Titanicから始めよう:ハイパーパラメーターチューニングのまねごとをしてみた:僕たちのKaggle挑戦記
Ray Tuneというハイパーパラメーターチューニングパッケージを使って、隠れ層や学習率などをチューンしてみました。その結果は果たして?(やっちゃダメなこともやっちゃったよ)。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
前回は、特徴量エンジニアリングのまねごとをしてみようということで、Titanicコンペティションの元データを加工して、新たな特徴量を作成して、それらを使ってPyTorchで定義した線形回帰モデル/3層の全結合型DNNモデル/4層の全結合型DNNモデルの学習を行い、テストデータの生死予測をしてみたのでした。
その結果はあまり芳しいものではありませんでした。スコアは0.77033。前々回にEDAのまねごとをしたときには、何かのモデルにデータを入力するのではなく、EDAで発見した「女性は全員生存→男性で旅客運賃が高い人は生存(そんな人はいなかった)→男性でチケットクラスが1、かつ若年層か高齢層の人は生存(1人だけ)→女性でチケットクラスが3、かつ乗船した港が'S'は死亡」という傾向に従って提出用のCSVファイルを操作しただけですが、そのスコア0.7790よりも低いものとなっていました。
モデルによる推測の精度を上げるために、「EDAもやった。特徴量エンジニアリングもやった」となると次にくるのはハイパーパラメーターチューニングです。というわけで今回はハイパーパラメーターチューニングのまねごとをしてみることにしました。
でも、その前に
とはいえ、実はこの原稿を書き始めるまでに筆者はかなりの試行錯誤をしていました。というのは、前回のデータのままでハイパーパラメーターをチューンしてもなかなかスコアが上がらなかったのです。これには幾つかの原因が考えられます。
- モデルに問題がある
- EDAや特徴量エンジニアリングが不十分
前者については、この連載では線形回帰モデル/3層の全結合型DNN/4層の全結合型DNNの3種類をPyTorchのLinearクラスを使って定義したものを使っています。ハイパーパラメーターチューニングの結果がダメなら、scikit-learnなど、別のフレームワークを使うことを考慮した方がよさそうです。
後者については、前回に元データを加工した結果のデータフレームはだいたい次のようなものでした(ヒートマップ)。
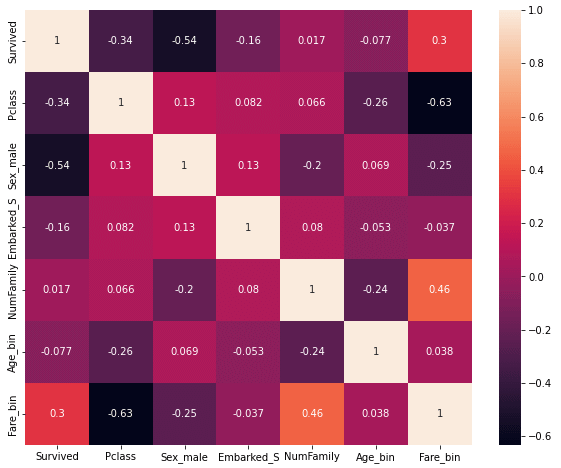 前回の特徴量エンジニアリングによって作成したデータ
前回の特徴量エンジニアリングによって作成したデータこれが悪かったのでは? ということで、今回はさらに(元のCSVファイルにある)Nameカラムから「Mr」「Ms」などの敬称(title)を抜き出して、それらをone-hot表現に変換するなどの処理を加えることにしました。その結果、得られたのは次のようなデータフレームです。実際にどんなことをしているかはこちらのノートブックを参照してください。

このデータをCSVに保存してから、今回ハイパーパラメーターチューニングを行うためのノートブックに新たなデータセットとしてアップロードして使用するようにしています。
上のヒートマップを見ると分かりますが、Title_MrカラムはSurvivedカラムと強い負の相関を持ち、Title_MrsカラムとTitle_MsカラムはSurvivedカラムと強い正の相関を持っています。また敬称と性別には関連があることからSex_maleカラムは不要だと判断し、以下の処理ではこれをドロップすることにしました(Title_anotherカラムも相関がそれほど強くなさそうだったのでこれもドロップすることにしました)。
という話をしたところで、ハイパーパラメーターチューニングを行うコードについて見ていくことにしましょう

追加の処理はDataiTeam Titanic EDAなどのノートブックを参考にしています(ありがとうございます)。[かわさき]
ハイパーパラメーターチューニング
ハイパーパラメーターチューニングを行うノートブックはこちらで公開しているので、興味のある方は参考にしてください。
このノートブックの先頭では前回と同様、線形回帰モデル/3層の全結合型DNNモデル/4層の全結合型DNNモデルを作成し、それに上掲のデータフレームを(PyTorchのデータローダー経由で)入力して学習を行い、最後にテストデータから生死を推測しています。その結果は「0.76794」となりました。
あれ? なんか前回のスコア「0.7703」を下回っているようです……。ま、まあ、目標は、これを(できれば大きく)上回ることです。
ハイパーパラメーターチューニングを行うフレームワークは多々ありますが、ここでは「pytorch hyperparameter tuning」として検索を行ったときに先頭に表示された「Ray Tune」を使うことにしました。

へぇ。自分は知らなかったですが、PyTorch公式でも取り扱っているなら押さえておきたいですね。[一色]
