[データ分析]クロス集計表やヒートマップで「分布」を多角的に可視化 〜 項目同士の関連を見つける:やさしいデータ分析
データ分析の初歩から応用まで少しずつステップアップしながら学んでいく連載の第11回。グラフを利用して分布や項目同士の関係を多角的に可視化します。ピボットテーブルの詳細な取り扱いとヒートマップによる視覚的な分析について、ケーススタディを通して学びましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
連載:

この連載では、データをさまざまな角度から分析し、その背後にある有益な情報を取り出す方法を学びます。
データの収集方法、データの取り扱い、分析の手法などについての考え方を具体例で説明するとともに、身近に使える表計算ソフト(ExcelやGoogleスプレッドシート)を利用した作成例を紹介します。
必要に応じて、Pythonのプログラムや統計ソフトRなどでの作成例にも触れることにします。
数学などの前提知識は特に問いません。肩の力を抜いてぜひとも気楽に読み進めてください。
 羽山博
羽山博筆者紹介: IT系ライターの傍ら、非常勤講師として東大で情報・プログラミング関連の授業を、一橋大でAI関連の授業を担当。書道、絵画を経て、ピアノとバイオリンを独学で始めるも学習曲線は常に平坦。趣味の献血は、最近脈拍が多く99回で一旦中断。さらにリターンライダーを目指し、大型二輪免許を取得。1年かけてコツコツと貯金し、ようやくバイクを購入(またもや金欠)。
前回はヒストグラムと箱ひげ図を利用して分布を可視化し、集団の特徴を見極めるというお話をしました。最後に、男女別や雇用形態別に勤め先収入のヒストグラムを作成する例を紹介しましたが、今回はいわばその続きです。具体的にはピボットテーブルを利用してクロス集計表を作成し、さらにヒートマップにより値の大きな箇所を可視化します。
前回見た性別や雇用形態の例では、各項目の内容はそれほど多くない(男性/女性、正規/非正規など)ので、1つのグラフの中に複数のヒストグラムを同時に描いてもそれほど見づらくはありませんでした。しかし、図1のような場合だとどうでしょう。このデータは1000種類のワインについて、価格と口コミの評価を一覧にしたものです(架空のデータです)。現実のデータ処理ではこの程度のデータ量は「ざら」にありますし、価格や評価など、項目の値が多くの階級に分けられることもあります。そのままヒストグラムを作っても図1に示したグラフのように、訳の分からないものになってしまいます。
 図1 項目の内容が細かく分かれる場合でも、関係や分布を可視化したい
図1 項目の内容が細かく分かれる場合でも、関係や分布を可視化したいワインの価格と評価の関係を可視化したいのだが、グラフ化する系列が多くなると、それらを同時に可視化することにはかなり無理がある。なお、データはセルA4〜A1003に1000件入力されている。評価の値はその商品の評価の平均値。
今回のテーマは、クロス集計表を利用した関係の可視化です。また、後半ではグループの可視化についても紹介します。……といっても、どのような分析を行うのかまだイメージが湧きませんよね。図1のグラフは見づらいので、以降は使いませんが、一部分だけ取り出してみると、以下のような値がグラフ化されていることが分かります。
- 2000円以上3000円未満のワインでは、3.5以上4.0未満の点数が付いた商品が一番多く、104種類ある
- 10000円以上11000円未満のワインでは4.5以上5.0以下の点数が付いた商品が一番多いが、8種類だけ (最大値が5.0なので最後の階級だけは「以下」となる)
今回は、図1に関連して述べた問題(見づらいグラフ)を解決し、箇条書きで示したような分析をもっと簡単にできるようにすることを目指します。そのための一つの方法として、ピボットテーブルを利用してクロス集計表を作成し、ヒートマップとして色分けして表す方法を見ていこうというわけです。それにより、分布や項目同士の関係を見やすくします。見やすい可視化ができれば、何か面白い発見があるかもしれません。
