[評価関数]決定係数(Coefficient of Determination)R2とは?:AI・機械学習の用語辞典
用語「決定係数R2(R二乗)」について説明。線形回帰モデルの評価関数の一つで、回帰式のモデルによる予測が観測データにどれくらい当てはまるかを表す。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
用語解説
統計学/機械学習における決定係数(Coefficient of Determination、寄与率)のR2(R squared)とは、主に単回帰分析/重回帰分析といった線形回帰(Linear Regression)*1における回帰式のモデルによる予測が「観測データ(正解データ)*2にどれくらい当てはまるか」の割合(通常は0〜1.0=100%、マイナスになることもある)を出力する関数である(図1)。
*1 統計学に基づく線形回帰モデルに入力する各種データは「説明変数」や「独立変数」と呼ばれ、これが機械学習での「入力データ」となる「特徴量」に相当する。また線形回帰モデルでは、モデルから出力される「予測値」は「目的変数」や「従属変数」と呼ばれる。本稿の趣旨から逸脱するのでごく簡略的に示すと、線形回帰のモデルは、説明変数(例えばx1とx2)と目的変数(例えばy)を用いてy=ax1+bx2+cのような式で表現でき、最適化によってパラメーターa/b/cを決定する。
*2 機械学習で「(教師)ラベル」や「正解値」などと呼ぶものは、統計学においては「観測値(observed value)」や「実測値」「実際の測定値」などと呼ばれることが一般的である。

定義と数式
R2の値は一般的に、1(=100%)から「残差平方和÷全平方和」(0以上)を引く計算式で算出される(※ちなみに詳細は割愛するが、この計算式以外にも微妙に異なるさまざまな計算式がある)。下に前述の計算式を示すが、今回は式が複雑そうに見えるのと見慣れない用語が幾つか出ていると思うので、式の部分ごとに分けてどういう意味かを以下で説明していく。

残差変動とは、観測データ(正解データ)がモデルの予測からどれくらいズレているかを示す数値である(数値が大きいほどズレていることになる)。残差変動は、各データに対して「観測値と予測値の差(=残差)」*3を二乗した値を総和する計算(=残差平方和、「平均していない二乗誤差」と同じ計算式)で得られる。
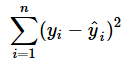
*3 ここでいう「残差(residual)」とは、平均二乗誤差など他の評価関数では「正解値と予測値との差(=誤差:error)」と説明したものと同じものである。
この残差変動を全変動における割合値にするために、上記の数式では「残差平方和を全平方和で割って」いる。
全変動とは、観測データ(正解データ)自体の平均からのバラツキ具合を示す数値である。全変動は、各データに対して「観測値と全観測データの平均値との差」を二乗した値を総和する計算(=全平方和、「平均していない分散」と同じ計算式)で得られる。
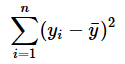
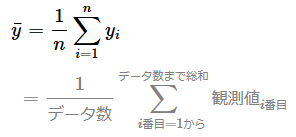
自由度調整済み決定係数について
R2は説明変数(特徴量)の数が増えるほど、1.0に近づく性質がある。その問題を回避するために、自由度調整済み決定係数(Adjusted Coefficient of Determination、Adjusted R2)というR2の応用バージョンがある。この評価指標は、統計ツールの出力結果などでよく見るので、統計処理では広く使われていると考えられる。機械学習ライブラリのscikit-learnには、R2基本バージョンしか搭載されていないので、本稿でも以下に式を示すだけにとどめる。残差平方和がn−k−1で割られ、全平方和がn−1で割られるのがポイントである。kは説明変数の数で、(R2の式にもあった)nはデータ数(サンプルサイズ)である。

用途と特徴
R2は、既に述べた通り、主に線形回帰の評価関数として用いられる。関数から出力される値は、1に近いほどより良い。
前述の式における分数の分子を「平均していない二乗誤差」と説明したように、R2を最大化することは、平均二乗誤差のMSEやRMSEを最小化することと同じ意味合いを持つことになる。
API
機械学習の主要ライブラリでR2は、次のクラス/関数で定義されている。
- scikit-learn: r2_score関数
- TensorFlow(2.x)/Keras: tf.keras.metrics.R2Scoreクラス
- PyTorch: torcheval.metrics.R2Scoreクラス
ここを更新しました(2023年10月2日)
冒頭の決定係数R2の定義がより正確になるように、「回帰式のモデルが」という言い回しを「回帰式のモデルによる予測が」に修正しました。主要ライブラリのTensorFlowとPyTorchの記述を最新情報にアップデートしました。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。