Hello Deep Learning:ニューラルネットワークの作成手順:作って試そう! ディープラーニング工作室(1/2 ページ)
あやめの品種を推測するニューラルネットワークを作りながら、データセットの準備、ニューラルネットワークの定義、学習とテストまでの手順を駆け足で見てみましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
前回は人工知能、機械学習、ディープラーニングなどの基本的な考え方、Google Colaboratory(以下、Google Colab)の基本的な使い方を見ました。今回から数回に分けて、あやめの品種を分類するニューラルネットワークを作りながら、その作成の大まかな流れと、コードの詳細について見ていきましょう。
今回は、ニューラルネットワークを作成していく大まかな手順を紹介します。その途中では、少し難解な用語が出てくるかもしれません。しかし、それらを全て今の段階で理解しなくてもかまいません。コードの詳細な説明は次回以降に行うこととして、まずは「こんな感じで作るんだ」というのを感じてくれれば十分です。
ニューラルネットワーク作成の手順
今回は前回に言及した「がく片の長さと幅、花弁の長さと幅からあやめの品種を推測する」ニューラルネットワークを作成してみます。ここで使用するのは、いわゆる「教師あり学習」と呼ばれる方法です。
 あやめの花の構造(前回の再掲)
あやめの花の構造(前回の再掲)その全体像は前回にも述べた通り、以下のようなものでした。

そして、このニューラルネットワークの作成は、次のような手順で進めます。
- データセットの準備と整形
- ニューラルネットワークの定義
- 学習(訓練)と精度の検証
以下ではまずこの手順について簡単にまとめておきましょう。
データセットの準備と整形
「データセット」とは、大量のデータが一定のフォーマットで並べられたものと理解すればよいでしょう。今回の例なら、あやめの特徴(がく片の長さと幅、花弁の長さと幅の4つの数値)と、その品種が並んだものです(この後で取り扱うデータセットでは、以下の図とは少々異なる形式になっていますが、実質的にはこれと同様です)。
 データセット
データセットデータセットに含まれる大量のデータは一般に、幾つかに分割して使われます。1つはまさに学習を行うための入力データとして。また、学習が終わったニューラルネットワークの性能を試すためのデータとして使われるものもあります。今回は触れませんが、学習のやり方を調整するために使うデータへと分割する場合もあります(その場合は、データセットは3つに分割されることになります)。

また、データセットに含まれるデータを、これから使用するPythonのフレームワーク(ライブラリ)であるPyTorchで扱えるように、少し加工する必要もあることにも注意してください。
ニューラルネットワークの定義
その次にニューラルネットワークを表すクラスを定義します。今回は既に名前が挙がっていますが、PyTorchと呼ばれるディープラーニング用フレームワークを使用します(Google Colab環境には既にインストール済みです)。
このときには、プログラミング言語としてPythonを用いて、上で示した構成のニューラルネットワークがどんなものかをコードとして記述していきます。といっても、PyTorchの力を借りることで、前回に述べた「重み」や「バイアス」といった事柄については、プログラマーがあまり気にしなくても済むようになっています(それでも、そうした点まである程度理解できるようになることを本連載では目的としているので、ゆくゆくは実際にそうした部分まで踏み込んでみていくことになるでしょう)。
学習と評価
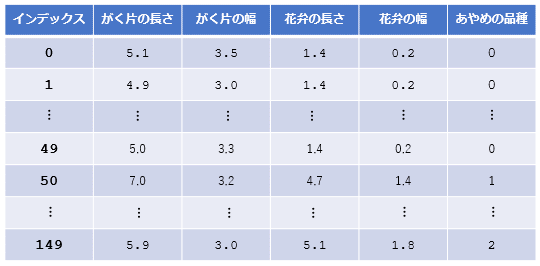
次にくるのが学習です。この段階では、ここまでの2つの手順で用意したデータセットとニューラルネットワークを使って、実際にあやめの特徴を記したデータを入力すると、その品種を推測できるようにしていきます(以下の図では計算結果が浮動小数点数値になっています。そのため、これを整数値に変換する作業が必要になることが予測できます)。
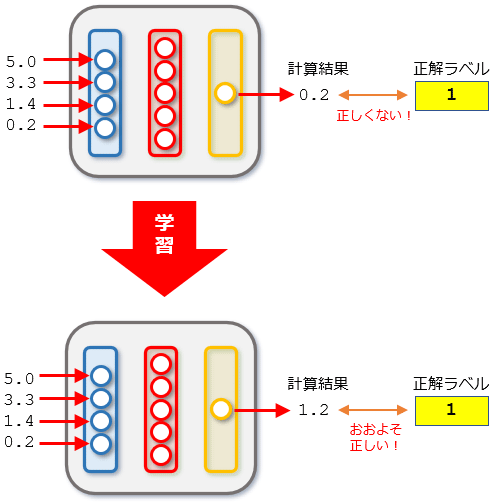 学習によってニューラルネットワークはおおよそ正しい結果を計算できるようになる