Ray自体は分散アプリケーション構築用のAPIを提供するものですが、その一部としてハイパーパラメーターをチューンするRay Tuneが含まれているようです。Kaggleのノートブック環境には標準でインストールされているので、使用するには以下のimport文を実行します。
import ray
from ray import tune
Ray Tuneでは学習と検証を行う関数と、それを起動する関数の2段構えでハイパーパラメーターのチューンを行います(後者がmain関数となり、その中でチューン後のモデルとテストデータを使って推測を行う場合もあるでしょう。そうしたコードはチュートリアルを参照してください。ここでは3つのモデルのハイパーパラメーターをチューンするので、それぞれの学習と検証を行う関数と、それらを起動する関数を別個に定義しています)。
このうち学習と検証を行う関数では、例えば、3層の全結合型DNNモデルのノード数や、学習率(learning rate)、エポック数などを変化させながら学習を行い、学習済みのモデルのステートを保存したり、検証した結果をRay Tuneフレームワークに報告したりするようになっています。
それを起動する側の関数では、今述べたノード数などのハイパーパラメーターにはどんな値を設定するかを構成して、例えば、3層の全結合型DNNの隠れ層のノード数には4/8/16/32の4つの値を候補とするとか、バッチサイズも同じく4/8/16/32を候補とするとかといった構成を記述した上で、実際に学習と検証を行う関数を実行します。
そして、さまざまなハイパーパラメーターの組み合わせ(全ての組み合わせを試すのではなく、その中から幾つかの組み合わせをランダムでピックアップします)で試行をし、試行が全て終わったら、その中から最良のモデル(とそのためのハイパーパラメーターの組み合わせ)が決定するので、今度はそのモデルを使ってテストデータから生死の推測を行うといった具合になるでしょう。
既に実行してしまった後ですが、ニューラルネットワークのエポック数をハイパーパラメーターチューニングするのは典型的な誤りで、すごくムダらしいですよ……。エポック数を増やしたり減らしたりして調整するよりも、早期停止(Early Stopping)する方が適切です。同様のことを自分の回でも書きましたが。理由としては、「なぜn_estimatorsやepochsをパラメータサーチしてはいけないのか - 天色グラフィティ」などが参考になるかと思います。次から気を付けよう。
ぎゃぁぁぁ……。これから気を付けます。ついでに早期停止だと、どんなコードになるかも可能なら次回にちょっとお知らせできるようにします。
学習と検証を行うコード
まずは、学習と検証を行うhypartune_DNN1関数を示します。これは3層の全結合型DNNモデルを対象としたものです。
hypartune_DNN1関数と同様にDNN2モデルとLinearRegressionモデルのチューンを行う関数も定義していますが、これらについてはクラスのインスタンス生成を除けばほぼ同様なのでここでは説明は省略します。もちろん、本当はリファクタリングをしたいのですが、今回はあきらめました(関数名に含まれる「hypar」は「hyper」の「hy」と「parameters」の「par」を合わせたものです。分かりにくい名前ですみません)。
def hypartune_DNN1(config, checkpoint_dir=None):
torch.manual_seed(2)
random.seed(2)
global INPUT_SIZE, OUTPUT_SIZE
if checkpoint_dir:
checkpoint = os.path.join(checkpoint_dir, "checkpoint")
model_state, optimizer_state = torch.load(checkpoint)
net.load_state_dict(model_state)
optimizer.load_state_dict(optimizer_state)
datasets = get_datasets()
train_sets, val_sets = datasets[1] # [0] for Regression, [2] for DNN2
trainloader = DataLoader(train_sets, batch_size=config['batch_size'])
valloader = DataLoader(val_sets, batch_size=config['batch_size'])
net = DNN1(INPUT_SIZE, config['l1'], OUTPUT_SIZE)
criterion = nn.BCELoss()
optimizer = optim.Adam(net.parameters(), lr=config['lr'])
for epoch in range(config['epochs']):
running_loss = 0.0
for cnt, (X, y) in enumerate(trainloader, 1):
optimizer.zero_grad()
pred = net(X.float())
loss = criterion(pred.reshape(-1), y.float())
