TensorFlow 2.0 α版で何が変わる? 新機能の概要 ― TensorFlow Dev Summit 2019:イベントから学ぶ最新技術情報
ついにTensorFlow 2.0 α版がリリースされた。TensorFlowにとって初めてのメジャーバージョンのアップデートになる。初期リリース〜2.0正式リリースまでの歩みを示し、2.0の新機能の概要を紹介する。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
ご注意:本記事は、@IT/Deep Insider編集部(デジタルアドバンテージ社)が「deepinsider.jp」というサイトから、内容を改変することなく、そのまま「@IT」へと転載したものです。このため用字用語の統一ルールなどは@ITのそれとは一致しません。あらかじめご了承ください。
2019年3月6日〜7日(米国時間)に開発者カンファレンス「TensorFlow Dev Summit 2019」が開催された。そこでTensorFlow 2.0のα(Alpha)版のリリースが発表され、現α版時点での新機能と改変の内容が説明された。
最初に、ライブラリ「TensorFlow」の利用者にとって一番重要な改変ポイントだけ、簡単に示しておこう。それは、
- tf.keras(TensorFlow向けに拡張されたKeras)が、TensorFlow標準の高レベルAPIになったこと
- Eager実行(Eager execution:即時実行)がデフォルトの実行モードになったこと
の2点である。
1点目については、tf.kerasが標準化されたことに伴い、TensorFlow 1.x時代に乱立したいくつかの高レベルAPIが排除されることになった。1.x時代(執筆時点)においても高レベルAPIを使う場合は、シンプルで使いやすいAPIのtf.kerasを使用するのが一般的ではあった。ただし、分散深層学習といったスケーラブルな機能が必要な場合は、同じく高レベルAPI(むしろ“中”レベルAPIとも言うべき)のtf.estimator(Estimators)を使う必要があった。TensorFlow 2.0以降でもtf.estimatorは残されており使用できるが、そのパワーはtf.kerasにも統合されている。つまり2.0では、tf.kerasでも分散深層学習が可能になっている。
2点目については、TensorFlow 1.xまで静的な「グラフ」モードがデフォルト挙動だったが、2.0以降では動的な「Eager実行」モードがデフォルト挙動に変更された。Eager実行になると、Pythonコーディング環境でのデバッグ作業などがやりやすくなるという利点がある。特に機械学習モデルのプロトタイピングや研究段階の作業では非常に役に立つ機能だ。それでいて、「AutoGraph」(自動グラフ)という機能により、パフォーマンスの良さや、エキスポートしやすさといった「グラフ」モードの利点も併せて享受できる。つまり良いところ取りである。
これらの話を中心に、本稿では、主に基調講演の内容から、TensorFlow 2.0 α版の新機能の概要をコンパクトにお伝えする。
まず前半では、TensorFlow 2.0への歩みと、実際のリリース時期について紹介する。後半では、どのような機能が追加されるのかの概要を見ていく。
TensorFlowの歩みとバージョン2.0
これまでの歩み
現在、TensorFlowは非常に速いスピードでアップデートされてきている。その歩みは、
- 2015年11月: TensorFlowの最初のβ版リリース
- 2017年02月: バージョン1.0のリリース
- 2017年04月: バージョン1.1で、Kerasを統合
- 2017年11月: Eager実行(Eager execution)モードを発表
- 2018年03月: Eager実行モードが実験的なcontrib機能から標準機能に昇格
- 2019年03月: バージョン2.0α版リリース(※本稿の執筆時点)
となっており(図1)、たった3年4カ月間で大きな躍進を果たしている(※リリース履歴はこちら)。

現在のTensorFlowの利用状況
今や、世界中の人々が、GitHub:tensorflow/tensorflowにスターを付けている(図2はスターを点にした世界地図)。

そのダウンロード数は4100万にものぼる(図3)。

これからの歩み
そんなTensorFlowの次期メジャーバージョン「2.0」のα版が、2019年3月6日(米国時間)のTensorFlow Dev Summit 2019に合わせてリリースされたわけだが、あくまでこれはバージョン2.0の初期プレビュー(=α版)リリースという位置付けである。これから2〜3カ月かけて、正式版に向けた実装のテストと最適化が進められていくことになる。そういった作業が終わるのが、春ごろ(※「春」の定義はあいまいではあるが……)を目指しているとのこと。通常のアップデートリリースよりも時間がかかる見込みだ。RC版が出てから、(1.0の時と同じなら恐らく1カ月後くらいで)最終の正式版がリリースされる予定である。まとめると今後は、
- 2019年の春(Q2、5〜7月?): バージョン2.0 RC(正式リリース候補)版の公開
- 2019年の春〜夏ごろ(6〜8月)か?: バージョン2.0正式リリース
といったタイムラインでリリース作業が進められていくと考えられる(図4)。

