Apache Sparkとは何か――使い方や基礎知識を徹底解説:Amazon EMRで構築するApache Spark超入門(1)(1/3 ページ)
本連載では、Sparkの概要や、ローカル環境でのSparkのクラスタの構築、Sparkの基本的な概念やプログラミングの方法を説明していきます。
はじめまして。コラビットの川原と申します。私は「HowMa」というサービスで、Apache Spark(以下、Spark)を利用した住宅価格の推定エンジンの開発を担当しています。本連載では、Sparkの概要や、ローカル環境でのSparkのクラスタの構築、Sparkの基本的な概念やプログラミングの方法を説明していきます。そして、簡単なアプリケーションを作成して、Amazon EMR(Elastic MapReduce)のクラスタ上で実行できるまで解説します。
これからSparkの導入を考えている方、または、業務で使う予定はないが少し興味がある方を対象に、サービス運用の中で得た知識を提供できればと思います。
Apache Sparkとは
Apache Sparkは巨大なデータに対して高速に分散処理を行うオープンソースのフレームワークです。JavaやScala、Pythonなどいろいろなプログラミング言語のAPIが用意されています。
Sparkは分散処理のややこしい部分をうまく抽象化してくれているので、簡潔なコードを実行するだけで、何百台ものコンピュータで、同時平行に計算を実行させることができます。
また、クラスタ上のデータをSQLで処理できる「Spark SQL」や、機械学習のための「MLlib」、グラフ処理のための「GraphX」、ストリーミング処理のための「Spark Streaming」など、便利なコンポーネントが付属しています。
なぜSparkは生まれたのか? Hadoopとの違い
分散処理のフレームワークといえば、Hadoopが有名です。
Hadoopは需要のあるツールでどんどん活用の場が増えてきましたが、そんなHadoopにも欠点があることがだんだん分かってきました。その欠点を補う形で登場したのがSparkです。
Hadoopの並列処理には下記のような欠点がありました。
- 個々のコンピュータのメモリをうまく活用する設計ではなかった
- 同じ処理を複数行う場合に、都度ストレージのアクセスが発生する
- 同じデータを何回も扱う場合にストレージのアクセスが発生する
最近、「機械学習」が人気ですが、まさに上記のような処理が必要です。機械学習の需要が高まるにつれて、上記の課題感も高まっていったと考えられます。
Sparkはそのような課題を解決するために生まれました。「Resilient Distributed Datasets」という分散共有メモリの仕組みがあり、データはパーティション化され、複数マシンのメモリで管理されます。
今まで、都度ストレージにアクセスしていたのが、インメモリで実行できるようになったわけです。
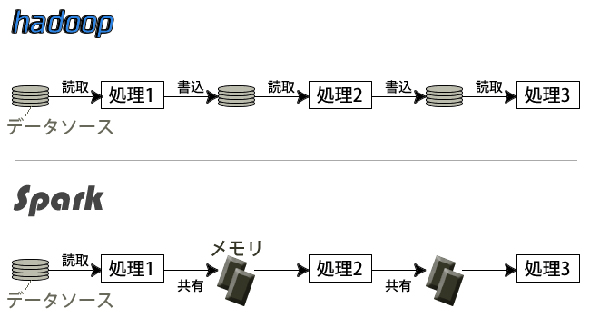 HadoopとSparkの違いについての概念図
HadoopとSparkの違いについての概念図Hadoopを超え、より高速にビッグデータを扱える分散処理エンジン。それがSparkなのです。
Spark導入にメリットのあるケース
Sparkは便利なツールですが宝の持ち腐れとならないように、自社の目的に沿った使い方ができるか、しっかりと考えた上で導入する必要があります。
下記に、判断基準となる項目を順番に説明します。
プロジェクトで扱うデータが大量である場合
Sparkはテラバイトはもちろん、ペタバイト級のデータ量も扱うことが可能です。1台のコンピュータで処理できないデータがある場合は、Sparkの出番です。
データの高速処理(リアルタイム性)を求められている場合
もし、計算処理が1週間ほどかかるものであっても、Sparkを活用すれば1時間で終わらせることが可能になります。こういった高速化によってビジネス上のメリットがあれば、ぜひ導入を検討しましょう。
Hadoopを既に使っている場合
SparkのアプリケーションはHadoopのYARN(Yet Another Resource Negotiator)クラスタ上でも実行できます。
今後は、JavaでMapReduce処理を書くのではなく、Sparkで書いた方が、簡潔かつ質の高い並列処理プログラムが作成できるはずです。また、HDFSのデータを分析することも可能です。「Hadoopから移行」ではなく、「Hadoopと共存」という形で導入できるのがSparkの良いところです。
大規模データを扱う機械学習を行う場合
小規模なデータであれば、Sparkを使わずに機械学習モデルを作っても十分でしょう。しかし、分析対象が大規模であれば、Sparkはオススメです。線形回帰やロジスティック回帰、クラスタリングなど、一般的な機械学習のアルゴリズムも備えています。大規模データの分析にぜひ、Sparkを役立ててみましょう。
どれにも該当しない場合
上記の理由が、現状、1つも当てはまらない場合は、もしかすると自社のプロジェクトでSparkを使うメリットはないかもしれませんが、今後、発生することを見越してぜひ、この連載を通してSparkを使ってみてください。
Apache Spark 2.0が2016年7月末にリリース
2016年7月末に最新版のApache Spark 2.0.0がリリースされました。
SQL 2003のサポートが追加され、処理のパフォーマンスも改善されました。また、「Structured Streaming」という新しい機能が利用できます。さらに、R言語での分析の範囲も広がりました。Sparkの機械学習のコンポーネントには「spark.mllib」「spark.ml」の2種類がありますが、前者が非推奨となったようです。
2.0というメジャーアップデートが行われたばかりなので、これから、Sparkを導入する場合は2.0を選ぶといいでしょう。
関連記事
 知らないと大損する、Apache Sparkの基礎知識と3つのメリット
知らないと大損する、Apache Sparkの基礎知識と3つのメリット
社会一般から大きな注目を集めているIoT(Internet of Things)。だが、その具体像はまだ浸透しているとはいえない。今回は、IoTやビッグデータのキーテクノロジとして注目されている「Apache Spark」について、Sparkを製品に取り込んでいる日本IBMの土屋敦氏と、数多くの企業のデータ分析を担うブレインパッドの下田倫大氏に話をうかがった。 Sparkのエンタープライズ対応が「成熟」――Clouderaが宣言
Sparkのエンタープライズ対応が「成熟」――Clouderaが宣言
HadoopディストリビューターもあらためてSparkへの注力をアピール。既に800ノード超のSparkクラスターを運用するユーザーも存在するという。 Sparkは“誰”に例えられる?──多様化と進化を続ける「Hadoop」、人気急上昇「Spark」
Sparkは“誰”に例えられる?──多様化と進化を続ける「Hadoop」、人気急上昇「Spark」
先日、日本Hadoopユーザー会主催のイベントが開催されました。データベースと関係性が深いデータ分散処理プラットフォームである「Hadoop」と「Spark」の最近事情に迫ります。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。