この記事は、データ分析の初歩から応用まで少しずつステップアップしながら学んでいく連載の第11回です。第7回の棒グラフ、第8回の折れ線グラフ、第9回の円グラフ/パレート図、第10回のヒストグラム/箱ひげ図、今回のクロス集計表、ヒートマップ、第12回の散布図まで、1つずつ可視化の基礎を学んでいきます。これらのグラフの目的と効用などについて、特別予告編で簡単に整理していますので、事前に確認しておくとより理解が深まるでしょう。可視化シリーズを続けて読んでグラフの使い分けをマスターしたい方は、次回を見逃さないために記事冒頭のボタンからメール通知に登録するのがお勧めです。
この記事で学べること
今回は以下のようなポイントについて、分析の方法や目の付けどころを見ていきます。
- ピボットテーブルを利用した多角的な分析 …… グループ化や計算の方法を指定し、クロス集計表を作成する
- ヒートマップを利用した可視化 …… 値の集中している箇所や異なるグループの可視化
では、ピボットテーブルを利用したクロス集計表の作成から見ていきましょう。続いて、条件付き書式を使ってヒートマップを作成します。サンプルファイルの利用についての説明の後、本編に進みましょう。
サンプルファイルの利用について
本稿では、表計算ソフトを使って手を動かしながら学んでいきます。表計算ソフトMicrosoft Excel用の.xlsxファイルをダウンロードできるようにしています。デスクトップ版のExcelが手元にない場合は、Microsoftアカウントがあれば使える無料のMicrosoft 365オンライン、もしくはGoogleアカウントがあれば使える無料のGoogleスプレッドシート(Google Sheets)をお使いください。Microsoft 365オンラインの場合は、.xlsxファイルをOneDriveにアップロードしてから開いてください。Googleスプレッドシートの場合は、.xlsxファイルをGoogleドライブにアップロードしてから開いた上で[ファイル]メニューの[Google スプレッドシートとして保存]を実行してください(Googleスプレッドシート独自の機能を使っている場合は、ファイルを共有して参照できるようにします。その場合は、該当する箇所で使い方を記します)。
ピボットテーブルを利用してクロス集計表を作る 〜 関係を可視化するためのデータを作成
クロス集計表とは、行と列に項目が並んでいて、その交わった位置に値がある表のことです。実は、前回のお話の中でも既にクロス集計表を作成しています。従って、図2のようなクロス集計表も簡単に作成できると思います。サンプルファイルをこちらからダウンロードし、[ワインの価格と評価]ワークシートを開いて取り組んでみてください。Googleスプレッドシートの場合はこちらのサンプルファイルを開いて、メニューから[ファイル]−[コピーを作成]を選択し、Googleドライブにコピーしてお使いください。
手順は図の後に箇条書きで示しておきます。ただし、タイトルや列幅など、データ分析そのものにあまり関係のない設定については省略してあります。なお、動画でも手順を解説しているので、操作を一つ一つ追いかけたい方はぜひご視聴下さい。
動画1 Excelでのクロス集計表とヒートマップの作り方
 図2 ワインの価格と評価のクロス集計表
図2 ワインの価格と評価のクロス集計表前回の知識だけでこの表は作成できる。価格だけでなく評価もグループ化して階級に分けてあることに注目。例えば、2000円未満のワインでは、評価が2.5以上3未満の商品が2つあり、3以上3.5未満の商品が13種類ある……といったように、表から値が読み取れる。図1の集合縦棒グラフや3D縦棒グラフはこのクロス集計表を基に作成したもの。
以下の手順で進めていきましょう。Googleスプレッドシートでの操作手順は後でまとめておきます(Microsoft 365オンラインでは、ピボットテーブルの作成はできますが、後述の[グループ化]ができないため、説明を割愛します)。
Excelでの操作手順
- セルA3〜D1003のいずれかのセルをクリックしておく
- [挿入]タブを開き、[ピボットテーブル]ボタンをクリックする([ピボットテーブルの作成]ダイアログボックスが表示される。ただし、Excelのバージョンによってはダイアログボックスの名前が[テーブルまたは範囲からのピボットテーブル]となっている)
- [テーブル/範囲]が「ワインの価格と評価!$A$3:$D$1003」になっていることを確認する
- [ピボットテーブルレポートを作成する場所を選択してください]の下の[既存のワークシート]をクリックしてオンにする
- [場所]ボックスをクリックし、セルF3をクリックして、[OK]ボタンをクリックする
