Apache Sparkとは何か――使い方や基礎知識を徹底解説:Amazon EMRで構築するApache Spark超入門(1)(2/3 ページ)
Spark 2.0のインストール
Sparkがどんなものかを体験するため、インストールして実際に処理を実行しながら学んでいきましょう。
公式サイトのダウンロードページから2.0.0を選択してダウンロードしてください。パッケージタイプは「Pre-built for Hadoop 2.7 and later」でOKです。

ダウンロードしたものを展開すると「jars」ディレクトリ以下には依存のjarファイルが入っています。そして、「lib」ディレクトリ以下にjarファイル、「bin」「sbin」ディレクトリ以下には、実行スクリプトが配置されているはずです。この実行スクリプトを使うことで、対話型で分析したり、記述したアプリケーションを実行したりすることができます。
主要なスクリプトを下記に挙げておきます。
- spark-submit:実装したアプリケーションを実行するためのスクリプト。spark-shell、spark-sqlなども中身はこのspark-submitを使用している
- spark-shell:対話型に処理を実行できるツール
- spark-sql:sparkの計算をsqlで実行できるツール
- pyspark:Pythonで記述したSparkアプリケーションを実行することができるツール。対話型でも実行できる
- sparkR:統計言語RからSparkを利用できるツール
本稿では、この中からspark-shellを使っていきます。
Sparkの処理を実行してみる
Sparkスタンドアロンモードを試す
Sparkのクラスタは1つのマスターと複数のワーカーで構成されています。
クラスタ起動スクリプトが用意されているので、試しにローカル機でマスターとワーカーを立ち上げてみます。
まず、マスターを立ち上げるために、展開したディレクトリに移動して下記のコマンドを実行します。
./sbin/start-master.sh
「starting org.apache.spark.deploy.master.Master, logging to ...」と表示され、ログのパスも確認できます。
もし、「localhost: ssh: connect to host localhost port 22: Connection refused」というメッセージが表示された場合は、リモートログインの設定の変更が必要なので確認してみてください(Macの場合は必要です)。
Sparkには処理の状況が確認できる便利なWebのユーザーインタフェース(以下、WebUI)があり、クラスタやマスターの詳細を確認できます。
WebUIを使うには、下記のURLにアクセスしてみてください。
- http://localhost:8080/
ページ内には、マスターのURLやREST URL、Alive workersなどが表示されているはずです。もしページにアクセスできない場合は、起動に失敗している可能性があるので、ログを確認して見てください
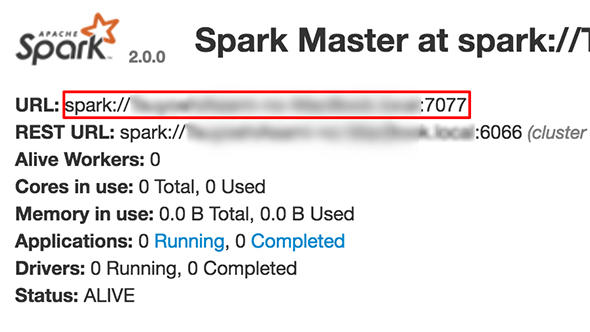 WebUIの表示例(赤枠部分がマスターのURL)
WebUIの表示例(赤枠部分がマスターのURL)次に、ワーカーを立ち上げます。本番運用では別ノード上で行うものですが、今回は、ローカル内で立ち上げます。引数に先ほど立ち上げたマスターのURLを指定してください(マスターのURLは前述のWebUIで確認できます)。
./sbin/start-slave.sh {マスターのURL}
うまく立ち上がると、WebUIの「Workers」にも追加されます。
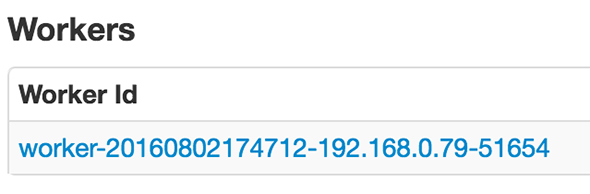
クラスタ起動スクリプトは他にもあり、マスターとワーカーを一気に立ち上げるものや、設定ファイルに記載のワーカーを一気に立ち上げるもの、それらを停止するものなどがあります。
- sbin/start-master.sh:マスターのプロセスを立ち上げる
