JSPで特殊文字が文字化けする場合の対処方法:Javaの文字化け対策FAQ(2)
JSP/サーブレット・プログラミングで誰もが一度は遭遇するトラブルが文字化けだ。予期せぬ文字化け発生に、デバックに苦労した経験を持つ読者も多いだろう。本連載では、JSP/サーブレットにおける文字列の扱いの基礎を復習した上で、文字化けの解決策を要点よく解説していく予定だ。(編集部)
本記事は2005年に執筆されたものです。Javaの文字化け全般の最新情報は@IT Java Solution全記事一覧のカテゴリ「トラブル・問題解決/ノウハウ/文字化け」をご参照ください。
質問1:「①②」「ⅠⅡ」「㍉㌔」などが文字化けします
解答:文字コードとしてシフトJIS(Shift_JIS)の代わりにWindows-31Jを指定しましょう
Windows環境で標準的に用いられている文字コードは、正確にいうと「Shift_JIS」ではなく、Shift_JISを拡張した「Windows-31J」と呼ばれるWindows標準文字セットである。JavaではJDK 1.2以降で「MS932」という名称でサポートされており、JDK 1.4.1以降はWindows-31JというIANAの正式名称でも利用可能になっている。
このWindows-31Jは、以下のようなWindows固有の機種依存文字を含んでいるのが特徴だ。
一方、MacintoshなどWindows以外のOSにおける「Shift_JIS」は、Windows-31Jとは異なる文字集合をサポートしている。例えばWindowsにおける①の文字コードは0x8740であるが、Macintoshでは同じ文字コードに「(日)」というMac機種依存文字が割り当てられている。こうした状況であるため、HTMLページやJSPページに不用意にWindows機種依存文字が含まれていると、ほかの環境ではたいていの場合文字化けしてしまう。よって不特定多数を対象とするWebサイトではそうした機種依存文字を使用しないのが原則である。
しかし、要件上コンテンツ内でWindows機種依存文字を使用せざるを得ないときは、Shift_JISの代わりにWindows-31Jを指定することで文字化けを回避可能なケースもある。例えば、Mac OS Xに搭載されているWebブラウザSafariでは、文字コードとしてWindows-31Jが正しく指定されていれば、Windows機種依存文字も表示可能である。
■JSPファイルの文字コードは?
Shift_JISとWindows-31Jの違いは、JSPファイルの作成にも影響する。例えばTomcatでは、Windows機種依存文字を含むJSPファイルの文字コードをShift_JISとして指定した場合、たとえクライアントがWindowsであっても文字化けが起こってしまう(4.1.31および5.0.28で確認)。
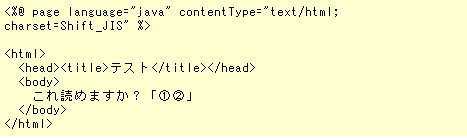
上記のコードを実行した結果が次の画面だ。
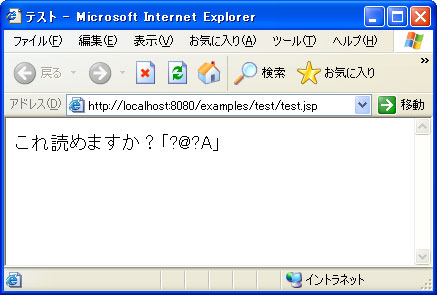 図1 JSPにおけるWindows機種依存文字の文字化け
図1 JSPにおけるWindows機種依存文字の文字化けでは、なぜこうした現象が発生するのだろうか。このJSPファイルより生成されたサーブレット・クラスのソースコード(デフォルトではUTF-8)をのぞいてみると、すでにこの時点で文字化けしていることが分かる。
out.write("<body>\r\n これ読めますか?「?@?A」\r\n");
第1回「Webブラウザが文字コードを判定する基準は?」で説明したとおり、サーブレット・コンテナはpageディレクティブのpageEncoding属性(省略時はcontentType属性)で指定された文字コードでJSPファイルを読み込み、JVM内部の文字コードであるUnicodeへの変換を行う。しかし文字コードとしてShift_JISを指定すると、Windows機種依存文字を正しく変換できないのである。
この問題を解決するには、pageディレクティブにおいて「Windows-31J」を指定すればよい。これにより、①や②といったWindows機種依存文字も表示可能になる(ただし、Windows-31Jを指定する際は次のセクションで説明する“副作用”に注意する必要がある)。