これで、空のピボットテーブルと空のピボットグラフが作成されます。画面は図3のようになります。
 図3 空のピボットテーブルと空のピボットグラフが作成された
図3 空のピボットテーブルと空のピボットグラフが作成されたこの段階では、どの項目のどの値を集計し、グラフ化するかが指定されていないので、ピボットテーブルもピボットグラフも空の状態になっている。ここから、集計項目や集計の方法などを指定していく。
価格ごと、評価ごとにデータの件数を集計しましょう。
- [ピボットテーブルのフィールド]のリストにある[価格]を[行]の欄にドラッグする
- [ピボットテーブルのフィールド]のリストにある[評価]を[列]の欄にドラッグする
- [ピボットテーブルのフィールド]のリストにある[商品番号]を[Σ値]の欄にドラッグする
- [Σ値]の欄の「合計/商品番号」(Mac版の場合は[i]のアイコン)をクリックし、[値フィールドの設定]を選択する
- [選択したフィールドのデータ]リストから[個数]を選択し、[OK]をクリックする
この段階では、価格が細かく表示されており(F列)、評価も細かく表示されています(4行目)。表の中にはそれぞれの個数が表示されています。例えば、1200円で平均評価が3.0の商品が1つ、1500円で平均評価が3.4の商品は2つあるというわけです(図4)。
 図4 価格と評価のクロス集計表(作成途中)
図4 価格と評価のクロス集計表(作成途中)価格が縦方向(F列)に、評価が横方向(4行目)に並ぶようにして、それぞれの件数を集計する。[Σ値]に指定した項目は、そのままだと合計が求められる。商品の個数を求めたいので、個数を求めるように集計の方法を変えておく。
図4の行と列はあまりにも細かく分かれているので、価格と評価の関係がよく分かりません。そこで、価格は1000円ごとに、評価は0.5点ごとに区切ることにしましょう。かなり高額なワインも幾つかあるので、20000円より高い商品はひとまとめにします。
- セルF5〜F147のいずれかを右クリックして[グループ化]を選択する
- [グループ化]ダイアログボックスで[先頭の値]に「2000」を入力、[末尾の値]に「20000」を入力、[単位]に「1000」を入力する
- セルG4〜AI4のいずれかを右クリックして[グループ化]を選択する
- [グループ化]ダイアログボックスで[先頭の値]に「1」を入力、[末尾の値]に「5」を入力、[単位]に「0.5」を入力する
これで、価格と評価が階級に区切られ、その価格帯で、ある評価を得た商品の件数が求められます(図2で見たものです)。この段階まで操作を進めた結果は[ワインの価格と評価(ピボットテーブル)]ワークシートに作成してあります。
Googleスプレッドシートでの操作手順
- セルA3〜D1003のいずれかのセルをクリックしておく
- メニューバーから[挿入]−[ピボットテーブル]を選択する
- [ピボットテーブルの作成]ダイアログボックスの[データ範囲]が「ワインの価格と評価!A3:D1003」になっていることを確認する
- [挿入先]の下の[既存のワークシート]をクリックしてオンにする
- [データ範囲を選択]ボタン(田のマークのボタン)をクリックして、セルF3をクリックし、[OK]をクリックする
- [作成]ボタンをクリックする
これで、空のピボットテーブルが作成されます。画面の右側にピボットテーブルエディタが表示されるので、以下のように操作しましょう。
- 右側に表示されている項目一覧の[価格]を、左側の[行]の下にドラッグする
- 右側に表示されている項目一覧の[評価]を、左側の[列]の下にドラッグする
- 右側に表示されている項目一覧の[商品番号]を、左側の[値]の下にドラッグする
- [集計]ボックスから[COUNT]を選択する
価格と評価の両方に階級を設定しましょう。
- 作成されたピボットテーブルの[価格]の値(F列の値ならどれでもいい)を右クリックして[ピボットグループのルールを作成]を選択する
- [グループ化のルール]ダイアログボックスで、[最小値]に「2000」、[最大値]に「20000」、[間隔のサイズ]に「1000」を入力し、[OK]ボタンをクリックする
- 作成されたピボットテーブルの[評価]の値(4行目の値ならどれでもいい)を右クリックして[ピボットグループのルールを作成]を選択する
