Windows 10に搭載されたLinuxサブシステムにおける、Windowsプログラムとの連携や日本語処理機能を検証する:Windows 10 The Latest(3/3 ページ)
WSLにおける日本語の扱い
Windows OSのコマンドとLinuxのコマンドを連結して処理する場合、気になるのが文字コードの扱いであろう。例えばファイル名やフォルダ名などが日本語の場合、その一覧をWSL上でファイルに保存すると文字コードは何になるのか? そのファイルの内容をWindows側コマンドで(リダイレクトなどで)読み出すと、どういう文字コードのデータが渡されるのか? そのあたりを見てみよう。
先に結論を述べておくと、WSL環境では文字コードは全て「UTF-8」になっていて、WSL上から呼び出したWindowsプログラムにも、UTF-8でテキストが渡されることになっている。
Linuxに限らず、ITやインターネットの世界では最近はUTF-8(=汎用文字コードである「Unicode」をバイトストリームとして扱うための符号化方式)が主流であり、WSLがUTF-8を使っていても何ら不思議ではないし、問題ではない。
だが日本語Windows OSでUTF-8を使うとなると、少し問題が起こる可能性がある。日本語Windows OSの場合、その前身であるMS-DOSの時代からシフトJISコードが標準として使われているからだ。
日本語Windows OSの文字コードを見ると次のようになっている。chcpはコードページ(=Windows OSにおける言語設定セットの番号のこと)を表示したり、変更したりするコマンドである。
 日本語Windows OSのコードページ
日本語Windows OSのコードページコードページ番号=932は、シフトJISを表す番号である。コードページ番号を切り替えると、日本語と英語などを切り替えることができる(TIPS「jp、usコマンドを利用する」参照)。
次は、WSLからコマンドプロンプトを呼び出して、そのコードページを調べてみよう。
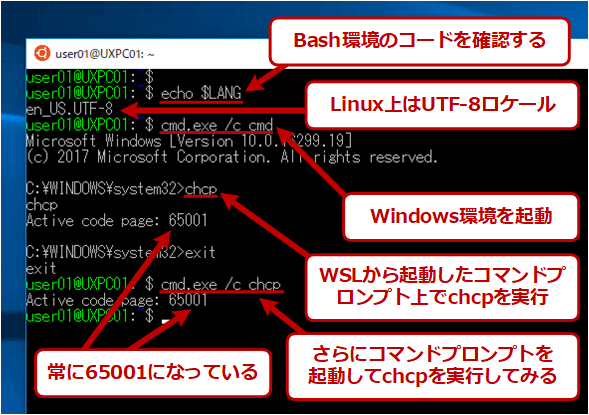 WSL環境のロケール/文字コード設定
WSL環境のロケール/文字コード設定いずれもコードページ番号=65001(UTF-8)となっていることが確認できる。
コードページがUTF-8になっていてもWindows OSのコマンドは動作するが、場合によっては結果が異なることがある。具体的には例えばdirコマンドなら、日本語で「ドライブ C のボリューム ラベルは WINDOWS10 です」と表示されていたものが、「Volume in drive C is WINDOWS10」のように英語メッセージになる。
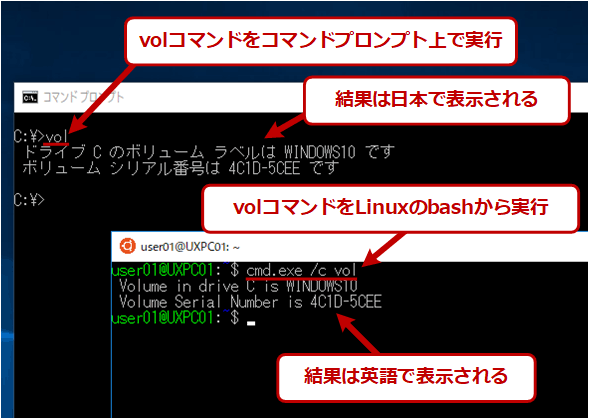 WindowsコマンドをUTF-8で使うと?
