計算高速化のための強力な武器、NumPyのブロードキャスティングとSciPyの疎行列処理:Pythonで始める機械学習入門(4)(1/2 ページ)
最近流行の機械学習/Deep Learningを試してみたいという人のために、Pythonを使った機械学習について主要なライブラリ/ツールの使い方を中心に解説する連載。今回は、うまく使うと計算時間を短縮できるNumPyのブロードキャスティングと、機械学習で利用価値の高いSciPyにおける疎行列の扱い方を取り上げる。
プログラミング言語「Python」は機械学習の分野で広く使われており、最近の機械学習/Deep Learningの流行により使う人が増えているかと思います。一方で、「機械学習に興味を持ったので自分でも試してみたいけど、どこから手を付けていいのか」という話もよく聞きます。本連載「Pythonで始める機械学習入門」では、そのような人をターゲットに、Pythonを使った機械学習について主要なライブラリ/ツールの使い方を中心に解説していきます。
連載第1回の「Pythonで機械学習/Deep Learningを始めるなら知っておきたいライブラリ/ツール7選」では、ライブラリ/ツール群の概要を説明しました。前回は、その中でもJupyter Notebookの基本操作と設定について説明しました。
前回から連載第1回で紹介した各種ライブラリを使う具体的なコードを例示していますが、Jupyter Notebook形式で書いています。今回は前回の「機械学習の基礎の基礎、行列計算に欠かせないNumPyの基本的な使い方」に引き続き、NumPy、SciPyの基本を説明します。
最初に、NumPyのロードキャスティング機能を解説し、次に、機械学習で特に利用価値の高いSciPyの疎行列について説明します。
なお本稿では、Pythonのバージョンは3.x系であるとします。
NumPyのブロードキャスティング
ブロードキャスティングとは、配列の要素に、演算(数値(スカラー値)との四則演算や関数など)を作用させることを意味します。
NumPyにおける配列の四則演算
例えば、aが配列のときに「a+1」はaの全ての要素に1を足すことになります。

掛け算についても同様です。これはベクトルや行列の「スカラー積」と同じです。

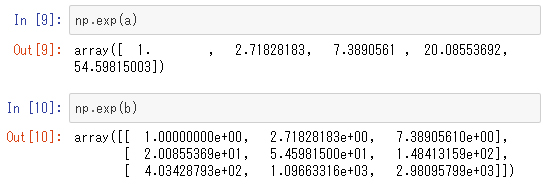
各要素のexpを取る
NumPyでは、四則演算に限らず、幾つかの組み込み関数でもブロードキャスティングが行えます。
例えば、「numpy.exp」(指数関数)を配列に作用させると、各要素のexpを取ることになります。
ユニバーサル関数とは
全ての関数について、このような操作ができるわけではありません。ブロードキャスティング可能な関数を「ユニバーサル関数」、または略して「ufunc」と呼びます。
例えば、numpy.expを表示させてみると次のように「ufunc」と表示されます。

numpy.expが、ユニバーサル関数であることが分かります。
二項演算子を使ったブロードキャスティング
ブロードキャスティングは、二項演算子を使うことで、2つの配列についても用いることができます。
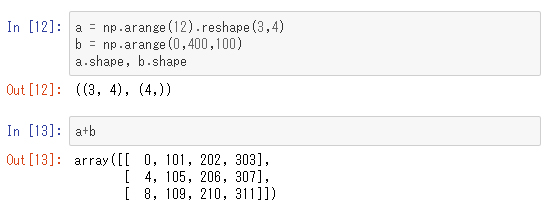
このように2次元配列と1次元配列について二項演算子でのブロードキャスティングができるのは、1次元配列のサイズが2次元配列の列数(shapeの2つ目の値)に一致するときに限ります。このときの計算は下記に相当します。
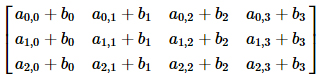
これは他の二項演算をしたときも同じで、上記の式で加法を他の演算に置き換えたものになります。

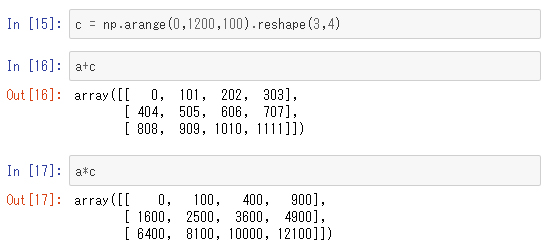
形状(shape)が全く同じ配列同士の二項演算
形状(shape)が全く同じ配列同士の二項演算は、要素ごとの演算に一致します。加法については、たまたま行列やベクトルの加法に一致しています。
ブロードキャスティングで計算時間を短縮
以上、ブロードキャスティングについて説明しましたが、ここでは機械学習で必要になるであろう2次元までの配列(つまり数学的には、ベクトルと行列)に絞って説明しました。一般的には、多次元配列(数学的にはテンソル)について、ブロードキャスティングのルールが決められています。一般的なブロードキャスティングのルールについて知りたい方は、NumPyの公式ドキュメントを参照してください。
ブロードキャスティングは、配列を「ベクトル」や「行列」と見なすと数学的視点ではあまり使われない計算ですが、「表」と見なしたときの集計計算だと考えると分かりやすいかもしれません。
一方でブロードキャスティングを多用すると、コードとしてはあまり直感的でなく、分かりづらくなることもあるかもしれませんが、Pythonでは、for文などを使った明示的なループを使った集計計算は処理が遅くなることが多く、ブロードキャスティングをうまく利用することで計算時間を短縮できることがあります。
関連記事
 機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
本連載では、さまざまなソフトウェアのインストール、実行するためのセットアップ設定、実行確認、アンインストールの手順を解説する。今回は、Pythonとは何か、Pythonのインストールとアンインストールについて解説。Pythonがよく使われる機械学習やビッグデータ解析を始める参考にしてほしい。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。