質問2:「〜‖‐¢£¬」などが文字化けします
解答:各種文字コードとUnicodeの間の変換ルールを見直しましょう
周知のとおり、Javaではすべての文字列をUnicodeとして処理している。よってJVMが外部に対して文字列を入出力する際には、多くの場合、Unicodeと各種文字コード間の相互変換が必要になる。特にWebアプリケーションに限っていえば、主に以下のような状況で相互変換が実施されている。
- JSPファイルがサーブレット・コンテナに読み込まれるとき
- Webブラウザからリクエストを受信するとき
- Webブラウザにレスポンスを送信するとき
- データベースやファイルにアクセスするとき
- メールを送受信するとき
「〜‖‐¢£¬」などの文字化けは、こうした相互変換における「Unicodeと各種文字コード間の変換ルールの違い」によって発生するものだ。まずは表1をご覧いただきたい。
| 変換元の文字コード | Shift_JIS EUC_JP ISO-2022-JP |
Windows-31J |
|---|---|---|
| 〜(WAVE DASH) | U+301C | U+FF5E |
| ‖(DOUBLE VERTICAL LINE) | U+2016 | U+2225 |
| ‐(MINUS SIGN) | U+2212 | U+FF0D |
| ¢(CENT SIGN) | U+00A2 | U+FFE0 |
| £(POUND SIGN) | U+00A3 | U+FFE1 |
| ¬(NOT SIGN) | U+00AC | U+FFE2 |
| 注:主要な文字を抜粋したものであり、すべての文字を網羅した表ではありません。 | ||
この表が示すように、これらの文字についてのWindows-31JとUnicode間の変換ルールは、そのほかの文字コードに用いられる変換ルールとはまったく異なる。よって、Windows-31Jとそのほかの文字コード(Shift_JIS、EUC_JP、ISO-2022-JPなど)の両方を扱わなくてはならないJavaアプリケーションでは、この問題が表面化しやすいのである。
例えば以下のようなJSPファイルを考えてみよう。

Tomcatでは、このJSPファイルを表示すると図2のように文字化けする(4.1.31および5.0.28で確認)。
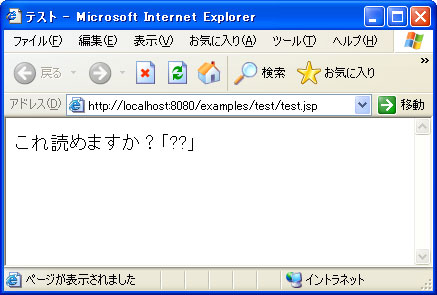 図2 Unicode変換ルールの違いによる文字化け
図2 Unicode変換ルールの違いによる文字化けこれは次のようなメカニズムで発生する。Tomcatは、JSPファイルがWindows-31J(pageEncoding属性で指定)で作成されたものとしてUnicodeに変換する。よって「〜」はUnicodeのコードポイントU+FF5Eに変換される。一方、同ファイルの内容をWebブラウザに出力するとき、TomcatはUnicodeからShift_JIS(contentType属性で指定)への変換を実施する。しかし、この変換ではU+FF5Eを「〜」に戻すルールが規定されていないので、図2のように「??」と化けてしまうのだ。
これと同様の現象は、Webブラウザからリクエスト・パラメータを受信する際をはじめ、ローカル・ファイルやデータベースへのアクセス、メールの送受信時にも発生することがある。これについて詳しくは次回に説明する予定だ。
■JDK 1.4.0以前のShift_JISのエイリアス問題
ちなみにJDK 1.2からJDK 1.4.0までのJVMでは、「Shift_JIS=MS932(Windows-31J)」というエイリアス設定が行われていた。そのため、Shift_JISとWindows-31Jを別物として扱うことさえできず、上述のマッピングの問題が常にJava開発者の悩みのタネとなってきたのである。JDK 1.4.1以降では、少なくともこの両者を区別できるようになり、問題をより回避しやすくなっている。
こうしたUnicode変換時の問題については、風間氏のWebサイトで詳細に解説されているので参考にしていただきたい。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。