より細かくプロジェクトの進捗をフォローしたい人は、
をウォッチしてほしい。

それでは、TensorFlow 2.0の概要説明に入っていこう。
TensorFlow 2.0の方向性
これまでのTensorFlow 1.xの利用者からは、
- APIをもっとシンプルにしてほしい
- 不必要で複雑な部分を減らしてほしい
- ドキュメントとサンプルプログラムを改善してほしい
といったフィードバックや要望が寄せられていたという。というのも、TensorFlow 1.xには試験的にさまざまな機能が、しかも重複を気にせずに搭載されてきた、という問題があったからだ。例えばディープラーニングのモデルを簡単に作る高レベルAPIが、何種類も存在していた(具体的には、tf.keras、tf.estimator、tf.layers、tf.contrib.learn、tf.contrib.slimなど)。利用者から見ると、「どれを使うべきか判断しづらい」「サンプルプログラムの書き方が高レベルAPIの種類ごとに違うので、サンプルコードも選ぶ必要がある」といった課題があった。
TensorFlow 2.0は、これらの要望に応えるべく、
- 簡単: よりシンプルなAPI。具体的には、高レベルAPIをKerasに集約し、Eager実行をデフォルトにすること
- パワフル: 柔軟性とパフォーマンス。具体的には、さまざまなカスタマイズ機能を提供し、パフォーマンスを継続的に改善していくこと
- スケーラブル: Googleスケールでの徹底的な大規模テストをしており、学習済みモデルをどんなところにもデプロイできること
といった点を重視していく(図6)。
 図6 TensorFlow 2.0の方向性(基調講演より)
図6 TensorFlow 2.0の方向性(基調講演より) 「exa」(エクサ:E)とは10の18乗のことで、メガ(M)、ギガ(G)、テラ(T)、ペタ(P)の次の単位。FLOP(FLoating point number Operations Per Second)とは、1秒間に浮動小数点演算が何回できるかの指標値のことで、性能を測る指標となる。
「scale to > 1 exaflops」とは、オークリッジ国立研究所の最先端研究(cutting edge research)を行うチームが、高性能コンピューティングとTensorFlowを使用して1.13 exaFLOPSを達成したことを指しており、それほどのハイパフォーマンスまでスケール可能ということを示唆している。
本稿では、上記の「簡単」「パワフル」の2点について、さらに掘り下げて見ていこう。
1. 簡単:よりシンプルなAPI
全体構成
新しいTensorFlow 2.0の全体構成をまとめると、図7のようになる。

左側が訓練(TRAINING)時に使う機能、右側が運用環境へのデプロイ(DEPLOYMENT)時から使う機能である。
右側を見ると、これまでどおり、デプロイ先はさまざまなものが用意されている(※既存の機能なので説明は割愛)。
左側にある訓練時の機能には変更があったので、訓練時のワークフローについてより細かく見てみよう。

図7の左から、最初に「データの取得と加工」をtf.dataを使って行い、機械学習モデルに入力する特徴データを作成する。なお、tf.estimator(Estimators)の機能を使う場合は、特徴カラム(Feature Columns: 生データとEstimatorsの間の中間物)も作成する。
次に、「モデル構築」をtf.keras(Keras)で行う。もちろん、低レベルAPIにより完全に独自のカスタムモデルを作ったり、“中”レベルAPIのtf.estimatorで事前に作成された標準的な機械学習モデルのパッケージ(Pre-made Estimators)を使ったりすることもできる。
さらに、「訓練」をEager実行(即時実行)とAutoGraph(自動グラフ)で行う。繰り返しになるが、TensorFlow 2.0では、Eager実行モードがデフォルトの挙動となった(※TensorFlow 1.xではグラフモードがデフォルトの挙動)。この2つの機能は、次節でもう少し詳しく説明しよう。
最後に、「保存」をSavedModel形式で行う。保存したパッケージは、前述のとおり、さまざまな運用環境にデプロイできる。
Eager実行
Eager実行とは、ライブラリ「Chainer」など(※実際にChainerからインスパイアされた機能)で言うdefine-by-run(通常のPythonコーディングと同じように、定義と実行が同時に行われる)と同じ実行方法のことである。
Eager実行では、従来のようにわざわざデータフローグラフを事前に定義したうえで、セッション(tf.Session)を明示的に開始し、それから実行(run())する(これをdefine-and-runと呼ぶ)、という複数段階の手順を踏む必要がない。例えば図8-1にあるPythonコードの制御フロー(while文)は、即時に実行されることになる。