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'[{epoch:4d}] loss: {running_loss / cnt:.4f}')
val_loss = 0.0
predicts = []
labels = []
with torch.no_grad():
for cnt, (val_X, val_y) in enumerate(valloader, 0):
pred = net(val_X.float())
loss = criterion(pred.reshape(-1), val_y.float())
val_loss += loss.item()
pred[pred >= 0.5] = 1
pred[pred < 0.5] = 0
predicts.extend(pred)
labels.extend(val_y)
result = [p == t for p, t in zip(predicts, labels)]
accuracy = sum(result) / len(predicts)
val_loss_avg = val_loss / cnt
with tune.checkpoint_dir(step=epoch) as checkpoint_dir: # using default dir
path = os.path.join(checkpoint_dir, 'checkpoint')
torch.save(
(net.state_dict(), optimizer.state_dict()), path)
tune.report(loss=val_loss_avg, accuracy=accuracy)
print('Finished Training')
長い関数ですが、最初はデータローダーの設定、次に学習を行うコード、そして検証を行うコード、最後にモデルの状態を保存したり、ログに記録する目的でRay Tuneに検証結果を報告したりするコードが含まれています。
この関数のパラメーターはconfigとcheckpoint_dirの2つです。configには、ノード数や学習率など、チューンしたいハイパーパラメーターとその候補となる値が辞書形式で渡されます。例えば、隠れ層のノード数は、configから「config['l1']」のようにしてピックアップしていきます(上のコードでは、エポック数、学習率、バッチサイズに関して、このようにしてconfigから値を取得するようになっています)。この関数が呼び出されるたびに、この値が変化することで異なる構成で学習と検証が行われ、最適なハイパーパラメーターが決定されるようになります(そうした面倒なことを取り計らってくれるのがRay Tuneです)。
net = DNN1(INPUT_SIZE, config['l1'], OUTPUT_SIZE)
checkpoint_dirは、チェックポイントの復元をする必要があるときに、Ray Tuneから値が渡されるようです。関数内では、ここにRay Tuneから値が渡されたときには、モデルとオプティマイザーの状態を復元するようになっています(そのためのコードはチュートリアルにあるコードをそのまま使用しています)。
データローダーの作成では、get_datasetsという名前のヘルパーを用意しました。これを使ってこの関数内でPyTorchのデータセットクラスを作成して、それを3分割してK-fold交差検証を行えるように準備しています。
その後はDNN1クラスのインスタンス生成、学習を行うループ、検証を行うループを実行していますが、上で述べたconfigからのハイパーパラメーターの取得を除けば、この辺のコードは既におなじみのものでしょう。
最後の「with tune.checkpoint_dir(step=epoch) as checkpoint_dir:」で始まるブロックはエポックごとに学習後のモデルの状態とオプティマイザーの状態を保存するものです。最良の結果はここに保存された各種の情報を参照して決定されます。その後のtune.report関数呼び出しではRay Tuneがログに記録するメトリックを指定します。上のコードでは検証時に得られた損失と、検証時に得た推測結果の精度をログに記録するようにしています。
チューンで使用する学習用関数を呼び出すコード
今述べた関数を呼び出すコードは次のようになっています。
def tune_DNN1(num_samples=10):
config = {
'l1': tune.sample_from(lambda _: 2 ** np.random.randint(2, 6)),
#'l1': tune.choice([4, 8, 16, 32])
'lr': tune.loguniform(1e-4, 1e-1),
'batch_size': tune.choice([4, 8, 16, 32]),
'epochs': tune.choice([100, 300, 500])
}
result = tune.run(
tune.with_parameters(hypartune_DNN1),
config=config,
metric='loss',
mode='min',
