ファイルシステムの仮想化とは何か:ストレージ仮想化の体系的理解(2)(1/2 ページ)
広義ではRAIDもストレージ仮想化の1つだ。だが、過去数年にわたり、それよりも上位レイヤのさまざまな仮想化が、ブロックストレージやNASに実装されるようになってきた。クラウド化の進行とともに注目が高まるスケールアウト型ストレージも、ストレージ仮想化の一形態だ。本連載では、ストレージの世界で一般化する仮想化について、体系的に説明する
1. もう一つの仮想化対象、ファイルシステム
前回の記事では、SNIAによるストレージ仮想化の分類(図1・再掲)に基づき、「ディスクの仮想化」と「ブロックの仮想化」の概要について説明した。
今回の記事では、より上位レイヤの仮想化である「ファイルシステムの仮想化」 「ファイルの仮想化」について解説する。また、ストレージ仮想化の方式をより 細かく分類するためのフレームワークを紹介する。
なお、ファイルの仮想化は、ファイルシステムの仮想化の一機能として実装されることが多い。そのため、今回の記事ではファイルシステムの仮想化を中心に解説し、最後にファイルの仮想化機能について説明する構成としている。
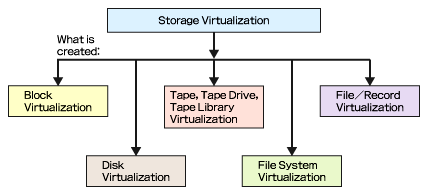 図1 SNIAによるストレージ仮想化技術の分類(再掲)
図1 SNIAによるストレージ仮想化技術の分類(再掲)ファイルシステムの仮想化が必要な理由
ファイルシステムの仮想化はブロックの仮想化よりも上位レイヤで使われる技術だ。ブロックの仮想化で作られるものはボリュームであったが、ファイルシステムの仮想化では、そのボリューム上に作られるファイルシステムが仮想化の対象になる。
読者の中にはこういった疑問を持つ方がいるかもしれない――ブロックの仮想化があるのに、なぜファイルシステムの仮想化が必要なのか?――その理由は、ブロックの仮想化では解決できないファイルストレージの問題がいくつかあるからだ。
1つは、ファイルストレージのスケーラビリティの問題だ。ブロックの仮想化でいくら大きなボリュームを作り出せたとしても、従来のようにファイルシステムの処理が1つの物理マシン(サーバ)に紐づいているのなら、大きなファイルストレージを作ることは難しい。その物理マシンがボトルネックになるからだ。
もう1つは、複数のファイルストレージを運用する際、その間でのデータ移行をオンラインで(動作中のアプリケーションに影響を与えずに)できないという問題だ。これは、ファイルストレージ間でファイルやディレクトリを移動すると、アプリケーションがファイルにアクセスする際のパス名が変わってしまうためだ。ブロックの仮想化は、ブロックストレージ間でのオンラインデータ移行を可能にするが、ファイルストレージ間でのオンラインデータ移行には使えない。
このようなファイルストレージの問題を解決する際に、ファイルシステムの仮想化が有力な解決策となる。
ファイルシステムの仮想化とは何か
ファイルシステムの仮想化という言葉は、いろいろなシーンで違う定義で使われていることが多い。恐らく、ファイルシステムの仮想化の普及率がまだ高くないせいだろう。RAIDや論理ボリュームマネージャといったブロックの仮想化技術がほとんど全てのシステムで使われているのに対して、ファイルシステムの仮想化を使用しているシステムはまだ多くはない。
読者の誤解を防ぐために、ファイルシステムの仮想化という言葉をどんな意味で使うのかまず説明しよう。以下では、ファイルシステムの仮想化を、「ファイルシステムの処理を分散して行いつつ、仮想的な1つのファイルシステムを提供するための技術」という意味で用いている。ファイルシステムの処理が1台の物理マシンに紐づくのではなく分散して行われていつつも、複数のホストから単一のファイルシステムイメージとして見える、ということである。
この技術は、単一のネームスペースを複数のホストが共有できるという意味で、「グローバルネームスペース」と呼ばれることもある。個々のファイルやディレクトリへのパス名は通常、ストレージ装置ごとに別々に管理されている。これを単一の包括的な(グローバルな)ネームスペースとして、論理的なパス名を使って統合するのがグローバルネームスペースだ。これにより、複数のストレージ装置に存在するファイル群が、単一のファイルシステムに存在するものとして扱える。
このような仮想化ができると、上記で述べた、ファイルシステムのスケーラビリティ問題が解決できる可能性がある。ファイルシステム処理を複数のマシンで分散処理することで、大きくて高性能なファイルシステムを作れる様になるからだ。また、ファイルストレージ間のオンラインデータ移動問題も解決できる可能性がある。ホスト側には仮想的なイメージを使い続けてもらいつつ、その裏で物理的な配置だけを変えるというようなことができるようになるからだ。これらのユーザーメリットについては、後の方式説明のところで詳しく説明しよう。
2. ファイルシステムの仮想化の分類
ブロックの仮想化と同じく、ファイルシステムの仮想化にはいくつかの実装形態がある。そして、そのそれぞれが異なる特徴を持ち、異なる用途に使われている。ファイルシステムを仮想化するという意味では同じ技術でも、使い方は大きく異なるのである。
