派生型でもっと便利にデータを扱う:目指せ! Cプログラマ(10)(1/2 ページ)
連載第3回ではchar型や整数型など基本型について学びました。今回は基本型を組合せて使える派生型について説明します。派生型には構造体、共用体、配列などがあります
前回は識別子の有効範囲と変数の生存期間について学びました。これらをきちんと把握することで、どのタイミングでどの変数や関数が使えるのか把握することができます。さらにうまく使いこなせば、自分が作った変数や関数をどこまで見せるのかコントロールすることもできるようになります。
今回は再び型について取り上げます。第3回ではchar型や整数型、浮動小数点型などの基本型について学びました。今回は基本型を組み合わせて、もっと便利に使える派生型について説明します。派生型には、構造体、共用体、配列といったものがあります。
構造体は他のデータ型を含むことができる
プログラムが複雑になってくると、それにつれてたくさんのオブジェクト(変数)を扱わなければなりません。実際のプログラムでは、わずかなコードであっても、いくつものオブジェクトが必要になってきます。全体を把握しきれないほどの数になってしまっても落ち着いてそれらのオブジェクトを整理してみると、オブジェクト同士で何らかの関係を持っていることが多いでしょう。
ここでは、あるタイミングにおける気象データについて考えてみます。気象データにもいろいろありますが、「気温」「湿度」「直前1時間あたりの降水量(mm/h)」という3つのデータを記録したいとしましょう。
これらのデータは「あるタイミングにおける天候」という点で関連しているため、時間軸でまとめて扱うのがよさそうだと考えられます。ノートで整理するならば、3つの名前を縦に並べて書き、その横に測定した値を書いていくことでしょう。プログラムのソースコードでも同じようにまとめて扱えると便利です。
Cではこのようなデータを扱うときに “構造体”が使えます。構造体はデータ構造の1つで、他の型を含むことができるという特徴があります。先ほどの気象データの例を構造体を使って表してみましょう。
// 構造体kishoの宣言
struct kisho {
double kion; // 気温【単位:度】
double shitsudo; // 湿度【0 〜 1、1=100%】
unsigned int kousuiryo; // 降水量【単位:ミリメートル】
};
構造体を宣言するときは、structキーワードに続いて構造体の識別子である“タグ”を指定します。ここではkishoというタグを付けて構造体を宣言しています。
構造体を宣言することで、気温、湿度、降水量をまとめて扱える、1つの型を独自に用意したことになります。型になっているということは、他のintやdoubleといった型と同じように、変数を定義したり、値を代入したり、引数として関数に渡したりすることができるということです。
構造体kishoにおけるkionのように構造体の中に含まれている要素を、その構造体の“メンバー”と呼びます。構造体kishoは、kion、shitsudo、kousuiryoという3つのメンバーを持っています。メンバーは構造体の宣言と一緒に宣言され、変数の宣言とほぼ同じ書き方をします。
01: #include
02: #include
03:
04: // 構造体kishoの宣言
05: struct kisho {
06: double kion; // 気温【単位:度】
07: double shitsudo; // 湿度【0 〜 1、1=100%】
08: unsigned int kousuiryo; // 降水量【単位:ミリメートル】
09: };
10:
11: // struct kisho型の仮引数を持つ関数
12: void func(struct kisho k) {
13: printf("kion %.1f C, shitsudo %.1f %%, kousuiryo %d mm\n",
14: k.kion, k.shitsudo * 100, k.kousuiryo);
15: }
16:
17: int main(void) {
18: // struct kisho型の変数k1を定義
19: struct kisho k1;
20:
21: // k1の値を設定する
22: k1.kion = 16.7;
23: k1.shitsudo = 0.63;
24: k1.kousuiryo = 0;
25:
26: // kion 16.7 C, shitsudo 63.0 %, kousuiryo 0 mm
27: func(k1);
28: return EXIT_SUCCESS;
29: }
構造体のメンバーは“.”演算子(k1.kion において k1とkionの間にある“.”のこと)を使うことで、値を参照したり、設定したりすることができます。
構造体にはintやdoubleなどの基本型だけではなく、この後に説明する共用体や、今後の連載で解説するの予定のポインター、さらにはほかの構造体を入れ子にしてメンバーにすることもできます。
ここではある時刻の気象データだけを扱っていますが、別の時刻の気象データを扱うには、もう1つkisho構造体の変数を定義します。それぞれの変数には別々の値を持つことができますので、例えば1時の気象データと2時の気象データを別々に管理することができます。
// 1時の気温は16.7度 struct kisho k1; k1.kion = 16.7; // 2時の気温は18.1度 struct kisho k2; k2.kion = 18.1;
もちろん、kisho構造体は気温だけではなく湿度や降水量も扱えますから、時刻ごとの気象データを分けて整理することが簡単にできることが分かります。
構造体の宣言では次のような形式もよく使われますので、覚えておくとよいでしょう。
// (1) タグを省略して、変数を一緒に宣言する。
// タグがないのであとから変数を宣言したり、
// 関数に渡したりすることができない。
struct {
/* 省略 */
} k1, k2;
