CNNなんて怖くない! その基本を見てみよう:作って試そう! ディープラーニング工作室(1/2 ページ)
画像認識などでよく使われるCNN(畳み込みニューラルネットワーク)ではどんなことが行われているのでしょう。図を見ながら、CNNの基本を理解しましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
前回は、全結合型のニューラルネットワークを使ってMNISTの手書き数字を認識してみました。今回は、CNNの基本について見た後で、PyTorchを使ってCNNで手書き数字を認識するコードを紹介します。
CNN(Convolutional Neural Network)の概要
前回は2次元の画像(手書き数字)を全結合型のニューラルネットワークを使って認識してみました。しかし、これには問題があります。入力層のノード数が28×28=784個だったことを思い出してください。これが意味するのは、2次元の構造を持っていたデータが1次元のデータに展開されてしまったということです。

2次元の画像データでは、あるピクセルとその周辺のピクセルとの関係は重要な情報です。MNISTはグレースケール(白黒)の画像を集めたデータセットで、背景が黒、数字が白として表現されていました(ここでは単純化して白と黒としていますが、実際には0〜255の値で、白が強くなるほど数値は大きくなります)。となると、どこかのピクセルが白であれば(数字を表すピクセルのいずれかであれば)、その周辺も数字の一部である=隣接するピクセルが白である可能性が高くなります(1点のピクセルだけが白というのは、数字においてはあまりないでしょう)。もちろん、数字と背景の境界辺りでは、周りに黒いピクセルもあるでしょうし、実際にはそのような白いピクセルと黒いピクセルとの関係が数字の「特徴」を表すことになります。
 白いピクセルの周辺には白いピクセルがある可能性が高い
白いピクセルの周辺には白いピクセルがある可能性が高い全結合型のニューラルネットワークでは、こうした情報を無視して、全てを1次元のデータとして、学習したり、テストしたりしていました。
そうではなく、これらの情報を加味して処理をするニューラルネットワークを作成するにはどうしたらよいでしょう。これを実現するためによく使われているのが、今回紹介するCNN(Convolutional Neural Network、畳み込みニューラルネットワーク)と呼ばれるものです。
CNNでは2次元のデータを小さな区分に分割して、それらと何らかの特徴を表すデータとを比較しながら、元のデータがどんな特徴を含んだものであるかを調べていきます。この「何らかの特徴を表すデータ」のことを「カーネル」「ウィンドウ」「フィルター」などと呼ぶことがあります。ただし、本稿ではPyTorchのドキュメントで一般に使われている「カーネル」という語を使うことにします。
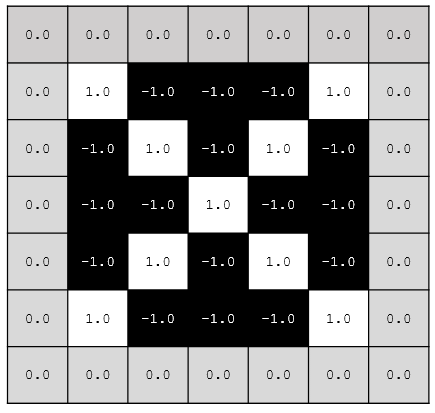
話を少し単純にするために、ここでは5×5ピクセルの×と○を画像データとして考えましょう。ここで-1.0は黒を、1.0は白を表すものとします。

ここで×のデータにはどんな特徴があるでしょう。
- 右下がりの直線(\)がある
- 左下がりの直線(/)がある
- それらが交差する(×)
○のデータは、それを八角形のようなものだと近似すれば、次のような特徴を持つといえるかもしれません。
- 右下がりの直線(\)がある
- 左下がりの直線(/)がある
- 横線(−)がある
- 縦線(|)がある
カーネルはこのような特徴を表すもので、画像データ(を分割した小さな部分)にどんな特徴が含まれているかを調べるために使われます。
ここで、(実際には)カーネルが保持するデータ(特徴)は人間が指定する必要がない点には注意してください。CNNでは「ある画像がどんな特徴を持つかをニューラルネットワークが学習してくれる」というわけです。実際には、CNNからの出力は(後述するプーリングや活性化関数などによる処理を経て)全結合を行うネットワークに接続され、そこで画像が何であるかの推測が行われるのですが、それについてはまた後で見ることにしましょう。その前に、CNNの「C」つまり「Convolution」「畳み込み」がどんな処理なのかを見てみます。
畳み込み
CNNは「畳み込みニューラルネットワーク」のことですが、ここでは実際にどんな処理(畳み込み)が行われるのでしょうか。先ほどは、画像データを小さな区分に分割して、それとカーネルを比較すると述べました。これをもう少し詳しく見てみます。
カーネルは3×3、5×5などの小さな2次元データと考えてください。ここでは3×3というサイズの2次元配列(テンソル)とし、これと先ほどの×のデータを例として、どんなことが行われるかを紹介しましょう(カーネルの値は学習により得られたものだと考えてください)。