学習によってニューラルネットワークはおおよそ正しい結果を計算できるようになるこの後では、学習前にニューラルネットワークが出力した値(推測結果)と、学習後のニューラルネットワークが出力した結果についても見てみることにします。そうすることで、「確かにニューラルネットワークが学習して、おおよそ正しい結果を出せるようになった」と実感できるはずです。
これでおおよその手順についての説明はおしまいです、以下では実際にコードを見ながら、ニューラルネットワークを作成していくことにしましょう。
それでは、前回に紹介した方法でGoogle Colabのページを開いて、ノートブックを新規に作成しましょう(本稿のコードはここで公開しているので、必要に応じて参照してください)。
データセットの準備と整形
今回の例となるあやめの品種を推測するニューラルネットワークを作成するのに必要なデータセットは、前回に名前を挙げたscikit-learnという機械学習フレームワークに含まれています。そして、このフレームワークはGoogle Colabの実行環境に事前にインストールされています。そこで、ここではこれを利用して、データセットを読み込むことにしましょう。
ここでは次の作業を行います。
- あやめのデータセットの読み込み(sklearn.datasets.load_iris関数を使用)
- データセットの分割(sklearn.model_selection.train_test_split関数を使用)
- データの整形(PyTorchのユーティリティー関数を使用)
本稿の冒頭でも述べたように、読み込んだデータセットはニューラルネットワークの学習用とその評価(テスト)用に分割する必要があることも忘れないでください。そして、最後にそれらを今回使用するフレームワークであるPyTorchで使えるように少々の整形(データ型の変換)を行います。では、上の手順に従ってコードを書いていくことにしましょう。
あやめのデータセットの読み込み
データセットを読み込むにはscikit-learnが提供するsklearn.datasetsモジュールからload_iris関数をインポートして、実行するだけです。実際のコードを以下に示します。
from sklearn.datasets import load_iris
iris = load_iris()
このコードを書いて、セルを実行してください。その結果を以下に示します(何も出力はありません)。
 実行結果
実行結果これだけであやめのデータセットの読み込みは完了です。手順に従うと次はデータセットの分割です。が、その前に少しだけ、このデータセットについて説明をしておきます。詳しい説明は次回に行うので、「このデータセットはこんな構造になっているんだ」ということだけを把握しておきましょう。これを知らないことには、以下でいったい何をしているのか分からなくなるかもしれません。
このデータセットには次のような属性(インスタンス変数)があります。
- data属性:個々のあやめのデータを3品種×50個含んだNumPy配列。1つのデータは「がく片の長さ」「がく片の幅」「花弁の長さ」「花弁の幅」の4つの浮動小数点数値で構成され、それが合計で150個並んだ「配列の配列」。
- feature_names属性:上で述べたデータの説明。1つのデータが上で述べた順で並んでいることを説明した文字列を含むリスト
- target属性:data属性の配列の同じインデックス位置にあるNumPy配列(がく片/花弁の長さ/幅を表す4つの数値を要素とする配列)が何の品種であるかを示す「0」「1」「2」の整数値のいずれか)
- target_names属性:target属性の各整数値があやめのどの品種であるかを説明する文字列を含むNumPy配列(「0」は「setosa」という品種に、「1」は「virsicolor」という品種に、「2」は「verginica」という品種に対応しています)
なお、ここでいう「NumPy配列」とは、NumPyが提供するデータ型で、Pythonのリストと似た使い勝手を持ちながら、多次元配列を効率的に扱えるようにしたものです。scikit-learnはNumPyをベースに作られた機械学習フレームワークであり、load_iris関数により読み込まれたデータセットは、NumPyにネイティブなデータ型にまとめられているということです。そのため、後からこれをPyTorchで扱えるように変換します。
その一方で、機械学習やディープラーニングの世界では、配列(一定の形式で複数のデータを並べたもの)のことを「テンソル」と呼ぶことがよくあります。例えば、data属性は「2次元(階数が2)のテンソル」などと呼びます。この後は配列や多次元配列と同じ意味で「テンソル」という言葉も出てくるので覚えておいてください。