WindowsコマンドをUTF-8で使うと?コマンドプロンプト上で動作するCUIのWindowsコマンドをUTF-8環境で使うと、メッセージなどは全て英語のみとなる。そのため、いつも使っている日本語Windows OSとは、やや使い勝手が異なる。
WSLの言語設定とコードページの関係を図にすると、次のようになっている。
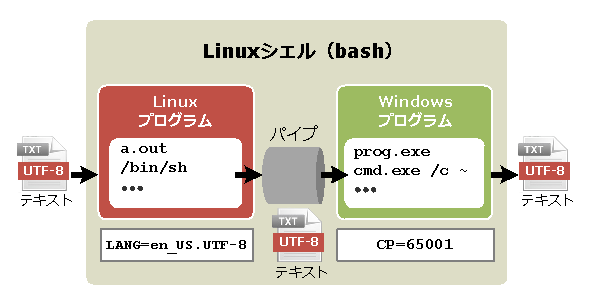 WSL環境における文字コードの扱い
WSL環境における文字コードの扱いWSLからWindows側のプログラムを呼び出した場合、そのプロセスはコードページ(CP)が65001(UTF-8)として実行される。通常の日本語Windows上のプログラムは932(シフトJIS)を想定していることが多いので、文字化けなどを引き起こす可能性がある。
Linux側の言語設定(ロケール)を確認したり、変更したりする方法についてはTIPS「Windows 10のBash on Windowsのロケールを英語モードに切り替える」を参照していただきたい。
日本語表示がUTF-8だとどうなる?
Windows OS日本語表示がUTF-8とはどういうことか、もう少し詳しく見てみよう。
まずWindowsのコマンドプロンプトを開いて次のコマンドを実行してみる。
※以下で利用している「jhd.exe」は、16進数でダンプするWindows向けのコマンド、「nkf -g」は文字コードを判定するコマンドである(TIPS「nkfツールで文字コードを変換する」も参照)。同等の機能を持つプログラムなら何でも可。
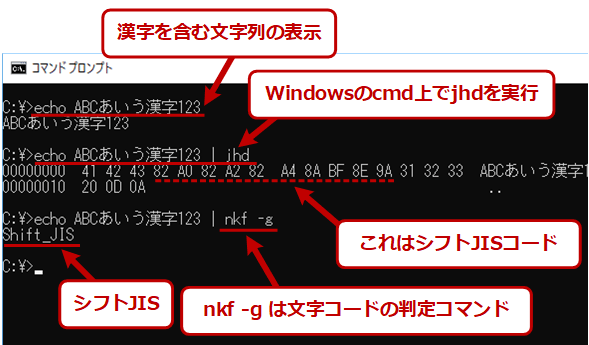 Windowsのコマンドプロンプト上での文字コードの確認
Windowsのコマンドプロンプト上での文字コードの確認echoコマンドで漢字を含む文字列を表示させ、それを16進数でダンプさせたり、nkf -gで漢字コードの種類を判別させたりしている。例えば「あ」は、シフトJISでは「82 A0」となる。
いずれもシフトJIS(コードページ=932)になっていることが分かる。
次はこのコマンドを、WSL(Ubuntu)上で実行してみる。
※od -t x1zは16進数でダンプするLinuxの標準コマンド。nkfは、Ubuntuなら「sudo apt install nkf」で導入できる。
 WSL上での文字コードの確認
WSL上での文字コードの確認このように文字コードはUTF-8になっている。
次は、WSL上からWindows OS側のコマンドを呼び出して実行してみる。
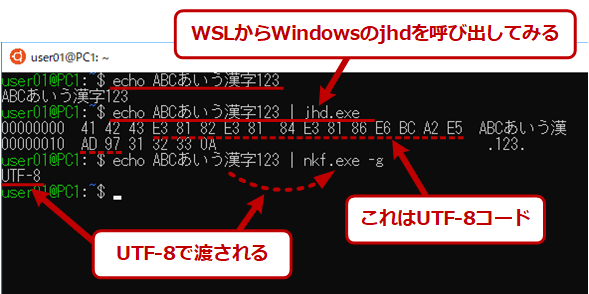 WSLからWindows側のコマンドを呼び出した場合の文字コード
WSLからWindows側のコマンドを呼び出した場合の文字コードこれから分かるように、Windows OS側のjhd.exeやnkf.exeには、シフトJISではなく、UTF-8で文字コードが渡されている。さらによく見ると、改行コードもWindows OS流の「0D-0A(CR-LF)」ではなく、Linux流の「0A(LF)」のみとなっている。
逆に、Windows OS側のコマンドの実行結果をWSL側に渡すと次のようになる。
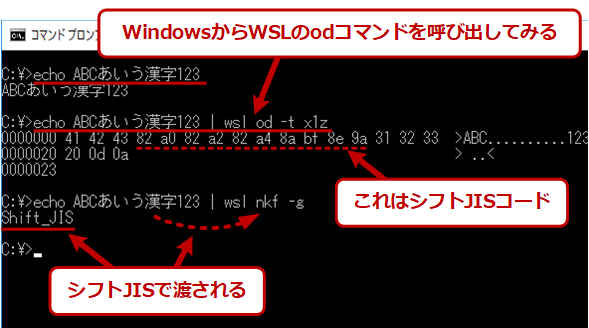 Windows側からWSLのコマンドを呼び出した場合の文字コード
Windows側からWSLのコマンドを呼び出した場合の文字コードWindows側ではシフトJISで表示しているが、パイプでWSL側のコマンドに送ると、WSL側にはシフトJISのデータが渡される。パイプ(やリダイレクト)では、文字コードは変換されない。
