[pandas超入門]Seriesオブジェクトの作成とその基本:Pythonデータ処理入門(1/2 ページ)
pandasが提供するデータを格納/操作するための2種類のオブジェクト、SeriesとDataFrame。そのうちのSeriesオブジェクトを作成しながら、その基本的な特徴を紹介。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
本シリーズと本連載について
本シリーズ「Pythonデータ処理入門」は、Pythonの基礎をマスターした人を対象に以下のような、Pythonを使ってデータを処理しようというときに便利に使えるツールやライブラリ、フレームワークの使い方の基礎を説明するものです。
- NumPy(「NumPy超入門」の目次はこちら)
- pandas(本連載)
- Matplotlib
Pythonだけを覚えれば何でもできるわけではない、というのはハードルが高く感じられるかもしれません。それでもプログラミング言語に関する基礎が身に付いたら、後は各ツールを使いながら、言語とツールに対する理解を少しずつ、しっかりと深めていくことで自分がやれることも増えていきます。そのお手伝いをできたらいいな、というのが本シリーズの目的とするところです。
なお、本連載では以下のバージョンを使用しています。
- Python 3.12
- pandas 2.2.1
Seriesオブジェクトとは
pandas.Seriesクラス(以下、Seriesクラス)はインデックス付きの1次元配列を表すクラスです。
以下ではSeriesオブジェクトを作成しながら、その特徴について見ていきましょう。
pandas.Seriesコンストラクタ
pandas.Series(data=None, index=None, dtype=None, name=None, copy=None)
1次元配列であるSeriesクラスのインスタンスを生成する。パラメーターの意味は次の通り。
- data:Seriesオブジェクトに格納するデータを指定。リスト、1次元配列、辞書、スカラー値などを指定可能。省略時のデフォルト値はNoneで、このときには空のSeriesオブジェクトが生成される
- index:Seriesオブジェクトの要素へのアクセスに使用するインデックスの指定。リストやNumPyのndarrayからSeriesオブジェクトを生成する場合には、インデックスの数と元データの要素数は同じでなければならない。省略時のデフォルト値はNoneで、このときには整数ベースのインデックスとなる
- dtype:Seriesオブジェクトの要素のデータ型。省略時のデフォルト値はNoneで、このときにはdataパラメーターに指定したものからデータ型が推測される
- name:Seriesオブジェクトの名前。省略時のデフォルト値はNone
- copy:dataパラメーターに指定したデータのコピーをSeriesオブジェクトに格納するかどうかの指定。Trueはコピーする。Falseはコピーしない。省略時のデフォルト値はFalse
シンプルな作成例
最も簡単な例としては、リストやNumPyの1次元配列(ndarray)を渡すだけというのが考えられます。以下はNumPyの1次元配列 を渡す例です(環境によってはdtypeの値が出力結果と異なる場合があります)。
import pandas as pd
import numpy as np
a = np.array([0.81, 0.66, 0.78, 0.09, 0.31])
print(a) # [0.81 0.66 0.78 0.09 0.31]
s = pd.Series(a)
print(s)
# 出力結果:
#0 0.81
#1 0.66
#2 0.78
#3 0.09
#4 0.31
#dtype: float64
Visual Studio Code(にPython拡張機能とJupyter拡張機能をインストールした状態。以下、VS Code)で上記コードを実行した結果を以下に示します。

変数sに代入したSeriesオブジェクトをprint関数で出力した結果を見てください。左側の列は冒頭で述べた「軸ラベル(インデックス)」です。そして右側に、そのインデックスに対応する値が表示されています。「軸ラベル」は行や列を識別するために使われるラベルのことで、行の場合は特に「インデックス」と呼ばれます。上の例で取り上げているのはSeriesオブジェクトであり、軸ラベル(インデックス)としては整数が使われていますが、以下で示すように文字列を指定することも可能です。