先ほどの図に上記の属性を書き加えたものを以下に示します。

学習と評価で実際に使うデータは、data属性とtarget属性に格納されているということです(feature_names属性とtarget_names属性は2つの属性を説明するためのもので、データセットを人が調べるときや、画面に何らかのデータを表示するときに使用します)。iris.data属性に格納されているデータ(とそこから分割されるデータ)はニューラルネットワークに実際に入力されるデータ(入力データ)であり、iris.target属性はニューラルネットワークがiris.data属性に格納されている値を基に計算(推測)した結果がどんな値になるべきかを示すデータ(正解ラベル、教師データ)です。
ここで注意しておきたいのは、上の図から分かる通り、data属性には品種ごとにデータがまとめて格納されている点です(後でデータセットを分割するときには、これらがバラバラになるようにシャッフルします)。
せっかくなので、データを幾つか表示してみましょう。ここではiris.data属性とiris.target属性の値をzip関数でひとまとめにして、enumerate関数でインデックスとその内容が得られるようなコードを書いています(インデックスは先頭の5個のデータだけを表示するために使用しています)。
for idx, item in enumerate(zip(iris.data, iris.target)):
if idx == 5:
break
print('data:', item[0], ', target:', item[1])
実行結果を以下に示します。
 実行結果
実行結果すると、「data:」に続けて角かっこ「[]」に囲まれた4つの数値(入力データ)と、「target:」に続けて4つの数値に対応する整数値(正解ラベル)が表示されました。先ほども述べたように、iris.data属性には品種ごとに50個のデータが順番に並べられているので、「target」の値は全て「setosa」という品種を表す「0」だけになっています。
データセットのおおまかな内容が分かったところで、このデータセットを分割しましょう。
データセットの分割
データセットの分割と聞くと難しく感じるかもしれませんが、今回に限ってはscikit-learnが提供する関数(sklearn.model_selectionモジュールのtrain_test_split関数)を使うだけです。実際のコードを以下に示しましょう。ここでは分割前のデータ数と、分割後のデータ数も表示するようにしてあります。
from sklearn.model_selection import train_test_split
print('length of iris.data:', len(iris.data)) # iris.dataのデータ数
print('length of iris.target:', len(iris.target)) # iris.targetのデータ数
# iris.dataとiris.targetに含まれるデータをシャッフルして分割
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target)
print('length of X_train:', len(X_train))
print('length of y_train:', len(y_train))
print('length of X_test:', len(X_test))
print('length of y_test:', len(y_test))
このコードでは、sklearn.model_selectionモジュールからtrain_test_split関数をインポートした後で、読み込んだデータセット(iris.data属性とiris.target属性)の要素数を表示し、次にインポートしたtrain_test_split関数でそれらを分割して、分割後のデータセットの要素数を表示しています。
気を付けなければいけないのは、学習時にニューラルネットワークに入力されるデータ(iris.data属性)と、その計算結果との比較に使われるデータ(iris.target属性)が別々になっている点です。そのため、上の「train_test_split(iris.data, iris.target)」という呼び出しでは、両者を渡しています(こうすることで、以下で述べるシャッフルが行われた際に、分割後の配列において入力データと正解ラベルの対応関係が維持されます)。