このため、モデルを構築する際のデバッグがしやすくなるので、効率的に機械学習の実装を進められるという利点がある。
AutoGraph
AutoGraphとは、通常のPythonコードを自動的にTensorFlowのグラフに変換する機能である。従来は、TensorFlowの「テンソル」を使ってデータフローグラフを定義していた。
新しいAutoGraph機能では、煩雑なテンソルに関する記述をしなくても、自然でシンプルなPython構文を使ってグラフが定義できるようになるというわけだ。例えば図8-2にある関数定義(@tf.functionデコレーターが付加されたdef文)のPythonコードによって、そのグラフが生成されることになる。

この機能により、グラフの利点であるパフォーマンスの良さや、モデルのエキスポートしやすさといった、従来の利点も維持できる。
TensorFlow 2.0では、Eager実行だけでなく、@tf.function+AutoGraphによるグラフであっても、デバッグ機能が強化されている。例えば図8-3ではモデルのグラフ内に、split関数の引数に指定した数値がエラーを起こしているが、そのエラーの内容が通常のPythonコーディングと同じように見られることを示している。より効率的にディープラーニングを実装していけるというわけだ。

少し脱線したが、「訓練時のワークフロー」に話を戻す。これらの手順のいくつかについて、実際の例を見てみよう(※以下の内容は、TensorFlow 1.xでも実装できることが含まれているので、注意してほしい。TensorFlow 2.0における典型的な訓練ワークフローを説明しているだけである)。
TensorFlow Datasetsによる公開データの取得
「共通する公開データを使って、ディープラーニングの結果を複数のモデル間で比較して、新しい考えがより良いものかを検証したい」ということがよくある。TensorFlowには、そのような場面で使える公開データセットが多数用意されており、TensorFlowのコードから簡単に利用できる。具体的には図9に示すように、TensorFlow Datasets(tensorflow_datasetsモジュール)を使って公開データセット(この例では'fashion_mnist')を(tf.data.Datasetオブジェクトとして)取得できるので、あとは目的に合わせて入力データ用に加工すればよい。

TensorFlowで使える主要な公開データセットを図10に示す。これら以外にも、さらに多くのデータセットが用意されている。

tf.kerasによるモデル構築
現在(※執筆時点)のTensorFlow 1.xにおけるtf.kerasを使ったコードは、基本的に何も変更することなく、そのままTensorFlow 2.0でも使える。図11はその例で、Kerasを使用している人であれば、見慣れたコードである。ただし、コード自体は変わっていないが、内部の挙動は、グラフモードからEager実行モードに変わっているので、注意してほしい。
 図11 tf.kerasを使った基本的なコードはそのまま動く(基調講演より)
図11 tf.kerasを使った基本的なコードはそのまま動く(基調講演より) 深層学習の分散戦略
ディープラーニングの学習は、計算コストが高くなる(=時間がかかる)ことが多い。そういった場合には、学習を複数デバイスに分割して、それをスケールさせる分散戦略(Distribution Strategy)を採るとよい。いわゆる分散深層学習(Distributed Deep Learning)である。
冒頭で述べたように、TensorFlow 2.0のtf.kerasは、分散深層学習に対応している。具体的には、tf.distribute.MirroredStrategyクラスを利用して、図12のようにして行えばよい。
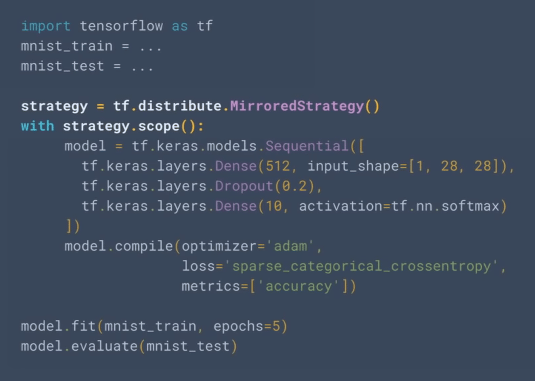 図12 tf.kerasも分散深層学習に対応(基調講演より)
図12 tf.kerasも分散深層学習に対応(基調講演より) TensorFlow Hubの活用
従来できたことではあるが、TensorFlow Hubで公開されている学習済みモデルを使えば(図13、図14)、さらに計算コストを削減できるだろう。

