「Stable Diffusion」で生成された画像とプロンプトがどのくらい似ているのかを確認してみよう:Stable Diffusion入門
Stable Diffusionは内部でCLIPと呼ばれるモデルを使用しています。CLIPを使うと何ができるようになるのかを見てみましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
前回はStable Diffusionでノイズから画像が生成される過程を確認しました。今回は少し方向性を変えて、CLIP(Contrastive Language-Image Pre-Training)と呼ばれ、Stable Diffusionの内部でも使われている「テキストとイメージ(画像)の組を基に学習を行ったモデル」について見てみます。

今回もコードはGoogle Colabのノートブックとして公開することにしました(かわさき)。

CLIPは、OpenAIという組織が2021年1月5日に「DALL・E: テキストから画像を生成」と同時に発表した技術で、AIエンジニアやデータサイエンティストの間では有名ですね。OpenAI公式ページでは「CLIP: テキストと画像をつなぐ」というタイトルの記事が公開されています(一色)。
Stable Diffusion(をラップしたDiffusersのStableDiffusionPipelineクラス)では、CLIP(CLIP ViT-L/14)を利用してプロンプトを「埋め込み表現」と呼ばれる「単語や文の意味をn次元空間に埋め込んだベクトル」に変換し、それを潜在表現(latent representation)と一緒に画像生成用のモデル(U-Net)へと入力するようになっています。
txt2img.pyファイルのコードと等価な処理かどうかは、両方のコードの見た目がずいぶんと異なっているのでちょっと確認できていません。ざっくりと見分けるのであれば、同じ設定でtxt2img.pyファイルとStableDiffusionPipelineクラスに画像を生成させて、その結果を確認するという方法があるかもしれませんね。
まずCLIPでどんなことができるのかを簡単に確認してみましょう。なお、ここではベクトルのコサイン類似度を簡単に確認できるsentence_transformersが提供しているclip-ViT-L-14モデルを使用することにします。これを利用して生成される埋め込み表現が、StableDiffusionPipelineクラスで実際に生成される埋め込み表現と異なる可能性があることには注意してください。それでも、CLIPにどんなことができるのかは十分に理解できるはずです。
今回もGoogle Colabのノートブックを使っているので、以下のように先頭に「!」付けて「pip install transformers scipy ftfy diffusers sentence_transformers」コマンドを実行しておきましょう。

埋め込み表現とコサイン類似度
次にCLIP ViT-L/14モデル(これは恐らく「Vision Transformerを使用した巨大サイズのCLIP、パッチレベル14」という意味です)を利用したモデルをインスタンス生成します。
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('clip-ViT-L-14')
なお、 先頭行ではutilモジュールをインポートしていますが、このモジュールにはコサイン類似度を計算するcos_sim関数が含まれています。
モデルを生成したら、さっそく簡単な単語から埋め込み表現を作ってみましょう。
dog = 'a dog'
dog_emb = model.encode(dog)
print(dog_emb)
print(dog_emb.shape)
埋め込み表現を作成するにはモデルのencodeメソッドに文字列(テキスト、プロンプト)を渡すだけです。ここでは「a dog」という2語を渡しています。最後の2行では返された埋め込み表現とそのサイズを表示しています。