そのため、ファイルシステムの仮想化の利用を考える際には、もう一段深い分類をして、それぞれの実装形態の特徴を掴んでおいたほうがよい。ここでは、SNIAが作成した、ストレージ仮想化技術をより深く分類するためのフレームワークを紹介しよう。
仮想化処理が行われる場所で分類
図2を見ていただきたい。この図は、前回の記事で紹介した仮想化の対象(What)に基づく分類とは別に、仮想化処理が行われる場所(Where)でも仮想化技術を分類することができることを示している。具体的には、ホストベース、ネットワークベース、ストレージベースの3種類に分類することができる。
Whatで分類された方式をもう一段深く分類したいときに、このWhereのフレームワークが有用である。例えば、前回の記事では説明しなかったが、ブロック仮想化の技術をこのフレームワークに基づいて分類することができる。例えば、論理ボリュームマネージャはホストベース、ブロックストレージ仮想化アプライアンスはネットワークベース、スケールアウト型ブロックストレージはストレージベース、といった感じである。
以下、このWhereのフレームワークを使って、ファイルシステム仮想化の技術を分類してみよう。
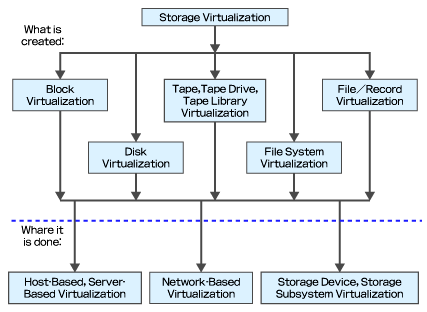 図2 SNIAによるストレージ仮想化技術の分類
図2 SNIAによるストレージ仮想化技術の分類3. ホストベースのファイルシステム仮想化
ホストベースの仮想化とは、ホスト上のオペレーティングシステムなどに仮想化機能を持ったソフトウェアを導入する方式である。
ファイルシステムの仮想化で該当するのは、クラスタファイルシステム(もしくはSANファイルシステム)と呼ばれる方式である。この方式では、各ホストにインストールされた特殊なファイルシステムを通して、複数のホスト上のアプリケーションが同じファイルシステムイメージを共有する。各ホストはネットワーク(普通はSAN)を通じてブロックストレージにつながっており、ホストはブロックストレージと直接データをやり取りする。
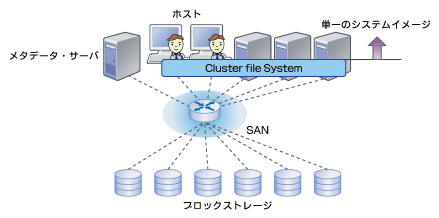 図3 クラスタファイルシステムの概要図
図3 クラスタファイルシステムの概要図高性能が求められる特定用途に最適
後述する他の2方式と比べた場合のクラスタファイルシステムの長所は、高い性能を出しやすいということだ。その理由は2つある。1つは、データの読み書きに、ファイルアクセスよりも効率のよいブロックアクセスを使えるためだ。ブロックアクセスはファイルアクセスよりも低いレイヤのため、処理が単純になり実効スループットが高くなる。もう1つの理由は、仮想化アプライアンスのような中継役を介さずに各ホストがストレージに直接アクセスするためだ。直接アクセスすることで、レスポンスタイムが小さくなる。
一方で、クラスタファイルシステムの課題は、各ホストに特殊なファイルシステムをインストールしなければならない点だ。オペレーティングシステムが標準で備えているNFS/CIFSプロトコルを利用する他の2方式と比較して、クラスタファイルシステムでは、ホスト上にソフトウェアをインストールし、アップデートしていく必要がある。その結果、導入・管理・保守などが複雑になりやすい。
これらの特徴から、クラスタファイルシステムは、一般的に広く用いられるソリューションというよりは、高性能が求められる特定用途向けのソリューションとして位置づけられることが多い。具体的には、ハイパフォーマンスコンピューティングやメディア・エンターテインメントなど、大きなファイルを多量にもち、それらに高速なアクセスが求められる領域でよく使われている。これらの用途では、管理面のデメリットよりも性能面のメリットが大きく勝るためだ。最近よく話題に上る、大規模データ処理基盤Hadoopのバックエンドで使われているHDFSもクラスタファイルシステムの一種である。
メタデータサーバの活用
クラスタファイルシステムにはいろいろな種類があるので、実装の違いについても少し紹介しよう。1つ大きなポイントとなるのは、メタデータ操作を各ホストで分散して行うのか、それともメタデータサーバを別に立てるかという点である(メタデータとは、ストレージ上のファイルの物理的位置、ファイル名、作成・更新日時、アクセス権限などのファイルシステムの管理情報のこと)。メタデータサーバを立てると、例えば、rename(移動)のようなメタデータ操作処理はメタデータサーバに送られ、readやwriteのようなデータ処理は個々のノードがブロックストレージに直接アクセスして処理される。
一般的には、メタデータサーバを立てるとホスト間での調整が要らなくなるので、大規模な構成をとりやすくなる。そのため、スケーラビリティを重視する場合は、メタデータサーバを別に立てるケースが多い。上記で紹介した図は、メタデータサーバを使うモデルである。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。