- [グループ化のルール]ダイアログボックスで、[最小値]に「1」、[最大値]に「5」、[間隔のサイズ]に「0.5」を入力し、[OK]ボタンをクリックする
これでクロス集計表が作成できました。
ヒートマップにより頻度を色分けする 〜 値の大小や関係を可視化
最初に示した図1の見づらいグラフは、前項で作成したピボットテーブルの値を棒グラフにしたものです。価格×評価という2次元の軸があり、頻度を高さで表しているので、かなり込み入った図になってしまったというわけです。そこで、ヒートマップを使い、頻度を高さではなく色で表すことにします。ここでは、頻度の多いセルを赤で、頻度の少ないセルを白で表示することにしましょう。ヒートマップはグラフの機能ではなく、条件付き書式で指定します。
- セルG5〜M23をドラッグして選択する(右端の[総計]列を含めないように注意しましょう)
- [ホーム]タブを開く
- [条件付き書式]−[カラー スケール]−[赤、白のカラー スケール]を選択する
Googleスプレッドシートでは以下のように操作します。
- セルG5〜M23をドラッグして選択する(右端の[総計]列を含めないように注意しましょう)
- メニューバーから[表示形式]−[条件付き書式]を選択し、右側に表示される[条件付き書式設定ルール]作業ウインドウで[カラースケール]をクリックする
- [プレビュー]の色が表示されている部分をクリックして、[白→赤]を選択する
- [完了]ボタンをクリックする
- [条件付き書式設定ルール]作業ウインドウの右上の[×]をクリックして、作業ウィンドウを閉じておく
条件付き書式を指定するとピボットテーブルは以下のようになります(図5)。
 図5 ヒートマップの作成例
図5 ヒートマップの作成例どのセルの値が大きいかが一目で分かる。濃い赤のセルが頻度の大きなセル。ヒートマップは、いわば図1の3Dグラフを上から覗き込んで、高い棒と低い棒を色分けしたようなものとも考えられる。この例は[ワインの価格と評価(ヒートマップ)]ワークシートに作成してある。
図9のヒートマップを見ると、以下のようなことが一目で見て取れます。
- 全体的に価格の高いワインは、評価の高い商品が多い
- 2000円以上4000円未満のワインで、3.5以上4.5未満の点数が付いた商品が多い
つまり、満足度の高いワインが欲しければある程度の予算が必要だということと、(口コミの数は売り上げを反映していると考えられるので)どの価格帯の商品が入手しやすく、その評価はどれぐらいかということが分かります。また、以下のようなことも言えそうです。
- 安いワインでも低評価はそれほど多くない
- 5000円以上10000円未満のワインには評価の低いものが若干ある
- 20000円以上のワインは評価が高い
最初のは「安いワインだからまあこんなもんだろう(値段の割にはいい)」、次は「そこそこの値段だったのに、期待したほどではなかった」という評価の商品があったのかもしれません。最後は、実際に出来の良いワインで、それだけの商品を購入する人はやはり舌が肥えているということでしょうか。意地悪な見方をすれば「高いワインだから、きっといいものだろう」と無意識のうちに考える心理的な要因も考えられなくもないですが。

カラースケールには赤、黄、緑など、もっと派手なものもありますが、1型2色覚(P)の人や2型2色覚(D)の人にとっては赤と緑の区別が付きづらいので、図5のような配色が望ましいでしょう。どうしても見づらい配色にせざるを得ない場合には、値やラベルなどを表示して区別できるようにしておきましょう(この例では、値が表示されてはいますが、色分けに重きを置いているので赤と白の配色にしてあります)。筆者は「色のシミュレータ」(iPad/iPhone用はこちら、Android用はこちら)というアプリを使って、見づらい配色がないかチェックしています。
ピボットテーブルの計算方法を変える 〜 値ではなく割合を可視化する
ところで、図5のピボットテーブル/ヒートマップを見て、疑問に思う点はないでしょうか。例えば、2000円以上3000円未満のワインで、3.5以上4.0未満の点数が付いた商品は104種類あります(図6の上、○で囲んだ箇所)。一方、20000円より高いワインでは、4.5以上5.0以下の点数が付いた商品が39種類あります(図6の右下、○で囲んだ箇所)。
 図6 単純に値を色分けしただけだと割合の大きさが分からない