// (2) typedefを使ってstructを省略する。
// struct kisho ではなく KISHOと書けるので
// コードが見やすくなる。
struct kisho {
/* 省略 */
};
typedef struct kisho KISHO;
KISHO k1, k2;
// (3) typedefとstructを組み合わせることもできる。
typedef struct kisho {
/* 省略 */
} KISHO;
KISHO k1, k2;
なお、メンバーの名前は、そのメンバーが属している構造体の中でのみ有効です。言い換えるなら、メンバーの識別子は構造体ごとに名前空間を持ちます。ということはつまり、構造体ではない型の変数や別の構造体のメンバーに同じ識別子があったとしても、それらは全く別の識別子となります。
struct kisho {
double kion; // (1) この気温は、他の2つの気温とは別のもの
};
double kion; // (2) この気温は、他の2つの気温とは別のもの
struct cooler {
double kion; // (3) この気温は、他の2つの気温とは別のもの
};
あわせて、プログラム実行時に構造体のデータがどのようにメモリ上へ配置されるかについて確認しておきましょう。構造体のメンバーで表現されたデータは基本的に連続して配置されます。kisho構造体の例で言えば、kion、shitsudo、kosuiryoは、宣言された順に連続して存在します。
ただしコンパイラによっては、メンバーとメンバーの間に隙間を入れる場合があります。これを“パディング”と呼びます。ほとんどの場合、コンパイラがパディングを入れるかどうかを、プログラマーは意識する必要はありません。パディングがあってもなくても、同じようにメンバーを参照することができます。
コラム●構造体のパディングを意識する
本文中でも説明したとおり、構造体のパディングがあってもなくても、“.演算子”を使えば意識することなくコードを書くことができます。
しかし、メモリ上に配置されたデータの並びを意識して扱いたいときは、パディングがあるかどうか重要になってくる場合があります。複数のアーキテクチャの間でデータをやり取りするときや、ファイルやメモリに保存されたデータを読み書きする場合などです。主に組み込みプログラムや、システムプログラムで必要になります。
パディングがどのように付加されるかは、コンパイラーや、コンパイラーのオプションによって変わります。構造体とパディングを使いこなすと、複雑な処理をとても簡単に書いたりすることができることがありますので、パディングというものがあるということは気に留めておいてください。
共用体は重なりあったデータを表現する
次に私たちは、16ビットレジスター用の値を扱うプログラムを作成しているとします。そのプログラム内では、16ビット値(0x1234)について、ある処理では16ビット値(0x1234)として扱い、別のある処理では上位8ビット(0x12)と下位8ビット(0x34)に分けて扱いたい、としましょう。これを扱うための独自の型を構造体で用意しようとすると、例えば次のようになります。16ビット値用のax、上位8ビット用のah、下位8ビット用のalをメンバーとして持つstruct regという構造体にするのです。
struct reg {
uint16_t ax;
uint8_t ah;
uint8_t al;
};
構造体でこのように表現することができますが、同じ値を3つのメンバーで表現するのはメモリの無駄使いになります。Cでは、このようなときは共用体を使います。共用体は、構造体とは違い、領域が重なったメンバーを表現することができます。では、さきほどの例を共用体で表現するには、どのようになるか考えてみましょう。
union {
uint16_t ax;
struct {
uint8_t ah;
uint8_t al;
} h;
} reg;
reg.ax = 0x1234;
printf("ax=0x%x, { ah=0x%x, al=0x%x }\n", reg.ax, reg.h.ah, reg.h.al);
共用体を宣言するにはunionキーワードを使います。この例ではaxという16ビットの変数は、ahとalという8ビットのメンバーを持つ構造体と重なっていることを表しています。
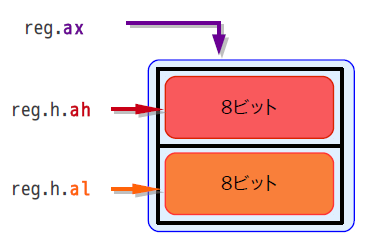 共用体では重なったメンバーを表現できる
共用体では重なったメンバーを表現できるただし、このコードの実行結果は環境によって異なります。実行環境によって「ah=0x12, al=0x34」または「ah=0x34, al=0x12」になります。
共用体は「領域が重なったメンバーを表現できる」ので、あるデータをdouble型、int型のどちらでも記録できるような独自型を用意したい場合にも使えます。そのようなときは、次のような共用体を用意します。double値を記録する場合はtypeへ1を、int値を記録する場合はtypeへ2を代入するといったことを決めて使います。
struct data {
unsigned int type;
union {
double dv;
uint8_t iv;
} value;
};
はじめのうちは難しいかもしれませんが、使っているシステムが提供している機能の中には、共用体をうまく使って便利な記述ができるようにしているものがあるかもしれません。それらを使いながら慣れていくと良いでしょう。
配列は同じ型のオブジェクトを複数まとめて扱う
次に、1日の気温を記録するプログラムを考えてみましょう。気温はdouble型の変数で扱うことにします。
// ここに気温(kion)が入る。
double kion;
double get_kion(void) {
// 気温を取得して返す関数。内容は省略。
}
/* この関数は毎正時に呼ばれるとする。
仮引数hourには0〜23の時が入る。 */
void on_the_hour(int hour) {
// 1日分の気温を記録したいが...