num_samples=num_samples,
verbose=1
)
best_trial = result.get_best_trial('loss', 'min', 'last')
print(f'Best trial config: {best_trial.config}')
print(f'Best trial final val loss: {best_trial.last_result["loss"]}')
print(f'Best trial final val accuracy: {best_trial.last_result["accuracy"]}')
global INPUT_SIZE, OUTPUT_SIZE
hidden = best_trial.config['l1']
model = DNN1(INPUT_SIZE, hidden, OUTPUT_SIZE)
checkpoint_path = os.path.join(best_trial.checkpoint.value, 'checkpoint')
model_state, optimizer_state = torch.load(checkpoint_path)
model.load_state_dict(model_state)
torch.save(model.state_dict(), '/kaggle/working/best_dnn1.pth')
return model, best_trial
関数の冒頭では、hypartune_DNN1関数のconfigパラメーターに渡す値の構成を行っています。簡単にその内容を説明しましょう。
config = {
'l1': tune.sample_from(lambda _: 2 ** np.random.randint(2, 6)),
'lr': tune.loguniform(1e-4, 1e-1),
'batch_size': tune.choice([4, 8, 16, 32]),
'epochs': tune.choice([100, 300, 500])
}
'l1'は隠し層のノード数です。tune.sample_from関数は引数に受け取った関数の戻り値からその値を決定します。この場合は4/8/16/32のいずれかの値です。'lr'は学習率の指定です。ここで使っているtune.longuniform関数は第1引数と第2引数で指定した範囲から値を取得します。この場合、得られる値は0.0001〜0.1の範囲の浮動小数点数値です。
'batch_size'はデータローダーから一度に読み込むデータの数を指定します。tune.choice関数は引数に与えたリストの要素の中から1つを同一確率で選択するものです。よって、4/8/16/32のうちのいずれかの値となります。'epochs'はエポック数を指定します。ここでは100/300/500のいずれかです。
l1やl2というと、L1/L2正則化っぽいなと思ったけど、公式チュートリアルもそういう命名なんだね……。
そうなんです。この辺の命名(?)はチュートリアルのままです。
これらの全ての組み合わせがチェックされるのではなく、hypartune_DNN1関数を呼び出すたびに、上に述べた範囲の値がランダムに取り出されてconfig引数に渡されます。その組み合わせの数を指定するのが、tune_DNN1関数のnum_samplesパラメーターです。デフォルト値は10なので、特に指定をしなければ10種類の組み合わせがランダムに作られるので、それらの値を使って、hypartune_DNN1関数が呼び出されるというわけです。そして、最良の結果となるようなハイパーパラメーターの組み合わせを探すのが、次に呼び出しているtune.run関数です。
result = tune.run(
tune.with_parameters(hypartune_DNN1),
config=config,
metric='loss',
mode='min',
num_samples=num_samples,
verbose=1
)
上のコードで指定している引数についても簡単に説明しておきましょう。第1引数には学習を行う関数(呼び出し可能オブジェクト)を指定します。ここでは、tune.with_parameters関数に、実際に学習を行うhypartune_DNN1関数を引数として渡しています。これは実際に学習を行う関数と、それに渡す引数をラップするためのものです。
hypartune_DNN1関数に与える引数は、with_parameters関数にキーワード引数として与えることもできますが、ここでは特に指定をしていません(内部で使用するデータセットをここで渡すようにすれば、先ほどのhypartune_DNN1関数内部での処理が少し簡単になったかもしれません)。
configキーワード引数には、すぐ上で定義した変数configを渡しています。もちろん、これが最終的にhypartune_DNN1関数へと渡されます。metricキーワード引数にはチューンで使用するメトリックを指定します。ここでは'loss'を渡しているので損失を基にチューンが行われるということです。ここで指定した値は、hypartune_DNN1関数の内部で呼び出しているtune.report関数に渡す必要があります。そのため、hypartune_DNN1関数では最後に以下のようにしていたわけです。