数多くの浮動小数点数値が表示され、768次元(1行768列)であることが分かりました。
「Stable Diffusion with Diffusers」で示されている以下の図を覚えている方がいれば、上の形状(1行768列)がStable Diffusionが内部で使用している埋め込み表現とは異なっていることに気付くかもしれませんね。
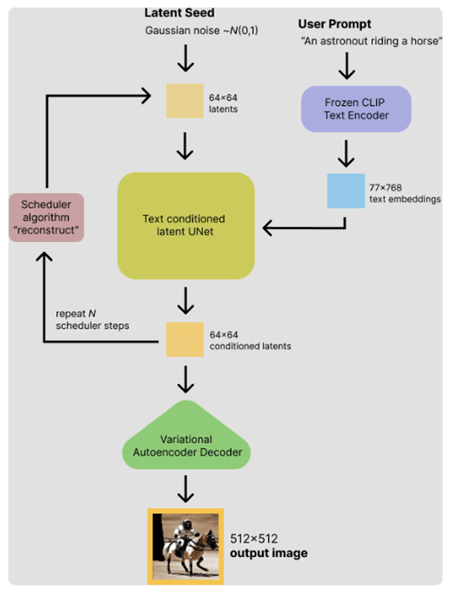 Stable Diffusionの動作原理
Stable Diffusionの動作原理この動作原理ではプロンプトからは77行768列の埋め込み表現が作られることになっています。しかし、ここではCLIPによりどんなことができるのかを見るだけなので、このまま話を続けることにしましょう。
ここで作成した埋め込み表現は、「a dog」というテキストがどのような意味を持つかが768次元空間のいずれかの座標にマッピングすることで表現されているものと考えられます。また、これと似た意味を持つテキストは768次元空間の中で近い位置に存在します。それがどのくらい似ているかを示すのが先ほども出てきた「コサイン類似度」です。
コサイン類似度は2つのベクトル(ここでは768次元ベクトル)がどれくらい似ているかを示すもので「1に近いほど2つのベクトルはよく似ていて、0に近いほど2つのベクトルは無関係であり、-1に近いほど2つのベクトルはよく似ていない」といったことがいえます。
というわけで、犬の「反対」っぽい猫(a cat)の埋め込み表現を作って、2つの埋め込み表現がどのくらい似ていないか(または似ているか)を確認してみましょう。
cat = 'a cat'
cat_emb = model.encode(cat)
後はこれをutilモジュールのcos_sim関数に渡すだけでコサイン類似度を計算できます。
similarity = util.cos_sim(dog_emb, cat_emb)
print(similarity)
結果はどんなものでしょうか。
 「a dog」と「a cat」のコサイン類似度は「0.9177」!
「a dog」と「a cat」のコサイン類似度は「0.9177」!何と「a dog」と「a cat」のコサイン類似度は「0.9177」になりました。先ほどもいいましたが、コサイン類似度は1に近いほど、2つのベクトルが似ていることを意味します。CLIPは単に「犬←→猫」という概念だけではなく、哺乳類であるとか、生物であるとか、そんなことまでを768次元空間の中で表せるようになっているのかもしれません。そうなると、無関係なもの、あるいは全く似ていないものを考えつくのもなかなか難しいものです。
画像の埋め込み表現
上で見た通り、CLIPはテキストから埋め込み表現を作成することもできますが、画像を基にその意味を表す埋め込み表現も作成できます。そして、2種類の埋め込み表現をcos_sim関数に渡して、それらのコサイン類似度を計算することも可能です。
なるほど、CLIPを使えば「テキストの埋め込み表現」と「画像の埋め込み表現」を同じように作成できるのですね。同様の埋め込み表現を使えることこそがOpenAIの公式ページのタイトルにあった「テキストと画像をつなぐ」ための鍵になっている、という理解で合っていますかね。そこで今回の記事では、テキストの埋め込み表現と画像の埋め込みが実際にどれくらい似ているかを幾つかの例で調べてみたというわけですね。
そこで、画像から埋め込み表現を作成してみます。これにはPILモジュールのImageクラスを使うのが簡単です。筆者は紅葉の写真と桜の写真を選んで、Colabにアップロードしています。アップロードするにはColabノートブックの左側に並んでいる[ファイル]アイコンをクリックして、[セッション ストレージにアップロード]ボタンをクリックした後に、アップロードするファイルを選択するだけです。ただし、セッションストレージにアップロードした画像ファイルはノートブック環境が回収されるときに削除されてしまうので、ノートブックのこの部分を試すときにはご自分で適当な画像をアップロードして名前を修正し、比較対象のテキストも適宜修正する必要があります。
本稿のノートブックには紅葉と桜の2枚の画像が含まれているので、それらをダウンロードしてから、[セッション ストレージにアップロード]ボタンを使ってアップロードし直すのが簡単かもしれません。
 ファイルのアップロード
ファイルのアップロードアップロードができたら、まずは写真ファイルを読み込みます。
from PIL import Image
sceneries = [Image.open(f'sample_{num}.jpg') for num in range(2)]
sceneries[0]
sceneries[1]
実行結果を以下に示します。紅葉の写真は以下の通りです。

そして、以下が桜の写真です。

このモデルでは画像を埋め込み表現に変換するのもencodeメソッドを呼び出して、読み込んだ画像を渡すだけです。ここでは2つの写真があるのでリスト内包表記を使っています。
sceneries_embs = [model.encode(sceneries[num]) for num in range(2)]
print(sceneries_embs[0].shape)
後はこれらをテキストの埋め込み表現とのコサイン類似度を計算するだけですが、先ほどの「a dog」「a cat」ではなく、ここでは以下のようにそれっぽい表現のテキストを用意しました。
text0 = 'red leaves in a park'
text1 = 'cherry blossoms in blue sky'
text2 = 'a stray cat on a street'
sentence_list = [text0, text1, text2]
sentence_embs = [model.encode(item) for item in sentence_list]
最後に2枚の写真(の埋め込み表現)それぞれについて、上のテキスト(の埋め込み表現)とコサイン類似度を計算するだけです。
similarities = {}
for key, emb in zip(['red leaves', 'cherry blossom'], sceneries_embs):
similarity = util.cos_sim(emb, sentence_embs)
similarities[key] = similarity
for k, v in similarities.items():
print(f'{k}: {v.tolist()[0]}')
ここでは3つのテキストの埋め込み表現をまとめたリストをutil.cos_sim関数に渡していますが、こうすると一度にまとめてコサイン類似度を計算してくれます。その結果を辞書に格納して(キーは紅葉を表す「red leaves」と桜の花を表す「cherry blossom」としました)、それぞれの計算結果を表示しています。