kion = get_kion();
}
関数get_kionは呼び出されると、何らかの方法で気温を測定し、戻り値として返します。関数on_the_hourは毎正時(0分0秒になる時刻)に呼ばれるとします。
このプログラムでは、取得した気温を変数kionに入れていますが、このままではon_the_hourが呼び出されるたびに変数kionの気温は上書きされてしまいます。1日分の気温を記録したいので、24個のdouble型の変数が必要になってきます。これまでの知識でプログラムを作成するとしたら、kion01、kion02、kion03……、という変数を用意しても実現できます。しかし24個の同じような変数を用意するのは大変です。こんなときは、“配列”を使うとより簡単に扱うことができます。
配列とは、ある決まった型のオブジェクトがいくつも連続しているオブジェクトで、次のように宣言します。
// double型のオブジェクトが24個分ある配列kionを定義する double kion[24]; // 1つ目の変数に値を入れる // [ ] 内は 0から始まる点に注意 kion[0] = 16.7; // 2つ目の変数に値を入れる kion[1] = 18.1;
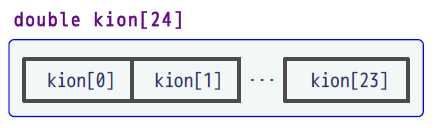 配列は決まった型のオブジェクトが連続しているオブジェクトで順番に添字が付く
配列は決まった型のオブジェクトが連続しているオブジェクトで順番に添字が付くdouble型の変数が24個並んでいるイメージができましたでしょうか。
配列には複数の要素が並んでいて、最初の要素から順番に、各要素に番号がついています。最初の要素には0、次の要素には1、のようにつきます。この番号を添字(インデックス)といいます。ある要素へ値を代入したり、ある要素の値を参照したい場合には、利用したい要素の添字を指定します。Cでは、この添字を指定するための演算子として添字演算子[]が用意されています。これを理解すると、「kion[0]」というのが配列kionの1つ目の要素を表す変数だということが分かります。
このように配列を使うと、1日の気温を記録するプログラムのように「同じ型のオブジェクトを複数まとめて扱いたいプログラム」が簡単に作れます。
インデックスの指定は整数の値を持つ式を指定できますので、for文を利用したループを使うと、配列の要素に順番にアクセスできます。
int i;
for (i = 0; i < 24; i++) {
printf("kion[%d] = %f\n", i, kion[i]);
}
さて、最初の構造体の説明で、気温、湿度、降水量の、3つの気象データを扱いました。構造体と配列を組み合わせることで、1日分の気象データを扱うことができます。
// 気象データの構造体。
struct kisho {
double kion; // 気温
double shitsudo; // 湿度
unsigned int kousuiryo; // 降水量
};
// 気象データ構造体の配列。
// 一日分を格納できるように24個分の領域を確保する。
struct kisho kisho_day[24];
// 0時の気象データ
// 配列の先頭要素の位置(インデックス)は0
kisho_day[0].kion = 16.7;
kisho_day[0].shitsudo = 0.63;
kisho_day[0].kousuiryo = 0;
// 1時の気象データ
kisho_day[1].kion = 18.1;
// 以下省略
これで「24時間分の気温、湿度、降水量」という複雑なデータ構造を表すことができました。
ところで、自動変数(autoを指定、あるいはautoを省略した変数)は自動的に初期化されませんでした。静的変数は宣言したときに0に初期化されました。これらの性質は、構造体や配列も同じです。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。