図6 単純に値を色分けしただけだと割合の大きさが分からない104の方が39よりも濃く表示されているので、その部分のワインが多いことが分かるが、評価を問題にするのであれば、高額なワインが高評価であることが分かりづらい。
確かに数の上では104の方が多いので、2000円以上3000円未満で3.5以上4.0未満程度のワインが多く、入手しやすいということは分かります。しかし、評価の良さはこのままでは比較できません。2000円以上3000円未満のワインは全部で233種類あるので、104というのは全体の44.6%です。20000円より高いワインは61種類あるので、そのうちの39種類は全体の63.9%です。高価なワインの方が断然高評価なのに、ヒートマップによる色分けではそれほど目立っていませんね。
そこで、ピボットテーブルの集計方法として、単にデータの件数を求めるのではなく、同じ価格帯の商品全体に占める件数の割合を求めるように変更してみましょう。そのためには、行の総計に対する各セルの割合を求めた表を別に作って……と、面倒な操作が必要になりそうだと思われるかもしれません。しかし、ピボットテーブルではそのような計算も簡単にできます。
- [Σ値]の欄の「合計/商品番号」(Mac版の場合は[i]のアイコン)をクリックし、[値フィールドの設定]を選択する
- [値フィールドの設定]ダイアログボックスで[計算の種類]タブをクリックする
- [計算の種類]リストから[行集計に対する割合]を選択し、[OK]をクリックする
- Googleスプレッドシートでは、[ピボットテーブルエディタ]作業ウィンドウの左側、[値]の下に表示されている[商品番号]の[表示方法]リストから[行集計に対する割合]を選択する
設定ができると、ピボットテーブル/ヒートマップは図7のようになります。
 図7 割合に注目したピボットテーブル/ヒートマップを作成する
図7 割合に注目したピボットテーブル/ヒートマップを作成する高額なワインはデータの件数(口コミの数)が少ないので、正確さにはやや欠けるが、値段が高くなるほど評価の高い商品が多くなっていることがより鮮明に分かる。この例は[ワインの価格と評価(比率のヒートマップ)]ワークシートに作成してある。
ヒートマップを作成したときに、大きな値(あるいは小さな値)の集まっている箇所に偏りがあることが分かれば、項目同士に何らかの関係があることが分かります。図7の例であれば、右下の値がやや大きいので、価格が高くなるほど、評価も高くなることが分かります。逆に、右上に大きな値が集まっているのなら、価格が安いほど評価が高いことになります。右側のどの行にも同じぐらい大きな値が集まっていれば、価格に関係なく比較的高評価だということになりますね。このように、大きな値がどのあたりに集まっているかによって項目同士の関係も見えてくるというわけです。
ヒートマップでクラスターを可視化する 〜 グループ分けを見やすくする
ヒートマップは項目同士の関係を可視化するだけでなく、集団が幾つかのクラスター(グループ)から成り立っていることを可視化するのにも使えます。データをその値によって「似たもの同士」を集め、幾つかのグループに分けるにはクラスタリングと呼ばれる機械学習の手法が使われます。ここでは、クラスタリングによりグループ分けされた結果をヒートマップとして表示する例を紹介しておきます。
とはいうものの、残念ながらExcelにはクラスタリングの機能がありません。そのため、クラスタリングは既に行われたものとして、その結果のデータを使うことにします。図8は、k-means法と呼ばれる方法で年齢とインターネットの利用時間を元にクラスタリングを行った結果です(データは架空のものです。また、プログラムは後でまとめて掲載します)。
k-means法については、「[AI・機械学習の数学]総和を表すΣは機械学習に必須の記号」の5ページ目で基本的な考え方を紹介しています。なお、実際にk-means法でクラスタリングを行うPythonのプログラムをこの記事の最後のコラムで参考として掲載しておきます。

このデータを基にピボットテーブル/ヒートマップを作成してみましょう。ここでは、グループと年齢ごとにインターネット利用時間の平均を求めてくたさい。サンプルファイルはこちらからダウンロードできます。Googleスプレッドシートの場合はこちらのサンプルファイルを開いて、メニューから[ファイル]−[コピーを作成]を選択し、Googleドライブにコピーしてお使いください。なお、Microsoft 365オンラインでは、ピボットテーブルの作成はできますが、[グループ化]ができないため、説明を割愛します。
