[文章生成]MeCabをインストールして分かち書きを試してみよう:作って試そう! ディープラーニング工作室(1/2 ページ)
形態素解析エンジン「MeCab」をGoogle Colab上にインストールして、簡単なテキストを解析したり、分かち書きをしたりできるようにしてみる。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
今回の目的
前回は、青空文庫のWebサイトから梶井基次郎の小説データを取得して、そこから本文のデータを抽出する方法を見ました。今回は、自然言語処理で扱いやすいように分かち書きをするための準備をします。
ところで、自然言語処理とはもちろん私たちが日常的に使っている言葉(ここでは日本語としましょう)をコンピューターに処理させることです。その結果、コンピューターに入力された言葉からは、何らかの情報が取り出されます。何らかの情報とは例えば地名や製品名、ランチの注文かもしれませんし、ユーザーがしたい何かのアクションかもしれません。あるいは、入力された言葉が、全体として肯定的なものなのか、否定的なものなのかを判断するといったことも考えられます。
いずれにせよ、こうした処理を行うには、入力された言葉をさまざまな段階を踏んで解析する必要があるでしょう。
例えば、「くるまでまつ」という文について考えてみます。これは「車で待つ」と「(誰かが)来るまで待つ」という意味のどちらでしょうか。あるいは「東京都に住む」といえば、普通に考えれば新宿や渋谷がある街である東京-都(とうきょうと)に住むとなるでしょう。しかし、京都市東山区などの東-京都(ひがしきょうと)に済むとも解釈できるかもしれません。
「くるまでまつ」なら「車で待つ」などとその意味をコンピューターが(そして人が)意味を把握しやすい形で記述してもらえるのが一番です。自分が誰かに何かを伝えようとして、文をしたためるときにはそのように気を使うことは可能です。しかし、どこかで書かれた文をコンピューターで処理するときにそんなことは期待できないでしょう。よって、何らかの形で文の構造や意味、文脈などを解析して、もっともらしい意味をそこから割り出す必要があるといえます。
日本語の処理において、今述べたような解析を行うための第一歩となるのが、形態素解析と呼ばれるものです。形態素とは、一つの文を構成する最小単位(これ以上は分割できないレベル)の語句と考えられます。日本語には名詞、動詞、形容詞、副詞、助詞などさまざまな単語があり、それらを組み合わせることで文は成り立っています。コンピューターに入力された文を、今述べたように、単語へと分解して、それぞれが名詞なのか動詞なのかなど、その品詞を特定したり、語尾変化を特定したりするのが形態素解析で行われることです。
例えば、「くるまでまつ」なら「くるま」(名詞)、「で」(助詞)、「まつ」(動詞)か、「くる」(動詞)、「まで」(助詞)、「まつ」(動詞)などのように分解できます。
このような解析が必要となるのは、日本語が英語など、文中で単語の区切りに空白を含める言語とは異なり、文中に形態素(あるいは単語)を区切るものが存在していないからです。英語のような言語であれば、空白を境として単語が最初から分割されているので、単語の識別は容易です。しかし、日本語ではどうしてもこのような処理が必要になります。
また、形態素解析によって、分割された単語と単語の間に空白を含めて書き下すことを「分かち書き」と呼びます。
 「くるまでまつ」を分かち書きしてみた例
「くるまでまつ」を分かち書きしてみた例今回はこの分かち書きができるようにGoogle Colabで環境を整えてみることにしましょう。
MeCabのインストール
今述べたような形態素解析、分かち書きを行う関数やクラスを自分で一から書かなければならないということはさすがにありません。これらの処理を行ってくれるライブラリには幾つかありますが、ここではMeCabとそれをPythonから使用するためのmecab-python3を使うことにしましょう。
といっても、Google Colab上にはこれらはインストールされていないので、自分でインストールする必要があります。また、形態素解析を行うには、文中に含まれる単語を引くための辞書も必要になるので、これらも必要です。なお、mecab-python3にはスタティックリンクされたMeCabライブラリが内蔵されているとのことなので(辞書は同梱されていません)、まずはこれと辞書だけをインストールしてみます。
辞書については、mecab-python3のGitHubリポジトリでは、IPAdicと呼ばれる辞書は既に保守されていないので、これを使うのではなくUniDicを使用することが推奨されていることから、ここではUniDicをインストールすることにしました(UniDicは国立国語研究所が開発している辞書です。ここで使用しているのは、PyPIから取得可能な「unidic-py」で、これがサポートしているバージョンは2021年2月4日時点で2.3.0となっています)。
!pip install mecab-python3
!pip install unidic
上記のコードを実行すると、以下のように2つのモジュールがインストールされます(各行の先頭にある「!」はPythonの対話環境ではなく、シェルからコマンドを実行することを意味します)。なお、今回のコードはこのノートブックで公開していますので、必要に応じて参照してください。

