もう絶望しない! ディープラーニングによる画像認識のビジネス活用事例:いまさら聞けないDeep Learning超入門(3)(2/2 ページ)
CNNの解析結果の活用方法
こうして、各ネイル画像にデザイン頻度ベクトル(AデザインX本、BデザインY本……)と、1000種類のカラービン頻度ベクトル(ビンNo1:N、ビンNo2:M……)が出来上がりました。後は、これを使ってネイル画像ごとの類似度を計算するだけです。
類似度の計算は最終的にcos類似度を利用しました。交差法などいろいろ試した結果、cos類似度が最も良い結果となったためです。
3カ月で40を超える試行を実施
上記に挙げた以外にも粒度の大小はありますが、3カ月で40を超える試行を実施し、結果を確認しては、「次はどうする?」というPDCAを高速に回し続けました。このような試行錯誤により、例えば筆者たちのソースコードの中には、「skin_color_list」というマジックリストが存在します。肌色を除外するためのリストですが、トライ&エラーが生んだ、一見誰にも全く理解されない謎の副産物です(笑)。しかし、このような地道な作業が確実に画像解析をビジネス利用に近づけてくれます。
もちろん、これ以外に、CNNでのデザイン判別精度そのものを向上させるためのモデルチューニングも重要な要素となります。こちらに関しては、第4回に詳細をお伝えいたします。
「ギャザリー」における不適切画像検出事例
キュレーションメディアの「ギャザリー」(リクルートライフスタイル提供)では、不適切画像を検出する機能を試験的に導入しました。
目的
カスタマーの投稿画像が、グロテスクやセクシャルなど、不適切であるかどうかのチェックを支援することを目的とした機能です。これは、不適切か否かを予測するための適切なカテゴリを作成し、そのカテゴリを多段でまとめ上げて最終的に判定することで実現しています。
本事例においては、「適切なカテゴリの作成」がCNNを利用する前の前処理となり、「カテゴリを多段でまとめ上げる作業」がCNNの活用方法となります。
CNNでの解析を行いやすくする事前準備
適切なカテゴリの作成とは、「カテゴリを独立になるように振り分ける」作業を言います。例えば「グロテスク」という1カテゴリにおいては、「傷が映っている」「遺体が映っている」「血が飛び散っている」など、さまざまなものが考えられます。これをまとめて1つの「グロテスク」カテゴリとして学習すると、特徴が分散してしまうのでうまく予測することができません。
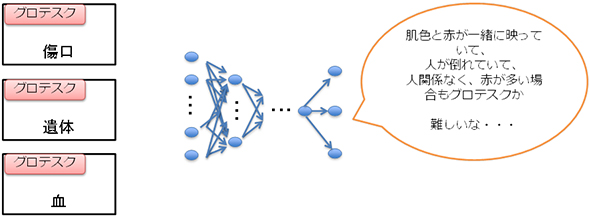
一方、「傷が映っている」「遺体が映っている」「血が飛び散っている」などを1つにまとめるのではなく、それぞれを別カテゴリにすることで特徴が明確となり、CNNで高精度を出しやすくなります。この際、「どのようにカテゴリを切るか」については、「実際に解析する対象画像に、どういう画像が多く含まれるか」を想定して作ることが重要です。全く解析対象画像にならないものを想定してカテゴリを分け、学習画像を用意しても徒労に終わってしまいます。
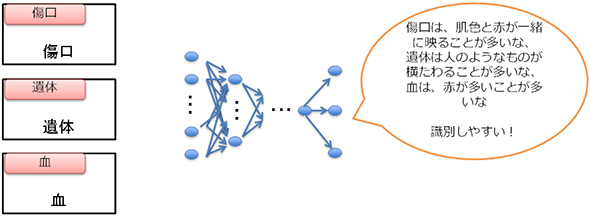
こうしてカテゴリを分けた後、そのカテゴリのいずれかと判別されたら、それを「グロテスク」と最終的に判断すればいいのです。不適切ではない画像のカテゴリも同様です。不適切ではない全ての画像を、1つの「正常」というカテゴリとするより、「正常」の中で特徴が独立になるようなカテゴリ割りをしてあげるのが、CNNの活用に大切です。
次回は、CNNでの予測精度を高めるためのチューニングについて
以上、リクルートグループの画像解析の事例を紹介しました。
CNNは、画像解析を手軽に、精度良く行うために素晴らしい技術だと思います。これをビジネスに活用するにはCNNの強みをしっかりと認識し、適切に使いこなすための努力が必須です。
今回は、CNNを適切に使いこなすためには、CNNを実行する前処理と、CNNで得られた結果をいかに利用するかが重要であることを、実事例を交えてお伝えしました。次回は、CNNでの予測精度を高めるためのチューニングについて解説します。
