11gからの新管理機構「ADR」を理解しよう:Oracleトラブル対策の基礎知識(2)(2/4 ページ)
11gでの新しい概念:「問題」と「インシデント」
11gから新しく「問題」と「インシデント」という概念が導入されています。それぞれどのようなものか整理しておきましょう。
「問題」
「問題」とはデータベースで発生するクリティカルエラーを指します。ここでのクリティカルエラーとはORA-00600などの内部エラー、またはORA-07445およびORA-04031などの重大な障害となるエラーです。
「問題」は、Problem_IDとProblem_keyで識別されます。Problem_keyには、問題を説明するテキスト文字列が割り当てられます。Problem_keyには、エラーコード(例:ORA-600)が含まれており、1つ以上のエラーの引数が含まれる場合もあります。また、Problem_keyには、一意識別のためのユニークなProblem_IDが割り当てられ、管理されます。
Problem_IDとProblem_keyについては、後述のADRCIコマンドから確認できます。
最も重要なのは、同一のクリティカルエラーが何度発生した場合でも、生成されるProblem_IDとProblem_keyは1つのみということです。
新しくProblem_IDとProblem_keyが割り当てられるタイミングは、過去に発生したことがない新規のクリティカルエラーが発生した場合のみです。
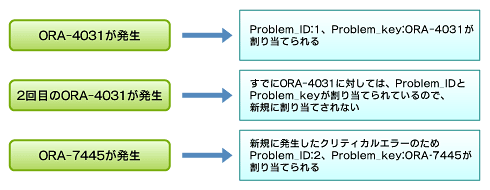 図2 Problem_IDとProblem_key割り当てのタイミング
図2 Problem_IDとProblem_key割り当てのタイミング「インシデント」
インシデントとは、問題の1回の発生を意味します。問題(クリティカルエラー)が複数回発生した場合は、発生ごとに1つのインシデントが作成されます。各インシデントは、ADR内で一意の数値であるIncident_IDによって識別されます。また、この個々のインシデントに対してインシデントダンプがADR_HOME/incident配下に作成されます。
インシデントダンプとは、インシデントに関する障害診断データをダンプファイル形式で収集したものです。
従来トレース・ファイルに出力されていた、current SQLやスタックトレースなどがインシデントダンプに出力されます。
複数回同一のエラーが発生した場合の「問題」と「インシデント」の関係を表すと、以下のようになります。
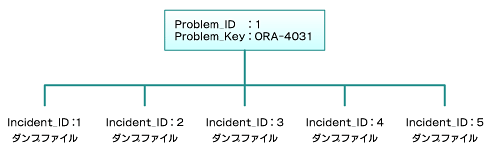 図3 ORA-4031が5回発生した場合の例
図3 ORA-4031が5回発生した場合の例1つの「問題」に対して、5つの「インシデント」がひも付いて作成され、上記5つのインシデントに対してインシデントダンプが1つ作成されます。
ポイント
図3の構造からも分かるとおり、発生したエラーの種類がProblem_keyで管理され、そのProblem_keyのエラーが発生した回数がIncident_IDで管理されているということになります。
インシデントのフラッド制御
従来のログの機構では、クリティカルエラーが発生するたびにトレース・ファイルが生成されていました。そのため、クリティカルエラーが解消されず、その状況下で運用を続けた場合、診断情報であるトレース・ファイルが大量に出力され、結果的にディスクを逼迫(ひっぱく)させる可能性がありました。
インシデントでも、1インシデントにつき1つのインシデントダンプが作成されますが、エラーの発生がしきい値に達した場合、フラッド制御がインシデント生成に適用され、以前のトレース・ファイルのように大量にファイルが生成されることがなくなりました。
「フラッド制御されたインシデント」は、アラート・ログエントリが作成されてADRに記録されますが、インシデントダンプは生成されないインシデントのことを指します。
インシデントのフラッド制御のしきい値は事前定義されており、変更はできません。このフラッド制御のしきい値は次のように設定されています。
1:時間内に同一のProblem_keyが5回以上発生した場合
後続のインシデントはフラッド制御されます。その問題キーに対するインシデントのフラッド制御の解除は、次の1時間後になります。
2:日に同一の Problem_key が 25 回以上発生した場合
後続のインシデントはフラッド制御されます。その問題キーに対するインシデントのフラッド制御の解除は、翌日に解除されます。
さらに、1時間に同じ問題キーに対して50のインシデントが発生、もしくは1日に同じ問題キーに対して250のインシデントが発生した場合は、後続のインシデントが記録されないことを示す以下のメッセージがアラート・ログに出力されます。
Further messages for this problem key will be suppressed for up to 10 minutes
問題キーに対してインシデントが継続して生成されている間は、1時間または1日が経過するまで、10分ごとにこのメッセージがアラート・ログに出力され、1時間または1日が経過すると、その問題キーに対するインシデントの通常の記録が再開されます。
注意
フラッド制御のため、問題が発生した該当の時間帯にエラーが記録されていない場合もあり得ます。アラート・ログについては最低1日分を確認する必要がありますので、注意してください。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。