障害の兆候を見逃さないためのサーバ監視:Linux管理者への道(7)(2/3 ページ)
サーバの構築は難しいが、それ以上に困難なのがそれを動かし続けること、そしてトラブルに迅速に対応することだ。サーバの動作状況を監視し、障害の予兆や発生をより早く検知できる体制を整えよう。(編集局)
監視するデータ
集客力のあるサイトを運営しているWebサーバやメーリングリストを運営しているサーバ、ソフトウェアを配布するFTPサーバ、ファイル共有をするためのサーバなどは、クライアントからの非常に多くの要求を処理する必要があります。
サーバの応答が遅い場合は、ハードウェアの増強などで対応する必要があります。ボトルネックの特定のためには、原因がCPUのパワー不足なのか、メモリ容量が足りていないのか、回線容量が細過ぎるのかなどを判断しなければなりません。そのほかにもハードディスク容量、マザーボードの温度、UPSの電力、メールの配送効率、Webページのアクセス解析など、運用中に注意して見ておく必要のあるデータは多くあります。
ここでは、システムを運用するうえで、監視項目として挙げられる主要なデータおよびその確認方法を紹介します。
プロセス
プロセス関連の監視項目には、以下のようなものが挙げられます。
- 総プロセス数
- CPU使用率の高いプロセス
- RAM使用率の高いプロセス
- ゾンビプロセス(defunct)
特定のプロセスを確認したい場合はpsコマンドを使用することが多いのですが、「全プロセスの中でCPU負荷が大きい」あるいは「メモリ使用量が多いプロセスを見つけたい」といった、相対的に負荷が高いプロセスを確認する場合はtopコマンドの利用が適切です。サーバに何か起こった場合は、まずtopで問題のあるプロセスを特定することから作業を始めると思います。
topコマンドは、以下のようにシステム全体の情報を表示します。また、特定の項目でプロセスの並べ替えを行うことが可能です。デフォルトではCPUの使用率が高いプロセス順にソートされていますが、表1の1文字のコマンドを利用することで、目的に応じてプロセスを並べ替えることが可能です。
7:28pm up 26 days, 14:17, 2 users, load average: 0.06, 0.03, 0.11 1.
75 processes: 70 sleeping, 5 running, 0 zombie, 0 stopped 2.
CPU states: 0.5% user, 1.7% system, 6.5% nice, 91.0% idle 3.
Mem: 190748K av,185588K used, 5160K free, 0K shrd, 32284K buff 4.
Swap: 128480K av, 15356K used, 113124K free 85700K cached 5.
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND
2172 root 23 5 2552 2552 1620 R N 3.5 1.3 0:00 read-data.pl
2158 root 15 0 1096 1096 840 R 0.7 0.5 0:00 top
13 root 15 0 0 0 0 SW 0.1 0.0 2:44 kjournald
1 root 15 0 476 440 424 S 0.0 0.2 1:55 init
2 root 15 0 0 0 0 SW 0.0 0.0 0:00 keventd
3 root 15 0 0 0 0 SW 0.0 0.0 0:00 kapmd
4 root 34 19 0 0 0 SWN 0.0 0.0 0:00 ksoftirqd_CPU0
5 root 15 0 0 0 0 SW 0.0 0.0 0:13 kswapd
6 root 15 0 0 0 0 SW 0.0 0.0 0:00 bdflush
7 root 15 0 0 0 0 SW 0.0 0.0 0:00 kupdated
8 root 25 0 0 0 0 SW 0.0 0.0 0:00 mdrecoveryd
64 root 16 0 0 0 0 SW 0.0 0.0 0:00 khubd
164 root 15 0 0 0 0 SW 0.0 0.0 0:00 kjournald
485 root 15 0 608 456 456 S 0.0 0.2 0:00 cardmgr
523 root 15 0 464 416 416 S 0.0 0.2 0:00 apmd
649 root 15 0 1364 1256 1176 S 0.0 0.6 0:24 sshd
(略)
1.起動時間やLoadAverage
2.プロセスに関する情報
3.CPUに関する情報
4.メモリに関する情報
5.スワップに関する情報
| コマンド | 機能 |
|---|---|
| N | プロセスID順 |
| A | 新しいタスク順 |
| P | CPUの使用時間率の長いもの順 |
| M | メモリ使用量が多いもの順 |
| T | 実行時間が長い順 |
| u | 特定のユーザー権限のプロセスだけを表示 (uコマンド入力後、「Which User (Blank for All):」というプロンプトが表示されるので、ユーザー名を入力して[Enter]キーを押す。何も入力しない場合は全ユーザーのプロセスが表示される) |
| s | 表示の更新間隔を指定(単位は秒) (sコマンド入力後、「Delay between updates:」というプロンプトが表示されるので、数値を入力して[Enter]キーを押す) |
| q | TOPの終了 |
| 表1 topのコマンド | |
CPU
計算量が多い処理を行うと、CPU負荷が高くなります。システム全体のCPUの利用状況を確認するためのコマンドとしては、vmstatなどさまざまなものが存在します(上記のtopコマンドでもシステム全体のCPU使用率が表示されます)。
メモリ
メモリおよびスワップの状態を確認するには、freeコマンドが便利です。実行すると、以下のように表示されます。