筆者紹介
白井 祐典(しらい ゆうすけ)
リクルートテクノロジーズ ITソリューション統括部 ビッグデータ部
独立系SIerで2年半働き、2012年にリクルートテクノロジーズ ビッグデータ部に中途入社。以降、3年にわたってカーセンサー(リクルートマーケティングパートナーズ提供)におけるHadoopを用いたビッグデータ活用に従事。現在は、事業対応とともに画像解析の技術検証とディレクション業務に従事。
関連記事
 グーグルの人工知能を利用できるWebインターフェースが登場
グーグルの人工知能を利用できるWebインターフェースが登場
オズミックコーポレーションとイントロンワークスは7月7日、グーグルの人工知能アルゴリズム「Deep Dream」を利用できるWebインターフェースを公開した。 顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成――デザイナー/クリエイターが茫然自失で拍手喝采な最先端技術動画11連発
顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成――デザイナー/クリエイターが茫然自失で拍手喝采な最先端技術動画11連発
アドビ システムズは、2015年10月6日(現地時間)に開催した「Adobe MAX 2015 Sneak Peeks」で、11の新技術を披露。顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成naなど、今回もデザイナー/クリエイターのみならず、日常的にデジカメやスマホで写真を撮る人でも欲しくなるような機能が多数見られた。 米AlpacaDBがDeep-Learningを使った金融プラットフォームを開発へ
米AlpacaDBがDeep-Learningを使った金融プラットフォームを開発へ
Deep-Learning技術による画像認識プラットフォームを展開してきたAlpacaDBが、資金調達に成功し、金融系の事業領域に本格進出する。 セキュリティ対策に数学の力を――機械学習は先行防御の夢を見るか?
セキュリティ対策に数学の力を――機械学習は先行防御の夢を見るか?
どうしても攻撃者の後手に回りがちなセキュリティ対策。ここに機械学習を活用することで、先手を打った対策を実現できないか――そんな取り組みが始まろうとしている。 個人と対話するボットの裏側――大衆化するITの出口とバックエンド
個人と対話するボットの裏側――大衆化するITの出口とバックエンド
マシンラーニング、ディープラーニングなど、未来を感じさせる数理モデルを使ったコンピューター実装が注目されている。自ら学習し、機械だけでなく人間との対話も可能な技術だ。では、コンピューターはどのように人間との対話を図ればよいのだろうか。コンピューターの技術だけでなく、そこで実装されるべきインターフェースデザインを考えるヒントを、あるコンシューマーアプリ開発のストーリーから見ていく。 自動車を制御するロボットの思考と行動の仕組み――Google Carが現実世界を認識する際の3つのアルゴリズムと実用化への課題
自動車を制御するロボットの思考と行動の仕組み――Google Carが現実世界を認識する際の3つのアルゴリズムと実用化への課題
本連載では、公開情報を基に主にソフトウエア(AI、アルゴリズム)の観点でGoogle Carの仕組みを解説していきます。今回は、制御AIの思考と行動のサイクル、位置推定の考え方「Markov Localization」における3つのアルゴリズムと、その使い分け、現実世界の認識における課題などについて。 バンナム、スクエニ、東ロボ、MS――人工知能や機械学習はゲーム開発者に何をもたらすのか
バンナム、スクエニ、東ロボ、MS――人工知能や機械学習はゲーム開発者に何をもたらすのか
8月26日に開催されたゲーム開発者向けイベントの中から、バンナム、スクエニ、東ロボ、MSなどによる人工知能や機械学習、データ解析における取り組みについての講演内容をまとめてお伝えする。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。