンプトと各種の項目を変更しながら[Dream]ボタンをクリックすることで、生成される画像がどんどん変わっていくのはとても楽しいです。
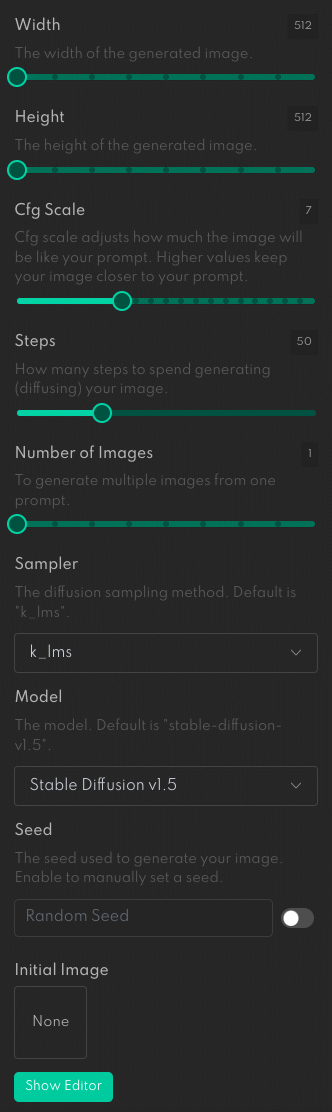 オプションを指定するフィールド
オプションを指定するフィールドここでは以下に示すような項目を指定できます。
- [Width]:画像の幅
- [Height]:画像の高さ
- [Cfg Scale]:プロンプトに対する忠実度の指定
- [Steps]:画像生成に何ステップを費やすか
- [Number of Images]:1つのプロンプトから何枚の画像を生成するか
- [Sampler]:使用するサンプラー(後述)
- [Model]:使用するStable Diffusionのモデルのバージョン
- [Seed]:画像生成に使用する乱数の初期値
- [Initial Image]:image-to-image (画像から画像を生成するモード)で画像を生成する際の初期画像
[Width]と[Height]はその名の通り、生成される画像の幅と高さを指定するものです。[Cfg Scale]については後で少し詳しく説明しましょう。[Steps]は画像を生成する際に、冒頭で述べたノイズ除去の過程を何回繰り返すかを指定します。これが多いほど高精細な画像になりそうですが、多くの場合はデフォルト値の「50」程度で十分でしょう。[Number of Images]は一度に何枚の絵を生成するかの指定です。[Sampler]についても後で取り上げます。[Model]では使用するStable Diffusionのバージョンを指定できます。[Seed]は乱数の初期値です。デフォルトでは毎回ランダムな値が初期値を使って画像が生成されるのですが、この値を固定すると、(他のパラメーターも同じであれば)常に同じ絵が生成されるようになります。これらのオプションの意味は連載の中でいろいろと調べていくことにしましょう。
[Cfg Scale]の説明としてプロンプトに対する忠実度の指定と書きましたが、この値を大きくするとプロンプトに忠実な絵が生成され、この値を低めに設定すると生成される画像の多様性が大きくなります(忠実度と多様性がトレードオフの関係にあるといえます)。
例えば、以下は[Cfg Scale]として2と7と20を指定したときに「a red dragon flying in the cloud with lightning, Ukiyoe style.」というプロンプトから生成された画像です(乱数のシードは「3361770942」で固定)。
 「a red dragon flying in the cloud with lightning, Ukiyoe style.」(稲光のする雲海を飛ぶレッドドラゴン、浮世絵スタイル)というプロンプトから生成された画像
「a red dragon flying in the cloud with lightning, Ukiyoe style.」(稲光のする雲海を飛ぶレッドドラゴン、浮世絵スタイル)というプロンプトから生成された画像上:[Cfg Scale]=2、中:[Cfg Scale]=7(デフォルト)、下:[Cfg Scale]=20(最大)
稲光が全てどこかに消えてしまってはいますが、どれも浮世絵っぽい画像にはなっています。[Cfg Scale]=2のときには雲海とレッドドラゴン以外にもいろいろな要素が絵に含まれているようにも見えます。[Cfg Scale]=7では雲海なのか別のブラックドラゴンなのかは分かりませんがプロンプトにある程度は忠実な絵ができたように感じられます。[Cfg Scale]=20になると忠実度も上がっていそうです。とはいえ、試した限りでは[Cfg Scale]を大きくすればよいというわけでもなく、ある程度の多様性を含めるのがよさそうでした(そういうこともあって、デフォルト値は7になっているのでしょう)。
困ったことに上の画像を作成するために「あーでもない。こーでもない」とやっているだけで、初期の200generationsがアッという間になくなってしまって、お金を払うことになってしまったのでした(笑)。少し変更して、結果がパッと出てくると[Dream]ボタンをバンバンクリックしちゃいますね。ガチャとかやらない派なんですが、ハマったら課金が大変なことになりそうです。はやいとこローカル環境を作らないと(汗)。