カーネルは見ての通り、画像データに交差している箇所があるかどうか調べるために、×のデータの中央部と同じようなデータになっています。
まず画像データにカーネルを適用するときには、その左上から右下に向かって、カーネルのサイズと同じサイズのデータを取り出して、それとカーネルを使って行列の演算を行っていきます。そして、その結果をCNNからの出力に左上から並べていきます。

このような画像データの区画とカーネルとの演算を行った結果を出力としていく処理が「畳み込み」です(1つの新しいデータの中に、複数のデータが持つ情報を含めていくこと)。この出力を「特徴マップ」と呼ぶこともあります。これは畳み込まれたデータが、元の画像データの特徴を表しているからです(後述)。
また、上の図を見ると分かりますが、畳み込みにより、出力データのサイズが元の画像データよりも小さくなっていることに注意してください。5×5の画像データと3×3のカーネルを使って計算をすると、計算結果(特徴マップ)のサイズは3×3となります。このようなデータサイズの減少を避けたり、画像データの端にあるデータを使った畳み込み処理の回数を増やしたりするなどの目的で画像データの上下左右に「パディング」と呼ばれる要素(値は一般に「0」のことが多い)を付加することもあります。
 元データにパディングを付加したもの
元データにパディングを付加したもの畳み込みの際には、カーネルの各要素と、画像データからピックアップした区画において、同じ位置にある要素同士を乗算して、それらの和を出力値とします。例えば、画像データの左上の区画とカーネルとの処理であれば、次のようになります(ここでは、カーネルの要素の値は赤字で表示しています。また見やすくなるよう、少し背景色を変更しています)。

パディングをしていれば、次のようになります(総和を取ると「4」になります)。

左上の要素とカーネルとの処理が終わったら、カーネルを右に1つズラして、同じ処理を行います。この適用結果がCNNの左上から2番目のデータとなります(カーネルをどれだけズラすかを「ストライド」と呼びます。ここでは1つズラす=ストライドは1、としていますが実際にはその幅は指定できるのが一般的です)。

このようにして左上から右下に向かって、画像データにカーネルを適用すると最終的には次のような結果(特徴マップ)が得られます(パディングを入れた場合と入れない場合を計算しました)。以下では負の値は背景色をグレーとして、正の値は背景色を赤として表示しました(値が大きいほど濃い色)

パディングがない場合の出力が、パディングがある場合の出力の中央にあることに注意してください。
ところで、先ほど「畳み込まれたデータが、元の画像データの特徴を表している」と述べましたが、これはどういう意味でしょうか。ここではカーネルは×という記号の交差点を探すためのデータでした。そして、画像データでは、交差する箇所は中央にありました。そこで特徴マップを見ると、中央のデータが「9」と最大の値になっています。
これは「交差する」という特徴が、画像データでは中央にあることを示していると考えられます。出力の値がマイナスになっている箇所(パディングなしの計算結果の上部中央など)は、そうした特徴が見られないということです。それ以外の場所(同じくパディングなしの計算結果の左上や右下など)はある程度はそうした特徴も見えるが、完全にそうともいいきれないような場所です。実際、画像データの四隅には斜めの直線はあるけれど、交差はしていないので、交差という特徴の一部は示していると考えられます。このように値の大きさで、カーネルが表す特徴が画像のどこにあるかを示すのが特徴マップです。
このように、カーネルという小サイズの特徴を検索する道具を用いることで、元となった画像データから何らかの特徴を探し出すことができます。このときに注目したいのは、「現在探している特徴が元データのどこにあっても、それを見つけ出せる」点です。
ここで使っているサンプルデータでは、5×5のデータで対角線の値を1.0とすることにより×を表していました。しかし、これが上下あるいは左右にズレても、カーネルを使ってデータの全体をくまなく見ていくことで、交差する箇所を見つけ出せます。これはMNISTのような手書き数字にもいえます。すなわち、カーネルを使って28×28のサイズの全ピクセルをくまなく走査していくことで、数字を含んだ画像データから特徴を拾い出せるということです。
ここではカーネルは交差を探すためのものが1つだけでしたが、右下がりの直線、左下がりの直線、横線、縦線などを表すカーネルがあれば、それらを組み合わせることで、×と○を含んだ画像をCNNに入力すると、それらの特徴を含んだ特徴マップが得られることは想像できるでしょう。そして、CNNは多数の入力データを基にカーネルが特徴をうまく示すものとなるように、その重みやバイアスを学習していくというわけです。なお、これらのカーネルの数のことを「チャネル」と呼ぶことがあります。
PyTorchでは今述べたような処理を行うためのクラスとしてConv2dクラスが提供されています。
そして、CNNにおいてはもう1つ「プーリング」と呼ばれる重要な処理があります。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。