しかし、これでインストールが終わったわけではありません。UniDicに同梱のdownload.pyファイルを実行して、辞書データをダウンロードする必要もあります。これには以下を実行します。
!python -m unidic download
これを実行すると次のように表示されます。

これで取りあえずの準備ができました。次に実際にMeCabを使用して形態素解析を行ってみましょう。
import MeCab
import unidic
tagger = MeCab.Tagger() # 「tagger = MeCab.Tagger('-d ' + unidic.DICDIR)」
sample_txt = 'くるまでまつ'
result = tagger.parse(sample_txt)
print(result)
このコードではMeCab.Taggerクラスのインスタンスを生成し、そのparseメソッドに「くるまでまつ」という文字列を渡すことで解析を実行しています。その実行結果は次のようになりました。MeCab.Taggerクラスのインスタンス生成を行っている行にはコメントがありますが、これはインスタンス生成時にunidic.DICDIR属性を「-d」オプションの値として渡す例です(「-d」オプションは辞書のパスを指定するもので、コメントに示した例では何も指定しないときと同様の振る舞いになります)。このようにしてさまざまなオプションを与えることで、形態素解析実行時に参照する辞書を変更するといったことが可能です。
以下はその実行結果です。

UniDicを使った解析では「くる」「まで」「まつ」となったということですね。その隣には各単語の品詞や関連する情報が表示されているのも分かります。先ほど形態素解析では文を「単語へと分解して、それぞれが名詞なのか動詞なのかなど、その品詞を特定したり、語尾変化を特定したりする」といいましたが、まさにそのような解析が行われていることが分かります。
そして、英語の文のように単語間に空白を含んだ「分かち書き」を行うには、MeCab.Taggerクラスのインスタンス生成時に以下のように「-Owakati」オプションを指定します。
wakati = MeCab.Tagger('-Owakati')
result = wakati.parse(sample_txt)
print(sample_txt)
print(result)
実行結果を以下に示します。
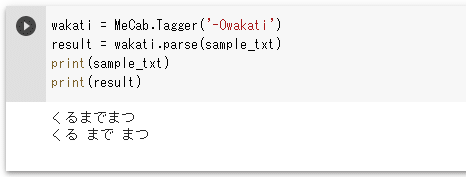 実行結果
実行結果「くる」「まで」「まつ」の間に空白が入り、分かち書きができていることが確認できました。次に最近の単語を含んだ文について見てみましょう。
sample_txt = '鬼滅の刃もいいけれど、約束のネバーランドもね'
result = tagger.parse(sample_txt)
print(result)
これを実行すると、その結果は次のようになります。

UniDicにはまだ「鬼滅の刃」も「約束のネバーランド」も含まれていないようで、単語として認識してほしいのに、そうはなっていません。分かち書きをしてみれば、やはり、「鬼」「滅」の間などに空白が入り、これらが一つの単語であると認識できていないことが分かります。
 分かち書きの結果
分かち書きの結果最近の単語が梶井基次郎の小説に含まれているはずはありませんが、扱うデータによってはそうしたものもうまく解析できる方がよいかもしれません。というわけで、最近になってきた単語も採録されている辞書をインストールしてみましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。