tune.report(loss=val_loss_avg, accuracy=accuracy)
modeキーワード引数には'min'か'max'を指定します。これはmetricキーワード引数に指定したメトリックを最小化させる方向に最適化を行うか、最大化させる方向に最適化を行うかを指定するものです。
num_samplesキーワード引数は、既に述べた通り、configキーワード引数に渡したハイパーパラメーターの組み合わせを何個作成するかを指定します。最後のverboseキーワード引数はチューンを行っている際の情報表示を制御します。指定可能な値は0/1/2/3のいずれかです。値が大きくなるほど、詳細な表示となります。ここでは1を指定していますが、これはチューンの状況を更新するだけです。
tune.run関数を呼び出すと、かなりの時間をかけて、ハイパーパラメーターのチューンが行われます。その戻り値にはget_best_trialメソッドがあるので、このメソッドに最良の結果を選択する指標となる'loss'(損失)、'min'(損失を最小化する方向)、'last'(各試行の最終結果を参照)を指定して、最良の結果となった試行(trial)に関する情報を取得しています。
best_trial = result.get_best_trial('loss', 'min', 'last')
print(f'Best trial config: {best_trial.config}')
print(f'Best trial final val loss: {best_trial.last_result["loss"]}')
print(f'Best trial final val accuracy: {best_trial.last_result["accuracy"]}')
その後は、隠れ層のノード数を取得して、それを使ってDNN1クラスのインスタンスを生成して、そこに最良の結果を得たモデルの重みやバイアスの状態を読み込んで、最後にそれを保存し、関数の戻り値としてそのモデルと最良の試行に関する情報を返送するようにしました。
global INPUT_SIZE, OUTPUT_SIZE
hidden = best_trial.config['l1']
model = DNN1(INPUT_SIZE, hidden, OUTPUT_SIZE)
checkpoint_path = os.path.join(best_trial.checkpoint.value, 'checkpoint')
model_state, optimizer_state = torch.load(checkpoint_path)
model.load_state_dict(model_state)
torch.save(model.state_dict(), '/kaggle/working/best_dnn1.pth')
return model, best_trial
この関数は以下のコードで呼び出しています。
best_dnn1_model, best_dnn1 = tune_DNN1(16)
ここではnum_samples引数に16を渡しているので、16種類のハイパーパラメーターの組み合わせを使って、学習と検証を行い、最良のモデルとそれに関する情報をbest_dnn1_modelとbest_dnn1の2つの変数に受け取っています。

この実行結果を見ると、隠れ層のノード数は4、学習率は0.001917069641865855、バッチサイズは4、エポック数は500のときに一番よい結果が得られたということが分かりました。
チューン後のモデルの検証とテストデータから生死を推定
この後は、DNN2モデルとLinearRegressionモデルについても同様な処理を行って、その結果を得るようにしました。実際のコードについては、ノートブックを参考にしてください。
ハイパーパラメーターのチューンはこれで終わったので、3つの最良のモデルにテストデータを入力して、生死を推測すればよいのですが、その前に検証データを使って、精度が上がったかを確認してみましょう。
best_models = [best_lr_model, best_dnn1_model, best_dnn2_model]
val_results = {}
for cnt, (model, (_, v_loader)) in enumerate(zip(best_models, loaders)):
val_results[cnt] = validate(model, v_loader)
for idx, d in val_results.items():
print(f'k: {idx}, accuracy: {d["accuracy"]:%}')
実行結果を以下に示します。Markdownにはノートブックの先頭でチューン前に行った検証結果も書いておきました。

大きくかどうかはよく分かりませんが、少なくともチューンによって、検証データに関しては精度が上がったようです。とはいえ、これがテストデータに対してもうまく働くかどうかは分かりません。