今の画像生成AIってプロンプトを少しずつ書き換えながら絵を調整するものだと思うから、確かにローカル環境で実行しないとお金が湯水のように流れていきそうですね……。
[Sampler]はどんなアルゴリズムを用いてノイズ除去を行うかを指定するものです。アルゴリズムによっては少ないステップ数でも十分な質の画像を生成できるでしょう(これについては後続の回でアルゴリズムを入れ替えながら画像の生成ができればいいなと考えています)。
どんなプロンプトが効果的 についてかは、Webを検索すれば幾らでも解説記事が見つかるはずです(例えば、Gigazineの「画像生成AI『Stable Diffusion』『Midjourney』で使える呪文のような文字列にパラメーターを簡単に追加できる『promptoMANIA』の使い方まとめ」や、生成される画像のスタイルの指定に使える語を集めた「100+ Stable Diffusion styles & mediums」などがあります)。でも、DreamStudioの「Prompt Guide」ページにも基本的な要素については説明があるので、最初のうちは参考になるかもしれません。
Stable Diffusionで画像生成を行う際に行われていること
最後にStable Diffusionで画像生成を行う際にはどんなことが行われているのか、その概要をざっくりと紹介します。ただし、ここではHugging Faceで公開されている「Stable Diffusion with Diffusers」というドキュメントを基にします(この後で出てくるDiffusersが提供するStableDiffusionPipelineクラスは、Stable Diffusionのtxt2img.pyファイルで行われている処理と似たことをラップしているのだと筆者は考えていますが、双方の実装を細かく読み下したわけではないので、そうではない可能性もあります)。
このドキュメントでは、Stable Diffusionを構成する3つの主要要素として以下が挙げられています。
- VAE
- U-Net
- テキストエンコーダー
やっぱり中の仕組みの話は難しい単語ばかりですね。いずれも専門用語なので、「分からない」と思ったら、流し読みで大丈夫だと思います。このセクションはPythonコードを読み書きする知識が必要になっています。
VAEのうち、エンコーダーは訓練にのみ使われ、次に述べるように、U-Netからの出力を基に画像生成をする際にはデコーダーだけが使われます。
この中で画像(の潜在表現)を生成するのがU-Netです。U-Netは潜在表現を受け取り、そこから逆方向の拡散プロセス(ノイズを除去して画像を生成するプロセス)の何らかの段階で使われるノイズ(の残差の潜在表現)を推測します。これを使って作成した(少しノイズが除去された)画像の潜在表現が次のU-Netへの入力になります。逆方向の拡散プロセスが終わって、最終的に手に入れた潜在表現は上記VAEのデコーダーを使った画像生成に使われます。
U-Netは潜在表現を受け取るだけではなく、テキストエンコーダーを使ってユーザーが入力したテキストを埋め込み表現に変換したものも受け取ります。これにより、先ほどの「a red dragon flying in the cloud with lightning, Ukiyoe style.」のようなテキストにより生成される画像に対する条件付けを行えます。
ここでは例としてHugging Faceが提供するDiffusersに含まれているStable Diffusionを使うためのStableDiffusionPipelineクラスのコードを見てみます。このクラスの__call__メソッドには今述べたような処理を実際に行っている部分があります。抜粋して以下に示します。
for i, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
# ……省略……
noise_pred = self.unet(latent_model_input, t,
encoder_hidden_states=text_embeddings).sample
# ……省略……
latents = self.scheduler.step(noise_pred, t, latents,
**extra_step_kwargs).prev_sample
image = self.vae.decode(latents).sample