# free
total used free shared buffers cached
Mem: 54272 52508 1764 12 2068 40984
-/+ buffers/cache: 9456 44816
Swap: 137780 12968 124812
メモリ使用量を確認する際、usedだけを見てしまうと正確な情報が分かりません。Linuxの場合、存在するメモリをできるだけ使用しようとするため、あまりプロセスを起動していなくても、9割以上は使用されている状態になります。
現実的にはfree+buffers+cachedが「自由な領域」と見なせる部分で、freeコマンドの実行例では「-/+ buffers/cache:」のusedが、実際にシステムを動作させるために「必要な」使用メモリです。
ハードディスク
ディスクの使用状況を確認するには、dfコマンドを利用します。通常は、dfの結果を基に、どのディレクトリにあるファイルがディスクを圧迫しているのかをduで確認して対策を考えることになります。
サーバとの接続性
ネットワークの情報は、さまざまな取得方法があります。各サーバとの接続性を確認する最も基本的な方法は、単純にpingを定期実行し、応答にかかる時間とパケットロスを監視することです。ただし、この場合はどこからpingを実行するのか、つまりEcho要求を出すホストとEcho応答を出すホストの経路が重要になることも認識する必要があります。
また、pingが通ったとしても、運用しているサービスが応答を返すかどうかは確認できません。TCPをトランスポート層で利用するサービスであれば、telnetコマンドで各TCPサービスとの接続性を簡単に確認できます。
以下のように、第2引数にポート番号を指定して実行すると、正常にコネクションが確立できる場合は結果1、確立できない場合は結果2のような表示になります。
# telnet xxx.xxx.xxx.xxx 80
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
# telnet xxx.xxx.xxx.xxx 80
Trying 127.0.0.1...
telnet: connect to address 127.0.0.1: Connection refused
トラフィック量
トラフィック量に関しては、後述するSNMPというネットワーク管理プロトコルが広く利用されます。また、エラーパケットの数など基本的な項目に関してはifconfigでも確認できます。
また、netstatコマンドを利用すれば、ネットワークに関するさまざまな情報を取得することができます。netstatの使用方法については、「netstat - ホストのネットワーク統計や状態を確認する」を参照ください。
サービス情報
監視したい項目は、サービスによってさまざまです。例えば、Webサーバであればクライアントの要求に正常に応答を返すか、ページのデータが改ざんされていないか、などを監視する必要があります。また、SMTPサーバであればキューにたまっているメール数などが監視項目として挙げられます。
sysstat(sar)を使ったシステム監視
sysstatは、Linuxで利用できるシステム情報取得ツールです。sar(System Admin Reporter)という、sysstatに含まれるコマンドの中の1つの名称で呼ばれることもあります。
システム状態を確認する際、ある瞬間だけを確認するのではなく、「通常の状態」「異常な状態」の切り分けのために「状態の推移」を確認したい場合があります。sysstatを利用することで、CPUやメモリの使用率、ディスクI/O、トラフィックなど、システムの動作に関するさまざまな統計情報を取得することが可能です。
すでに多くのディストリビューションでサポートされているので、各ディストリビューション付属のsysstatを利用すればよいでしょう。ここでは、Red Hat Linux 8.0付属のsysstatを使って説明しますが、仕組みとしては大きな違いはないので参考になると思います。
sysstatの仕組み
sysstatの主な機能は、システム状態をバイナリデータとして収集するコマンドsadcと、収集したバイナリデータをテキスト形式に変換するsarで実現されます。
sar/sadcコマンド、ログファイルの関係は以下のようになっています。
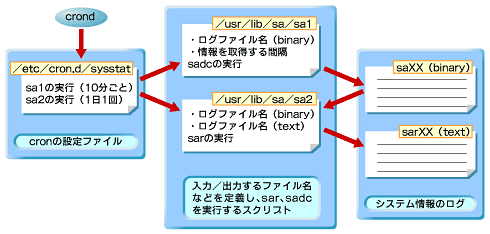
例えば、以下のように実行すると、システムデータを1秒間隔で2回取得し、/tmp/system-dataに書き込みます。
# /usr/lib/sa/sadc 1 2 /tmp/system-data
ただし、このファイルはバイナリデータであるため、参照する場合はsarを以下のように実行する必要があります。
# /usr/bin/sar -f /tmp/system-data
Linux 2.4.18-14 (linux.itboost.co.jp) 03/04/03
09:53:23 CPU %user %nice %system %idle
09:53:24 all 0.00 0.00 0.00 100.00
Average: all 0.00 0.00 0.00 100.00
収集されたデータのうち、どのデータを参照するかはsarのオプションによって異なります。表2に主なオプションを挙げておきますが、初めて利用する場合は-Aオプションで全情報を確認してみることをお勧めします。
sadcコマンドでファイルにデータを落とさなくても、sarコマンド単独でシステム情報の取得が可能です。その場合、第1引数にデータ取得間隔(秒)、第2引数に取得回数を指定して実行します。
# sar 1 5
Linux 2.4.18-14 (linux.itboost.co.jp) 03/01/03
15:56:19 CPU %user %nice %system %idle
15:56:20 all 0.00 0.00 1.00 99.00
15:56:21 all 3.00 0.00 1.00 96.00