というわけで、最後にテストデータを3つのモデルに入力して、推測を行います(以下のコードでは、文字数の制限からファイル名を一度、変数に代入するようなコードになっていますが、実際のノートブックでは直接ファイル名をto_csvメソッドに指定しています。長くダラダラと書けるのがいいのか悪いのかの判断は難しいですね)。
with torch.no_grad():
results = [predict(model, X_test) for model in best_models]
for item in results:
item[item >= 0.5] = 1
item[item < 0.5] = 0
result = results[0] + results[1] + results[2]
result[result < 2] = 0
result[result > 1] = 1
result = result.squeeze().int().tolist()
print(f'{sum(result)} / {len(result)} = {sum(result) / len(result)}')
pid = pd.read_csv('../input/titanic/test.csv')['PassengerId']
submission_with_hypartuning = pd.DataFrame({'PassengerId': pid,
'Survived': result})
#submission_with_hypartuning.to_csv('submission_with_hypartuning.csv',
index=False)
fname = f'submission_with_hypartuning_{INPUT_SIZE}inputs.csv'
submission_with_hypartuning.to_csv(fname, index=False)
その結果は0.78229となりました。まとめると次のようになります。
- 前回の最終的なスコア:0.77033
- チューン前のスコア:0.76794
- チューン後のスコア:0.78229
0.78229−0.76794=0.01435程度の差が果たして劇的なものかどうかは分かりませんが、試行錯誤の末にようやくこれまでで最高のスコアが得られました。よかった。
おめでとう! Titanicコンペは精度が僅差みたいなので、0.01以上、良くなるだけでも十分良い結果だと思います。こういう場合はランクがどう変化するかも見た方がいいのかもね。
よかったで終わってもよいのですが、ざっくりとチューンで得られたハイパーパラメーターの値を以下に示しておきます(学習率は小数点以下5桁目で四捨五入。なお、エポック数は本当はチューニングの対象にすべきではない、というお話は先ほど出ましたね)。
| モデル | 隠れ層 | 学習率 | バッチサイズ | エポック数 |
|---|---|---|---|---|
| 線形回帰モデル | − | 0.0010 | 4 | 100 |
| 3層の全結合型DNN | 4 | 0.0019 | 4 | 500 |
| 4層の全結合型DNN | 8/32 | 0.0010 | 4 | 300 |
| チューン後のハイパーパラメーター | ||||
線形回帰モデルではエポック数が100と他のモデルよりもかなり少なくなっています。これまでは全てのモデルで500エポックの学習をしていたので、これにより過学習を生じていたのかもしれません。3層の全結合型DNNでは隠れ層のノード数が少なく/学習率が大きく/エポック数は500で、4層の全結合型DNNでは隠れ層のノード数が多く/学習率が小さく/エポック数は300です。
3層の全結合型DNNでは、少ないノード数/少し大きめの学習率で何回も学習を行うことで最適な結果にたどり着いたのに対して(学習率が大きい分、最適値の発見までに行きつ戻りつを繰り返し、それがエポック数の増加につながったのかもしれませんね)、4層の全結合型DNNでは多くのノード数/小さめの学習率で3層の全結合型DNNよりも少ないエポック数で最適な結果にたどり着いています。3層の全結合型DNNでも多いノード数/小さめの学習率/少ないエポック数にしたらどうなるか(あるいは4層の全結合型DNNで逆にする)は気になるところですね(今回はそこまではやりませんが)。
試行錯誤している間、一色さんとのミーティングでは「特徴量エンジニアリングまでがうまくいってないダメなデータを使っているとハイパーパラメーターチューンって意味ないんじゃないか」などと愚痴っていたのですが、少しはマシなスコアが出たことには安心しました。
原稿を書く前(原稿を書きながらコードも実行していたのです)は「今回スコアが上がらなければ、scikit-learnを試してみてもいいんじゃないかな」と思っていたので次回はこの勢いでscikit-learnにいっちゃおうかなぁ(笑)。
楽しみにしています。ニューラルネットワークと比較してどういう違いが出るのかが気になります。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。