- sbin/start-slaves.sh:設定ファイルに記載のワーカープロセス群を立ち上げる
- sbin/start-slave.sh:ワーカーのプロセスを立ち上げる
- sbin/start-all.sh:マスターとワーカーを同時に立ち上げる
- sbin/stop-master.sh:マスターのプロセスを停止する
- sbin/stop-slaves.sh:ワーカーのプロセスを停止する
- sbin/stop-all.sh:マスターとワーカーのプロセスを停止する
自分自身でクラスタを構築する場合は、ホスト名やポートなどを指定して各サーバ上でこれらのスクリプトを実行する必要があります。
停止したい場合は、下記のコマンドで終了させることができます。今回は引き続き立ち上げたクラスタを使っていくので、立ち上げたまま次に進みましょう。
sbin/stop-all.sh
spark-shellの実行
先ほど立ち上げたクラスタにspark-shellでつなげてみましょう(--masterのオプションにはマスターのURLを指定してください。マスターのURLは前述のWebUIで確認できます)。
./bin/spark-shell --master {マスターのURL}
下記のような表示が出てきたら、準備OKです。
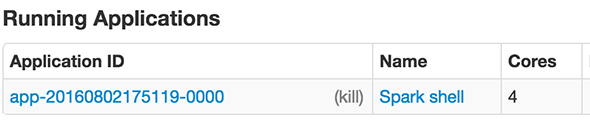
ちなみに、先ほどのWebUIの「Running Applications」にNameが「Spark shell」となっている行が追加されているはずです。
spark-shellで下記のScalaのコードを実行してみます。これは、1から1000の数値をそれぞれ2倍にした数値を足し上げる処理です。処理は、10のパーティションに分けています。パーティションとは並列実行可能なデータの単位です。
sc.parallelize(1 to 1000, 10).map(_*2).reduce(_+_)
早速、計算結果の数値が返却されたと思います。これくらいの計算量であれば、すぐに終わります。
では、ちょっと時間のかかりそうな処理に変更してみましょう。1000までではなくIntの最大値を指定してみます。
sc.parallelize(1 to 2147483647, 10).map(_.toDouble*2).reduce(_+_)
筆者の環境だと1分ちょっとかかりました。
このように計算量が多くなると、処理に時間がかかってしまいます。しかし、複数台のクラスタ上で実行した場合は、複数のノードで並列実行されますので、もっと早く終わることが期待できます。
関連記事
 知らないと大損する、Apache Sparkの基礎知識と3つのメリット
知らないと大損する、Apache Sparkの基礎知識と3つのメリット
社会一般から大きな注目を集めているIoT(Internet of Things)。だが、その具体像はまだ浸透しているとはいえない。今回は、IoTやビッグデータのキーテクノロジとして注目されている「Apache Spark」について、Sparkを製品に取り込んでいる日本IBMの土屋敦氏と、数多くの企業のデータ分析を担うブレインパッドの下田倫大氏に話をうかがった。 Sparkのエンタープライズ対応が「成熟」――Clouderaが宣言
Sparkのエンタープライズ対応が「成熟」――Clouderaが宣言
HadoopディストリビューターもあらためてSparkへの注力をアピール。既に800ノード超のSparkクラスターを運用するユーザーも存在するという。 Sparkは“誰”に例えられる?──多様化と進化を続ける「Hadoop」、人気急上昇「Spark」
Sparkは“誰”に例えられる?──多様化と進化を続ける「Hadoop」、人気急上昇「Spark」
先日、日本Hadoopユーザー会主催のイベントが開催されました。データベースと関係性が深いデータ分散処理プラットフォームである「Hadoop」と「Spark」の最近事情に迫ります。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。