もう一つ、コメント中に「シャッフル」とありますが、これは元の2つのデータセットの要素をランダムに並べ替えることを意味しています。既に述べたように、このデータセットには3種類のあやめの品種ごとに50個のデータ(合計で150個のデータ)が並べられています。このまま頭から順番に分割してしまうと、分割後のデータに偏りが発生してしまうので、ここではデータセットをシャッフルして、分割後のデータセットに3品種のデータがだいたい同じくらいの割合で含まれるようにしているのです。
この関数呼び出しを行うと、変数X_trainとX_testにはiris.data属性の150個のデータを分割したものが、変数y_trainとy_testにはiris.target属性の150個のデータを分割したものが代入されます。
上記コードを実行した結果を以下に示します。
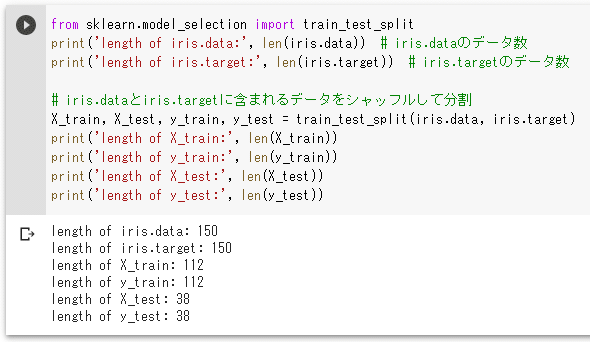 実行結果
実行結果この結果から分かる通り、150個のデータが学習用に112個のデータ(元のデータセットの75%)、テスト用に38個のデータ(元のデータセットの25%)へと分割されました。
分割後のデータを幾つか見てみましょう。
for idx, item in enumerate(zip(X_train, y_train)):
if idx == 5:
break
print('data:', item[0], ', target:', item[1])
これを実行した結果を以下に示します(分割時にデータはシャッフルされるので、読者が実際にこのコードを試すと、これとは異なる出力が得られるでしょう)。
 実行結果
実行結果今度はがく片と花弁の長さや幅もバラバラで、それらに対応するあやめの種類も異なるものが表示されました。
データの整形
データセットの準備の最後に、分割後のデータセットを今回使用するフレームワークであるPyTorchで使えるように少しデータ型の変換を行います。読み込んだデータはscikit-learnが提供するものでした。scikit-learnはNumPyと呼ばれる科学計算用を高速かつ簡便に行うためのパッケージをベースに作られていて、先ほども述べたように、あやめの特徴を記したデータは「NumPy配列」と呼ばれるデータ構造に格納されています。そこで、これらをPyTorchで扱えるように変換する必要があるのです。
実際のコードを以下に示します。
import torch
X_train = torch.from_numpy(X_train).float()
y_train = torch.tensor([[float(x)] for x in y_train])
X_test = torch.from_numpy(X_test).float()
y_test = torch.tensor([[float(x)] for x in y_test])
このコードではまず、import文でtorchパッケージをインポートしています。このパッケージは、PyTorchが提供する多次元配列「テンソル」や、それを扱うための演算子、各種のユーティリティー関数などを定義したものです。これをインポートすることで、NumPy配列からPyTorchのテンソルを作成するfrom_numpy関数や、リストや数値などのPythonオブジェクトからPyTorchのテンソルを作成するのに使えるtensor関数などを利用できるようになります。
実際、その下のコードではこれらを使って、torch.from_numpy関数を使ってNumPy配列からPyTorchのテンソルを作成したり、torch.tensor関数を使ってPyTorchのテンソルを作成したりしています。これらのコードの詳しい説明も次回以降に行うことにしましょう。ここでは、「NumPy配列をPyTorchで使えるように変換している」ことだけを覚えておけば十分です。
なお、実際にどのようなフォーマットのデータに整形するかは、自分が作成するニューラルネットワークの仕様や、学習やその精度評価で使用する損失関数、最適化アルゴリズム などとの兼ね合いになるので、常に上のような変換を行うとは限りません。
このコードは特に画面に何かを表示したりはしませんが、忘れずに実行しておいてください。データセットの準備はこれで完了です。次にニューラルネットワークの定義に移りましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。