機械学習の前に重要なデータ抽出・加工に便利なPythonライブラリ「pandas」の基本的な使い方のチュートリアル:Pythonで始める機械学習入門(6)(3/4 ページ)
欠損値の処理
データ分析でよく問題になるのが欠損値の処理です。ここで以下の説明のためにわざと欠損値を入れてみます。
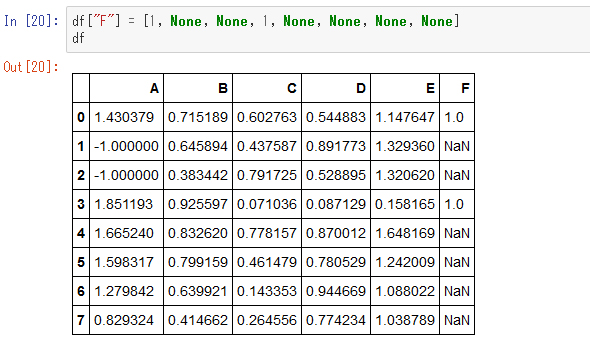
F列にNoneを代入したはずなのですが、一覧を表示するとNaNとして表示されます。これはpandasでは、デフォルトでは欠損値は「NaN」として扱われることになっているからです。
欠損値を無視する「dropna」メソッド
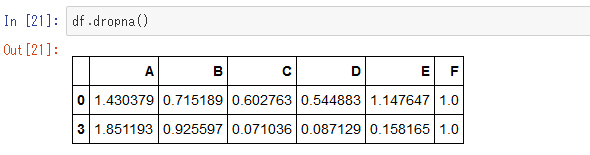
「欠損値を無視してデータを分析したい」ことがよくあると思いますが、それは「dropna」メソッドによって簡単にできます。
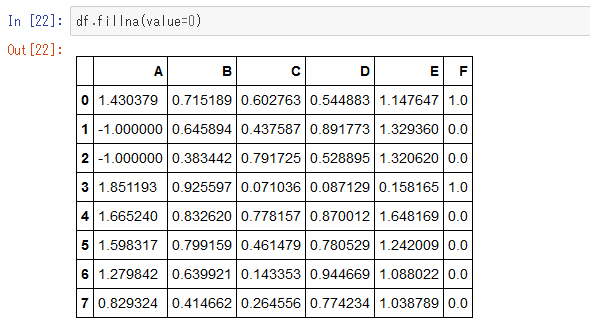
欠損値を特定の値で書き換える「fillna」メソッド
また、欠損値を特定の値で書き換えたいこともあると思います。そういう場合は「fillna」メソッドを使います。ここでは欠損値に0を代入しました。
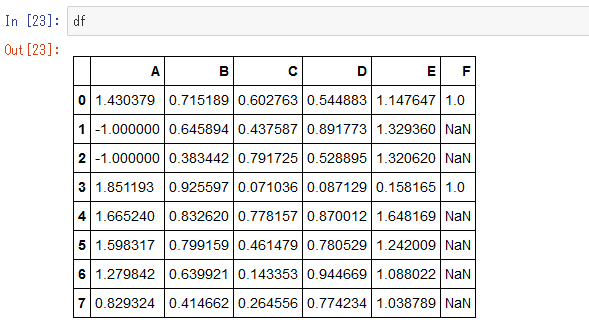
dropnaもfillnaも元のデータは変わっていない
dropnaもfillnaも破壊的な操作ではない(もとのdfの値を書き換えない)ので注意が必要です。実際には戻り値を他の変数に入れて使うことが多いです。ここでdfの中身を表示すると元から変わっていないことが分かります。
集計演算
縦列のデータの平均値を求める「mean」メソッド、標準偏差を求める「std」メソッド
次のように縦に集計することもできます。
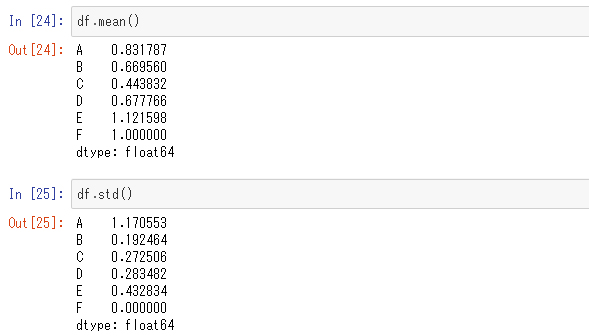
「mean」メソッドでは平均値を、「std」メソッドでは標準偏差を求めました。
任意の関数を適用する「apply」メソッド
「apply」メソッドを使うと、任意の関数を適用することもできます。次の例では、各列について最大値と最小値の差を計算します。

グループ化
次に、グループ化の例を示すために、さらに一列を追加します。
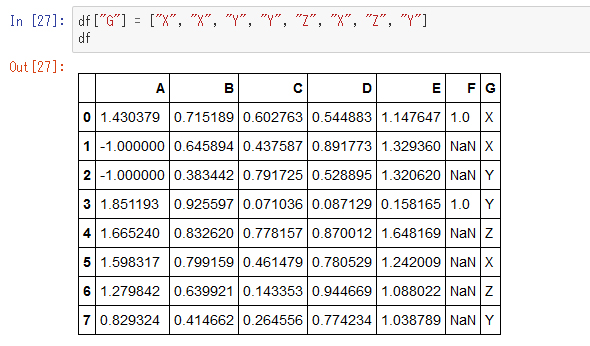
これをG列の値をキーとしてグループ化し集計してみます。これはSQLの「GROUP BY」に相当します。
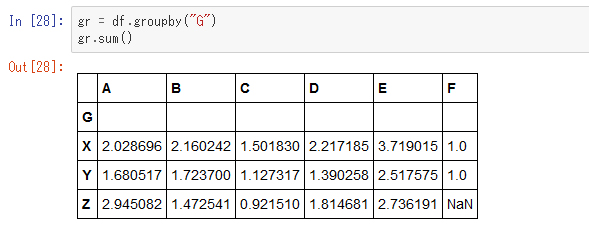
ここでは、sum()で合計を計算していますが、他の集計も同様にできます。また、グループ化のキーはインデックスとして扱われています。
キーをインデックスとして扱いたくないときは、「as_index」フラグ
キーをインデックスとして扱いたくないときは、「as_index」フラグを利用します。
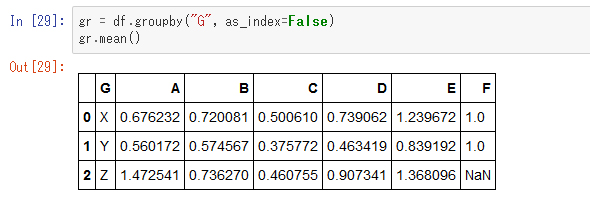
今度は平均値を計算しました。G列がインデックスではなく通常の列として扱われ、インデックスは別途連番が付与されています。
関連記事
 機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
本連載では、さまざまなソフトウェアのインストール、実行するためのセットアップ設定、実行確認、アンインストールの手順を解説する。今回は、Pythonとは何か、Pythonのインストールとアンインストールについて解説。Pythonがよく使われる機械学習やビッグデータ解析を始める参考にしてほしい。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。