また、最下行に「dtype: float64」とあることに気が付いた方もいらっしゃるでしょう。これはこのSeriesオブジェクトが格納しているデータの型がfloat64(64bitの浮動小数点数値)であることを意味しています。先ほどのpandas.Seriesコンストラクタの構文に示したように、dtypeパラメーターにデータ型を指定することで、どの型のデータを格納するかを明示することも可能です(dtypeパラメーターについては後述します)。
indexパラメーターを指定しなかった場合、軸ラベル は上の画像から分かるように整数のインデックスとなります。軸ラベル には、ハッシュ可能な値(オブジェクトが存在する間、常に同一の計算結果となり、かつ他のオブジェクトのそれとは重複しない値)を指定できますが、整数以外のものとしては文字列を指定することが多くなるでしょう。
生成したSeriesオブジェクトの要素にアクセスするには、このインデックスを使います。
print(s[1]) # 0.66
dataパラメーターに辞書を渡すと、そのキーが軸ラベル に、キーに対応する値がそのインデックスの値になります。以下に例を示します。
d = {'A': 0.81, 'B': 0.66, 'C': 0.78, 'D': 0.09, 'E': 0.31}
s = pd.Series(d)
print(s)
# 出力結果:
#A 0.81
#B 0.66
#C 0.78
#D 0.09
#E 0.31
#dtype: float64
VS Codeで上記コードを実行した結果を以下に示します。
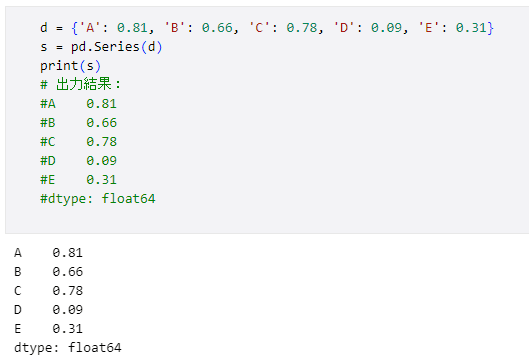 インデックスとしてラベル を付加
インデックスとしてラベル を付加今度はインデックス が'A'、’B'などの文字列になっていることに注目してください。よって、このSeriesオブジェクトの要素にアクセスするにはこのラベルを使います。
print(s['C']) # 0.78
データの格納方法のような細かなことを気にしなければ、Seriesオブジェクトは辞書のようにも使えるといえるかもしれません。
print('A' in d) # True
print('A' in s) # True
print(d['F']) # KeyError
print(s['F']) # KeyError
print(d.get('F', np.nan)) # nan
print(s.get('F', np.nan)) # nan
indexパラメーターを指定する
上の例では辞書を渡すことで、インデックス としてラベルが付加されたSeriesオブジェクトを生成しましたが、indexパラメーターに元データと同じ数の要素を含むリストなどを渡すことで、ラベル付きのSeriesオブジェクトとすることも可能です。
s = pd.Series([0, 1, 2], index=list('ABC'))
print(s)
# 出力結果:
#A 0
#B 1
#C 2
#dtype: int64
ここでは「index=list('ABC')」としていますが、これは文字列'ABC'が反復可能オブジェクトであることを利用して、list関数で3文字の文字列を1文字ずつに分解し、['A', 'B', 'C']というリストを作成し、それをindexパラメーターに渡すことを意味しています。その結果、上の出力結果のようにインデックスが文字列のSeriesオブジェクトが生成されています。
なお、リストやNumPyのndarrayからSeriesオブジェクトを生成するときには、indexパラメーターに指定するインデックスの数は元データの要素の数に合わせる必要があります。
s = pd.Series([0, 1, 2], index=list('ABCD')) # ValueError
例えば、上のコードではリストの要素数は3、indexパラメーターに与えたリストの要素数は4と、一致していないのでValueError例外が発生します。
では、indexパラメーターでラベルを指定するのと同時に、辞書を渡すとどうなるでしょう。まず、元データの要素数とインデックスの数が一致している場合です。
d = {'A': 0, 'B': 1, 'C': 2}
s = pd.Series(d, index=list('BAC'))
print(s)
この場合はもちろん問題ありません。VS Codeでこのコードを実行した結果を以下に示します。
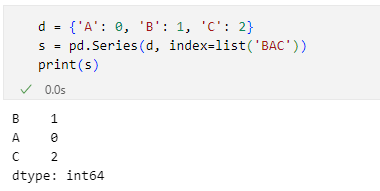 indexパラメーターに指定した順序に行が並んでいる
