Oracleのバックアップ/リカバリの仕組みとは?:ORACLE MASTER Silver DBA講座(21)(1/2 ページ)
ORACLE MASTER資格の中級に位置付けられ、取得すればOracle技術者としてグローバルに認定される「ORACLE MASTER Silver Oracle Database 10g」。例題を利用してポイントを押さえ、確実な合格を目指そう!
前回「Oracleでの問題発生を予防する」で、予防的メンテナンスについて学びました。今回は、バックアップとリカバリの概要を紹介しましょう。
バックアップ/リカバリの概要
ポイント
Oracleサーバで発生する可能性のあるエラーの種類と、インスタンス障害のリカバリが対象です。バックアップの取得に関しては、次回取り上げる「データベースのバックアップ」で解説します。バックアップをリストアしてリカバリするメディアリカバリについては、「データベースのリカバリ」で解説します。
障害タイプと解決方法
Oracleサーバで発生する可能性のある障害とその解決方法には、次のものがあります。
- 文障害
SQL文としては正しいけれども、Oracleサーバのルールに基づき、実行エラーとなってしまうことです。次のような問題と解決方法があります。
| 問題 | 解決方法 |
|---|---|
| 無効なデータ | 制約違反、データ型の不一致、データ最大長の超過などが原因です。データを検証し、修正します。 |
| 権限不足エラー | 適切なオブジェクト権限、システム権限を付与します。 |
| 領域不足エラー | 表領域の空き領域不足、エクステントの拡張エラー、領域割り当て制限(QUOTA)超過が原因です。必要な領域を追加します。また、再開可能領域割り当て機能を使用することで、領域不足時に処理を一時停止させ、解消時に再開させることも可能です。 |
- ユーザープロセス障害
ユーザープロセスが異常終了してしまうことです。クライアント側のリソース不足によるプロセスの終了、Oracleサーバとのネットワークの切断によるセッションの終了などが考えられます。
ユーザープロセス障害の解決は、Oracleサーバ側のサーバプロセスのクリーンアップで対応します。サーバプロセスのクリーンアップは、PMONバックグラウンドプロセスにより自動的に行われるため、データベース管理者による特別なアクションは必要ありません。PMONバックグラウンドプロセスは、トランザクションをロールバックし、ロックを解放します。
- ユーザーエラー
ユーザーが誤ったトランザクションをCOMMITしたり、誤ってテーブルを削除、切り捨ててしまったりすることです。SQL文としては正しいため、Oracleサーバは渡されたSQL文を正しく実行します。その結果、必要なテーブルが削除されたことにより、システムとしては問題のある状態になってしまいます。
ユーザーエラーの解決は、操作を行う前の状態にすることで図れます。フラッシュバックテーブル、フラッシュバックドロップ、フラッシュバックデータベースといったフラッシュバックリカバリ機能か、データファイルのバックアップを使用して、過去の一時点までのリカバリ(Point-in-timeリカバリ)を行います。
誤った操作が行われた時間を識別するために、LogMinerユーティリティが使用できます。LogMinerでは、REDOログファイルから、実行されたSQL文、実行したユーザー、実行した時間などを確認することができます。
- インスタンス障害
バックグラウンドプロセスが異常終了したり、データベースファイル以外のハードディスク障害が発生したり、強制終了(SHUTDOWN ABORTを含む)したりすることです。
インスタンス障害の解決は、インスタンスを再起動することで図れます。Oracleサーバは、インスタンス障害が発生した後のインスタンス起動時に、自動的にインスタンスのリカバリを行います。インスタンスのリカバリでは、REDOログファイルを再度適用するロールフォワード、COMMITされていないトランザクションを取り消すロールバックが行われます。
- メディア障害
データベースファイルが損失したり、ディスクが破損したり、ディスクコントローラが破損したりすることです。メディア障害の解決には、バックアップファイルのリストアと、REDOログ(アーカイブログを含む)を適用するリカバリ操作が必要です。
インスタンスリカバリのチューニング
バックグラウンドプロセスの異常終了やインスタンスの強制停止が起こると、次回のデータベース起動時に自動でインスタンスがリカバリされます。このリカバリの対象となるのは、変更されたが、まだデータファイルに書き出されていないデータブロックです。
デフォルトでは、REDOログファイルがスイッチされたときにチェックポイントが発生しますが、追加でチェックポイントを実行することもできます。チェックポイントを実行することで、リカバリに必要な対象データブロックを減少させることができます。
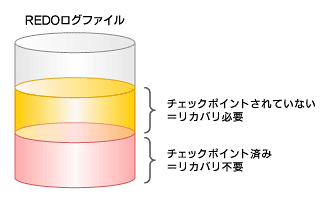 図1 REDOログファイルとリカバリ対象データブロック
図1 REDOログファイルとリカバリ対象データブロック追加のチェックポイントを発行するには、次の2種類の方法があります。
- 手動
ALTER SYSTEM CHECKPOINTコマンドを実行します。
- 自動
FAST_START_MTTR_TARGET初期化パラメータを使用します。FAST_START_MTTR_TARGET初期化パラメータには、MTTR(平均リカバリ時間)を設定します。Oracleサーバは、指定されたリカバリ時間内にインスタンスのリカバリが完了するように、追加のチェックポイントを自動的に発行します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。