このコードにはlatentsとlatent_model_inputという2つの変数が見られますが、これらは基本的には同一のもので潜在表現を表しています。latent_model_inputは、U-Net(self.unet)への適切な入力となるようにlatentsに手を加えたものだと考えてください(「classifier free guidance」による手法で画像生成を行うかどうかや、サンプリングによるノイズ除去をどのように行うかを決定する「スケジューラ」と呼ばれるオブジェクトとして何を選択したかなどによって、latentsの内容を基にlatent_model_inputの内容が決まります)。
このforループでは逆方向の拡散プロセスを行います。その中で、「noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample」のようにして推測したノイズの残差を取得しています。そして、「latents = self.scheduler.step(nlatents = self.scheduler.step(……)」行ではそのノイズを除去した画像(の潜在表現)を計算して、これを次のU-Netへの入力としています(上のコードでは1行にしていますが、実際には先ほど述べたスケジューラに何を選択したかで呼び出し方が変わっています)。
ループが終わった後は、既に述べた通り、VAEのデコーダーを使って潜在表現から実際の画像を生成しています。
U-Netの呼び出しは「noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample」のようになっていますが、このときキーワード引数encoder_hidden_statesに指定しているのが、埋め込み表現に変換されたテキストです。Stable Diffusionでは事前に訓練済みのCLIP ViT-L/14 text encoderを使用して入力されたテキストをトークン化し、さらにこれを埋め込み表現に変換したものをU-Netに入力しています。以下は上記と同じソースコード(__call__メソッド)からこの処理を抜き出したものです。テキストエンコーダーの効果については、本連載の中で試してみる予定です。
text_input = self.tokenizer(……)
text_embeddings = self.text_encoder(text_input.input_ids.to(self.device))[0]
# ……省略……
latents = …… # latentsの初期化
# ……省略……
for i, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
# ……省略……
noise_pred = self.unet(latent_model_input, t,
encoder_hidden_states=text_embeddings).sample
# ……省略……
Stable Diffusionが提供する訓練済みモデルを使って画像を生成する際には、今述べたようにVAE(のデコーダー)やU-Net、テキストエンコーダー(トークナイザーとエンコーダー)が使われます。これらを図にまとめたものが以下です。
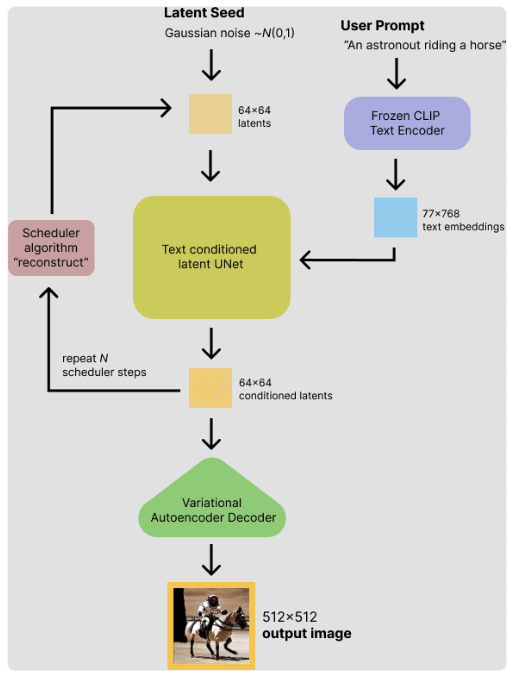 Stable Diffusionで画像を生成する過程
Stable Diffusionで画像を生成する過程ユーザーがプロンプトを入力すると、今述べたような処理を経て、画像が生成されるわけです。
今回は「Stable Diffusionとは訓練済みのモデル」「DreamStudioを使ってみる」「Stable DiffusionのモデルはVAE、U-Net、テキストエンコーダー、スケジューラなど、さまざまなパーツで構成されている」「それぞれのパーツが関連して画像が生成される」といったことを見てきました。
次回はローカルPCまたはGoogle Colab上のノートブック環境にStable Diffusion(とDiffusers)をインストールして、最初の一歩となるコードを書いてみることにします。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。