この場合は逆に、LinuxのコマンドにシフトJISの文字とWindows流の改行コードが渡されている。そのため、漢字文字の部分は正しく表示できなくなっている(コマンドプロンプトのコンソール設定はシフトJIS)。
以上をまとめると、次のようになっている。
- Windows(のコマンドプロンプト)上ではシフトJISがデフォルト。改行コードは「0D-0A」
- WSL(のシェル)上ではUTF-8がデフォルト。改行コードは「0A」
- パイプやリダイレクトでは文字コードや改行コードは変換されず、そのまま渡される
- Windows側からWSLのコマンドを呼び出した場合は、WSL側には、日本語テキストはシフトJISで渡される
- WSL側からWindowsのコマンドを呼び出した場合は、Windows側には、日本語テキストはUTF-8で渡される
もう1つ付け加えておくと、WSLのコンソールウィンドウはUTF-8に対応しているが、少なくとも現状のバージョンでは、UnicodeのBMP以外の文字(U+10000〜U+10FFFFにある、サロゲートペアの対象となる領域の文字)を表示することはできない(コマンドプロンプトウィンドウでも同様に表示できない)。これらの範囲のUnicode文字を利用したい場合は注意が必要だ(メモ帳やワードパッドなら表示できる)。
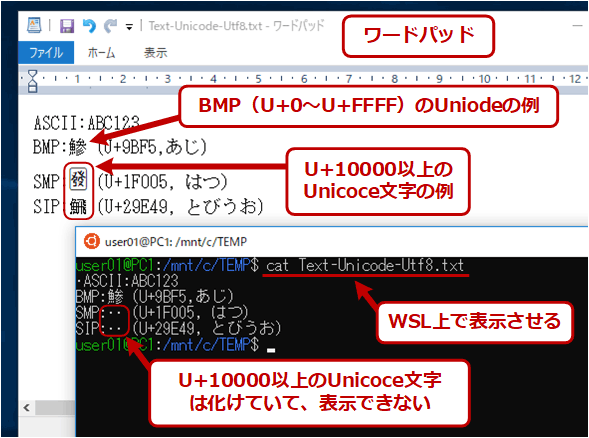 Unicodeのテキストを表示させてみる
Unicodeのテキストを表示させてみるU+10000以上のコードを含むUTF-8のテキストを表示させたところ。WSLのコンソールでは、BMP面(U+0〜U+FFFF)の文字は表示されているが、SMPやSIP面の文字は化けている。
Windows OSのコマンドにUTF-8を渡すと何が問題?
Windows OSのコマンド、特に日本語を扱うようなコマンドは、従来はほとんどの場合、シフトJISのみを対象としてきた。そのため、UTF-8の文字コードを渡されても正しく処理できないことが少なくない。
最近ではインターネットを中心にUTF-8が普及しているので、UTF-8に対応しているプログラムやシステムも増えてきている。パイプやリダイレクトの処理では、文字コード(および改行コード)は変換されないので、シフトJISのデータとして入出力したい場合は、文字コードをシフトJISに変換してから処理したり、保存したりするなどの対応が必要になるだろう。
なお、Windows OS側の文字コードをシフトJISではなく、UTF-8に統一するという方法もある。具体的にはコマンドプロンプト上で「chcp 65001」を実行する。だがこの設定を行うと、メッセージが英語になるだけでなく、今度はUTF-8のテキストしか表示できなくなる(シフトJISのテキストをtypeやmoreコマンドで表示できなくなる)。プログラムによってはシフトJISにしか対応しておらず、文字化けになったり、文字の検索や置換処理などが行えなくなったりするものも少なくない。このように、コンソール画面をUTF-8にする方法は、実用上問題が多い。
今回はWSLからWindows OSのコマンドを呼び出す方法や、その上で日本語テキストを扱う場合の文字コードの問題について見てきた。
WSLではLinux系のツールなどがそのまま使えるので、テキストデータ整理などにも活用したい、と思うだろうが、その場合は文字コードをどうするかについても考えておく必要がある。ただしこれはWSL固有の問題ではなく、複数の文字コードが混在したシステムや環境では常に考慮すべき事項である。シフトJISかUTF-8のどちらかに統一することになるが、現実的な利用シーンや今後の活用のことなどを考えると、なるべくUTF-8を使うことになるだろう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。