「a dog」と「a cat」のコサイン類似度と比べると、ずいぶんその値は低くなっていますが、紅葉の写真については「red leaves in a park」というテキストが、桜については「cherry blossoms in blue sky」というテキストが一番よく似ている結果になっています。これはまずまずの結果といえるのかもしれませんね。
Stable Diffusionで作成した画像とそのプロンプトを比較してみる
最後にちょっと長めのプロンプトをStable Diffusionに渡して画像を生成してもらい、画像とその生成に使用したプロンプトのコサイン類似度を計算してみます。
ここではプロンプトは「a photo of a knight armed with a long sword, sitting on a rock, in a forest」(ロングソードを持っている騎士が森の中で岩に座っている写真)としました。また、前回と同様に、ここではDiffusersのStableDiffusionPipelineクラスを用いています。これを使って画像を生成する手順については前回の記事を参照してください。
以下に画像を生成するコードを示します。
import torch
from diffusers import StableDiffusionPipeline
YOUR_TOKEN = 'hf_XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' # 自分のトークンを設定
pipe = StableDiffusionPipeline.from_pretrained('CompVis/stable-diffusion-v1-4',
use_auth_token=YOUR_TOKEN)
pipe.to('cuda')
prompt = 'a photo of a knight armed with a long sword, sitting on a rock, in a forest'
generator = torch.Generator('cuda').manual_seed(2)
image = pipe(prompt, guidance_scale=7.5, num_inference_steps=50,
generator=generator).images[0]
image
実行結果を以下に示します。

筆者的にはまずまずの画像だと思いますが、コサイン類似度はどんな感じになるでしょう。
def calc_cos_score(image, prompt):
img_emb = model.encode(image)
text_emb = model.encode(prompt)
cos_scores = util.cos_sim(img_emb, text_emb)
return cos_scores
calc_cos_score(image, prompt)
ここではコサイン類似度を計算する関数を定義して、それを呼び出すようにしました。関数内で行っているのは既に見た通りの処理です。実行結果を以下に示します。

あれ? 「0.3036」と思ったよりもコサイン類似度が低いような気がします。0.9とはいわないまでも0.6くらいは出そうな期待感を持って実行してみたのですが。
そこで、guidance_scaleに強めの値を指定してみることにしました。これは指定したプロンプトに対する忠実度というか、画像生成時にプロンプトの影響力を強める値です。これに「20」を指定してみましょう。
generator = torch.Generator('cuda').manual_seed(2)
image = pipe(prompt, guidance_scale=20, num_inference_steps=50,
generator=generator).images[0]
image
実行結果を以下に示します。

変わったといえば変わりましたが、コサイン類似度にはそれほど差は出そうもない気がします。先ほど定義した関数を呼び出してみましょう。
 実行結果
実行結果うーむ。少しは高くなりましたが、やはりコサイン類似度が1に大きく近づくことはありませんでした。guidance_scaleを強めにするというのは、StableDiffusionPipelineクラスの実装では次の部分に関係をしています。
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
簡単に説明をすると、guidance_scaleが1より大きいときには「classifier free guidance」と呼ばれる処理が行われます。これはプロンプトで条件付けをした上で除去されるノイズを予測した結果と、プロンプトなしで除去されるノイズを予測した結果から最終的なノイズを予測するといった処理を行うようです。上のコードを見ると、これは実際にはguidance_scaleの値が「プロンプトを基に予測されたノイズとプロンプトなしで予測されたノイズの差」の値に乗算されるようなコードになっています。
こうすることで先ほども述べたようにプロンプトの影響力が強まる(忠実度が上がる)結果になるようです。ですがだからといって、影響力が高まるとコサイン類似度が大きく1に近づくというわけでもないようです。これは、画像の埋め込み表現を得る際に、人の目には見えないような多数の情報が768次元の空間に織り込まれるからかもしれません。
ノートブックにはguidance_scaleの値を変化させながら、画像を生成し、それらとプロンプトのコサイン類似度を計算するコードもあるので興味のある方はご覧ください。
今回の記事で何が重要かといえば、CLIPはテキストと画像の両者から互換性のある埋め込み表現を得ることができることと、それ故に画像生成に利用するプロンプトから埋め込み表現を得れば、それを画像生成時にどんな画像にするかの条件付けに利用できるということです。埋め込み表現がテキストと画像の橋渡しとなったことで、Stable Diffusionに代表される画像生成AIが大きく進化することになったといえるでしょう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。