[活性化関数]PReLU/Parametric ReLU(Parametric Rectified Linear Unit)とは?:AI・機械学習の用語辞典
用語「PReLU(Parametric ReLU)」について説明。「0」を基点として、入力値が0より下なら「入力値をα倍した値」(αはパラメーターであり学習により決まる)、0以上なら「入力値と同じ値」を返す、ニューラルネットワークの活性化関数を指す。ReLUやLeaky ReLUの拡張版。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
用語解説
AI/機械学習のニューラルネットワークにおけるParametric ReLU(Parametric Rectified Linear Unit:PReLU)とは、関数への入力値が0より下の場合には出力値が入力値をα倍した値(※αはパラメーターであり学習によって決まる)、入力値が0以上の場合には出力値が入力値と同じ値となる関数である。
上記の内容はLeaky ReLUとほぼ同じ説明であるが、α倍の値が、Leaky ReLUでは手動で指定した固定値(基本的に0.01)であるのに対し、Parametric ReLUでは「Parametric(パラメーターの)」という言葉の通り、学習によって動的に決まるパラメーター値である点が異なる。つまりPReLUは、Leaky ReLUの拡張版である。
また、Leaky ReLUと同様にReLUの拡張版でもある。ReLUでは入力値が0以下の場合は出力値が常に0だが、PReLUでは入力値が0より下の場合、出力値は学習によって動的に決まるパラメーターによって(基本的に)0より下の値を返す。
Leaky ReLUとほぼ同じグラフになるが、図1では、ReLUとPReLUのグラフの違いを示している。なお、PReLUのグラフは、パラメーターであるαが0.01の場合の例である。この場合、オレンジ色(PReLU)の線の左側がわずかに下がっている点が、青色(ReLU)の線と異なる特徴だ。PReLUのグラフは基本的にこのような形になるはずだが、パラメーターの値は動的に決まるので、入力値xが0より下の範囲では、その線の傾き(=α倍)は学習のたびに変化してくことになる。PReLUは、Leaky ReLUと同様の理由で、「dying ReLU」(死にかけているReLU)問題を解消する。dying ReLUとは、元々のReLUでは入力値が0以下では出力値が常に0となるので、勾配がなくなってしまい、場合によっては学習が進みにくくなる問題のことである。

現在のディープニューラルネットワークでは、隠れ層(中間層)の活性化関数としては、ReLUを使うのが一般的である。しかし、より良い結果を求めて、ReLU以外にもさまざまな代替の活性化関数が考案されてきている。(本稿で解説する)PReLUは、そのReLUそのものを拡張した活性化関数である。
まずは、ReLUを試した後、より良い精度を求めてPReLUに置き換えて検証してみる、といった使い方が考えられる。2015年の論文「arXiv:1502.01852v1 [cs.CV]」や「arXiv:1502.01852 [cs.CV]」によると、画像分類タスクにおいてReLUよりも良い精度になったことが示されている。
主要ライブラリでは、次の関数/クラスで定義されている(※Leaky ReLUと異なり、いずれもαの値を手動で指定する必要はない。初期値は指定することもできる)。
定義と数式
冒頭では文章により説明したが、厳密に数式で表現すると次のようになる。
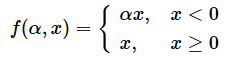
αがパラメーターで、xが入力データ、f(α,x)が出力結果である。
x < 0の場合は、f(α,x)=α * xとなり(※αは学習により決まる)、
x ≧ 0の場合は、f(α,x)=xとなる。
上記の数式の導関数(Derivative function:微分係数の関数)を求めると、次のようになる。

PReLUはReLU関数と同様に、非連続な関数であり、数学的にはx=0の地点では微分ができない。
PReLUの導関数をニューラルネットワーク内で使うために、便宜的にx=0を微分係数1の方に含めることにする。これにより、次のような導関数が求まる。
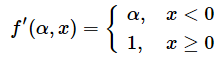
Pythonコード
PReLUは学習用のパラメーターを含むので、単なるPythonコードを示すだけでは使い勝手が悪いだろう(※そもそも数式の直接的な実装は、Leaky ReLUと同じである)。そこで、TensorFlow/KerasとPyTorchの各ライブラリに搭載されているPReLUクラスを使用する簡単なコード例を示す。
TensorFlow/Kerasの場合
import tensorflow as tf
prelu = tf.keras.layers.PReLU(
# α値の初期値(この例では「0.01」)を指定する
alpha_initializer=tf.constant_initializer(0.01))
# この活性化関数を使ったニューラルネットワークのモデルをトレーニングする...(コードは割愛)
# 「-1.0」を入力した場合の出力値:
print(prelu(-1.0))
# 出力例: tf.Tensor(-0.01, shape=(), dtype=float32)
# 学習したパラメーター「α」の値を取得する方法:
print(prelu.weights)
# 出力例: [<tf.Variable 'p_re_lu/alpha:0' shape=() dtype=float32, numpy=0.01>]
TensorFlow/Kerasの場合、α値はPReLUオブジェクトのweightsプロパティにより取得できる。
PyTorchの場合
import torch
import torch.nn as nn
prelu = nn.PReLU(
# α値の初期値(この例では「0.01」)を指定する
init=0.01)
# この活性化関数を使ったニューラルネットワークのモデルをトレーニングする...(コードは割愛)
# 「-1.0」を入力した場合の出力値:
print(prelu(torch.tensor(-1.0)))
# 出力例: tensor(-0.0100, grad_fn=<PreluBackward>)
# 学習したパラメーター「α」の値を取得する方法:
print(prelu.weight)
# 出力例: Parameter containing:
# tensor([0.0100], requires_grad=True)
PyTorchの場合、α値はPReLUオブジェクトのweight変数により取得できる。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。