indexパラメーターに指定した順序に行が並んでいるただし、indexパラメーターにはlist('BAC')つまり['B', 'A', 'C']を渡しています。そして、要素の並び順がこれに沿ったものになっていることが分かります。これはつまり、indexパラメーターの指定によって、要素をどのように並べるかを明示できるということです。何らかの理由で、辞書に含まれる要素の並び順とSeriesの要素の並び順を変えたいときにはこれを使えるでしょう。
次に、indexパラメーターに辞書には存在しないキーをラベルとして含めるとどうなるでしょう。
d = {'A': 0, 'B': 1, 'C': 2}
s = pd.Series(d, index=list('DBCA'))
print(s)
ここではindexパラメーターには['D', 'B', 'C', 'A']を渡しています。そして、'D'をキーとする値は辞書dには含まれていません。このコードを実行すると次のようになります。
 辞書に含まれないものについては、欠損していることを示すNaNが値になる
辞書に含まれないものについては、欠損していることを示すNaNが値になるラベルに含めた'D'に対応する値が、辞書dには含まれていない点に注意してください。ndarrayやリストからSeriesオブジェクトを作成するときにはindexパラメーターに与えるリストの要素数と、dataパラメーターに渡す元データの数が一致する必要がありますが、辞書の場合は同数でなくても構いません。辞書を渡した場合、生成されるSeriesオブジェクトにはラベル'D'に対応する要素が含まれるようになるのですが、その値はデータが欠損していることを示すNaNになっています。
なお、pandas.Seriesコンストラクタのdataパラメーターにスカラー値を渡した場合には、indexパラメーターの指定は必須です。そして、そのときにはindexパラメーターに渡したインデックスの数を要素数とするSeriesオブジェクトが作成され、全ての要素の値はdataパラメーターに渡したスカラー値となります。以下に例を示します。
s = pd.Series(42, index=range(5))
print(s)
# 出力結果:
#0 42
#1 42
#2 42
#3 42
#4 42
この例ではindexパラメーターにはrange(5)を渡しています。range(5)は反復可能オブジェクトでもあり0、1、2、3、4を反復して返します。そして、これらがインデックスとして使われ、dataパラメーターに指定した42が全ての要素の値としてSeriesオブジェクトが生成されているわけです。Seriesオブジェクトの全要素が同じ値となるように初期化したいときには、この方法でオブジェクトを生成するとよいでしょう(この場合なら「pd.Series([42] * 5)」でもよいでしょうけれど)。
copyパラメーターの指定
copyパラメーターにはブーリアン値(TrueかFalse)を指定します。Trueの場合は、dataパラメーターに渡した元データがコピーされて、生成されるSeriesオブジェクトに格納されます。Falseを指定した場合、コピーされません(デフォルトの動作)。なお、これはdataパラメーターにNumPyのndarrayや、pandasのSeriesオブジェクトを渡した場合の動作になります。
copyパラメーターの省略時の動作は「元データをコピーしない」です。これはつまり、元データとSeriesオブジェクトでデータが共有されるということです。そのため、一方でデータを変更すると、それがもう一方にも影響します。以下に例を示します。
a = np.array([0, 1, 2]) # NumPyのndarrayオブジェクトを生成
s = pd.Series(a) # copy=False
s[1] = 10
print(s)
# 出力結果:
#0 0
#1 10
#2 2
print(a) # [0 10 2]
この例ではpandas.Seriesコンストラクタ呼び出しの際に、dataパラメーターにはNumPyのndarrayオブジェクトを渡しています。そして、copyパラメーターの指定は省略しているので、コピーは発生しません。そして、生成されたSeriesオブジェクトの要素を変更してから、Seriesオブジェクトとndarrayオブジェクトの値を表示しているのですが、Seriesオブジェクトに対して行った値の変更がndarrayオブジェクトにも伝わっていることが分かります。こうした挙動を理解しておかないと、慣れてきたころに痛い目に遭うかもしれないので頭には入れておきましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。