15:56:22 all 1.00 0.00 1.00 98.00
15:56:23 all 0.00 0.00 0.00 100.00
15:56:24 all 0.00 0.00 0.00 100.00
Average: all 0.80 0.00 0.60 98.60
| オプション | 引数 | 説明 |
|---|---|---|
| -A | - | 全情報表示 |
| -n | DEV | 送信/受信パケットに関する情報表示 |
| -n | EDEV | エラーパケットなどに関する情報表示 |
| -u | - | CPU使用状況表示。%user+%nice+%systemで100%。%systemが40%を超えるようなら主メモリや入出力デバイス周りに問題がないか、ちゃんと認識されているのかを確認。暴走プロセスも確認する |
| -b | - | ディスクI/Oの使用状況の表示 |
| -r | - | メモリとスワップの使用状況の表示 |
| -W | - | 秒当たりのスワップイン/アウト処理情報表示 |
| 表2 sarのオプション | ||
なお、使用している端末によっては日本語の文字化けが生じます。その場合は、環境変数LANGにCを設定します。
# export LANG=C
# sar -A -f /tmp/system-data
以上、簡単にsadcコマンドとsarコマンドを紹介しましたが、基本的にはcronを利用して定期実行するように設定して使います。一般的な設定としては、以下のsa1、sa2という2つのスクリプトをそれぞれ10分に1回、1日1回実行するようにします。
これらのスクリプトでは、あらかじめデータを保存/参照するファイルの場所を定義したうえで、それぞれsadcコマンドやsarコマンドを実行しています。sa1もsa2も非常に単純なスクリプトなので、簡単に動作が把握できるはずです。
#!/bin/sh
# /usr/lib/sa/sa1.sh
# (C) 1999-2001 Sebastien Godard
#
DATE=`date +%d`
ENDIR=/usr/lib/sa
DFILE=/var/log/sa/sa${DATE}
cd ${ENDIR}
if [ $# = 0 ]
then
${ENDIR}/sadc 1 1 ${DFILE}
else
${ENDIR}/sadc $* ${DFILE}
fi
#!/bin/sh
# /usr/lib/sa/sa2.sh
# (C) 1999-2001 Sebastien Godard
#
S_TIME_FORMAT=ISO ; export S_TIME_FORMAT
DATE=`date --date=yesterday +%d`
RPT=/var/log/sa/sar${DATE}
ENDIR=/usr/bin
DFILE=/var/log/sa/sa${DATE}
[ -f "$DFILE" ] || exit 0
cd ${ENDIR}
${ENDIR}/sar $* -f ${DFILE} > ${RPT}
find /var/log/sa \( -name 'sar*' -o -name 'sa*' \) -mtime +7 -exec rm -f {} \;
sysstatのインストール
sysstatは以下のWebサイトから入手することもできます。ここではソースアーカイブをダウンロードしてインストールする手順を簡単に紹介します。
http://perso.wanadoo.fr/sebastien.godard/
# tar zxvf sysstat-4.1.2.tar.gz
# cd sysstat-4.1.2
# make config
# rm -f sadc sa1 sa2 sysstat sar iostat mpstat *.o *.a core TAGS data
crontab
# rm -f sapath.h
# find nls -name "*.mo" -exec rm -f {} \;
You can enter a ? to display a help message at any time...
Installation directory: [/usr/local] ←インストールディレクトリの指定
System activity directory: [/var/log/sa] ←ログディレクトリの指定
Clean system activity directory? [n] ←ログディレクトリにあるファイルを削除するかどうか
Enable National Language Support (NLS)? [y] ←国際化をサポートするか
Linux SMP race in serial driver workaround? [n] ←SMP(Symmetric MultiProcessor)をサポートするか
sa2 uses daily data file of previous day? [n] y ←sa2スクリプトは前日の集計データを対象とするのかどうか
Number of daily data files to keep: [7] ←いくつファイルを保存しておくのか
Group for manual pages: [man] ←manページの保存場所の指定(この場合は/usr/local/man)
Set crontab to start sar automatically? [n] y ←cronで自動実行させるかどうか
Crontab owner (his crontab will be saved in current directory): [adm] ←root crontabのオーナー指定
man directory is /usr/local/man
rc directory is /etc
init directory is /etc/init.d
Creating CONFIG file now... Done.
# make config
# make
# make install
Copyright © ITmedia, Inc. All Rights Reserved.