![図14 学習済みモデルは[Copy URL]でURLを取得して使う(基調講演より)](https://image.itmedia.co.jp/l/im/ait/articles/1903/14/l_di-14.gif)
2. パワフル:柔軟性とパフォーマンス
さて、ここまでよりシンプルなAPIを使って簡単にディープラーニングが行えることを示した。最後に、そのAPIがいかにパワフルであるかを示していこう。
強力かつ柔軟なAPI群
すでに説明済みのように、TensorFlow 2.0には、高レベルAPIとしてtf.kerasと、それにも組み合わせられる“中”レベルAPIのtf.estimatorが、最初から標準搭載されている。これらのAPIが提供してくれる「高レベルのビルディングブロック(building blocks:構築要素)」は、多くの機械学習のケースで、活用できるだろう(図15の上)。

しかし、ビルディングブロックでは足りないケースというのもある。例えば新しいアルゴリズムを試す場合などだ。そのようなケースでは、図15の下にあるように、サブクラス化やカスタムループ機能を使って、完全に独自のカスタムモデルを作ればよい(※これはTensorFlow 1.xでも実現できる)。
Kerasには、主に次の3種類のAPI(実装方法)が用意されている。
- Sequential API: 積層型。入門者でも使えるが、シンプルなものしかできない
- Functional API: 関数型。入門者でも使えて、より自由な構成が可能
- Subclassing API: サブクラス型。難易度は少し上がるが、フルカスタマイズが可能
サブクラス化とは、3つ目のSubclassing APIを使うことである。図16はその例で、モデル(tf.keras.Model)を基本クラスとして、Encoderサブクラス(=機械翻訳のカスタムエンコーダー)を実装している。このようにして、カスタムモデルを実装できる。

カスタムループとは、訓練時のループ処理をカスタマイズすることである。この機能によって、勾配の計算方法と最適化処理を完全にコントロールできる。例えば図17では、実際に勾配の計算方法(gradients)と最適化処理(optimizer.apply_gradients())を独自に定義している。

このような訓練時のループのカスタマイズは、学習の進行状況を把握し、モデルを詳細に分析できるという価値がある。その際には、おなじみの可視化(ビジュアライゼーション)ツールであるTensorBoardが使える。
TensorBoardは今や、Jupyter NotebookやGoogle Colaboratoryに統合されており、ノートブックの中でも同じ可視化ツールを表示できる(図18)。

TensorFlow 1.xからの移行方法
多くのAPIが削除されているので、既存のTensorFlow 1.xで書いたコードを2.0にアップグレードして移行するのは難しいかもしれない、と考える人も少なくないだろう。そんな人のための救済手段も、いくつか準備されている。具体的には、
- 変換スクリプト: 1.xからのアップグレードを支援するスクリプトで、tf_upgrade_v2 --infile tensorfoo.py --outfile tensorfoo-upgraded.pyのようなコマンドで実行する
- 1.x互換モジュール: 排除されてしまった1.x時代のAPIを、互換性のためにまとめたtensorflow.compat.v1モジュール
- 移行のためのドキュメント: 「Convert Your Existing Code to TensorFlow 2.0」
が用意されている。
パフォーマンス
パフォーマンスは多くの人にとって重要だろう。TensorFlowの訓練時におけるパフォーマンスは、継続的に改善されてきているという。例えば図19は2018年の改善結果で、1.8倍、1.6倍、3.3倍という数値が並んでおり、大きく改善されてきているのが分かる。

TensorFlow 2.0においても、パフォーマンスは重要課題の一つとして位置付けられており、正式リリースまでに高めていくそうだ。
また、推論時のパフォーマンスは図20のようになっており、今後も改善していくとのこと。

アドオンライブラリによる拡張
TensorFlowを拡張するためのアドオンライブラリ(や将来的な機能など)も多数用意されている。例えば、
- TensorFlow Agents: 強化学習のための追加ライブラリ
- TensorFlow Federated: フェデレーション学習のための追加ライブラリ
- TensorFlow Privacy: プライバシー保護のための追加ライブラリ
などがある。代表的なアドオンライブラリの名前を、図21に記載している(※「TF」の表記は「TensorFlow」の意味)。

利用可能なアドオンライブラリは、
で見つけられる。
まとめ
以上、tf.kerasの標準化とEager実行モードを中心に、TensorFlow 2.0α版の新機能・更新機能などを紹介した。
ちなみに今回の発表時に、TensorFlowのアイコンデザインも変わっている。また、TensorFlow.jsはバージョン1.0が発表&リリースされた。
その他にもいくつかの発表があった。今回の発表内容全般については、下記のリンク先でまとめられている。
より詳しく知りたい人は、以下の動画を視聴してほしい。
TensorFlow 2.0α版のドキュメントも、公式サイトにすでに公開中である。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。