では、[クラスタリング]ワークシートを開いて取り組んでみてください。手順は図9の後に箇条書きで示しておきますが、既に見た手順とほぼ同じなので、まずは独力でチャレンジしてみましょう。
 図9 クラスタリングの結果を基にピボットテーブル/ヒートマップを作成する
図9 クラスタリングの結果を基にピボットテーブル/ヒートマップを作成するピボットテーブルを作成し、条件付き書式を使って色分けしてみた。6つのグループごと、年齢ごとにインターネットの利用時間が可視化できる。それぞれのグループがどのような特徴を持つのかを見つけるのに役立つ。完成例は[時間を集計]ワークシートに作成されている。
手順は以下の通りです。これについても、Googleスプレッドシートでの操作は後でまとめておきます。
Excelでの操作手順
- セルA1〜E161のいずれかのセルをクリックしておく
- [挿入]タブを開き、[ピボットテーブル]ボタンをクリックする([ピボットテーブルの作成]ダイアログボックスが表示される。ただし、Excelのバージョンによってはダイアログボックスの名前が[テーブルまたは範囲からのピボットテーブル]となっている)
- [テーブル/範囲]が「クラスタリング!$A$1:$E$161」になっていることを確認する
- [ピボットテーブルレポートを作成する場所を選択してください]の下の[既存のワークシート]をクリックしてオンにする
- [場所]ボックスをクリックし、セルG1をクリックする
- [OK]ボタンをクリックする
これで空のピボットテーブルができるので、以下のように進めます。
- [ピボットテーブルのフィールド]のリストにある[Group]を[行]の欄にドラッグする
- [ピボットテーブルのフィールド]のリストにある[Age]を[列]の欄にドラッグする
- [ピボットテーブルのフィールド]のリストにある[Minutes]を[Σ値]の欄にドラッグする
- [Σ値]の欄の「合計/Minutes」(Mac版の場合は[i]のアイコン)をクリックし、[値フィールドの設定]を選択する
- [選択したフィールドのデータ]リストから[平均]を選択し、[OK]をクリックする
続いて、年齢(Age)を10歳ごとの階級に分けます。
- セルH2〜BS2のいずれかを右クリックして[グループ化]を選択する
- [グループ化]ダイアログボックスで[先頭の値]に「10」を入力、[末尾の値]に「100」を入力、[単位]に「10」を入力する
これで、ピボットテーブルの完成です。求められた平均値は小数点以下の桁数が多くなるので、[ホーム]タブの[数値]グループにある[小数点以下の表示桁数を減らす]ボタンなどを利用して、見やすくしておくといいでしょう。
ヒートマップの作成は簡単ですね。
- セルH3〜P8をドラッグして選択する
- [ホーム]タブを開く
- [条件付き書式]−[カラー スケール]−[赤、白のカラー スケール]を選択する
Googleスプレッドシートでの操作手順
- セルA1〜E161のいずれかのセルをクリックしておく
- メニューバーから[挿入]−[ピボットテーブル]を選択する
- [ピボットテーブルの作成]ダイアログボックスの[データ範囲]が「クラスタリング!A1:E161」になっていることを確認する
- [挿入先]の下の[既存のワークシート]をクリックしてオンにする
- [データ範囲を選択]ボタン(田のマークのボタン)をクリックして、セルG1をクリックし、[OK]をクリックする
- [作成]ボタンをクリックする
これで、空のピボットテーブルが作成されます。続けましょう。
- 右側に表示されている項目一覧の[Group]を、左側の[行]の下にドラッグする
- 右側に表示されている項目一覧の[Age]を、左側の[列]の下にドラッグする
- 右側に表示されている項目一覧の[Minutes]を、左側の[値]の下にドラッグする
- [集計]ボックスから[AVERAGE]を選択する
年齢(Age)に10歳ごとの階級を設定しましょう。
- 作成されたピボットテーブルの[Age]の値(2行目の値ならどれでもいい)を右クリックして[ピボットグループのルールを作成]を選択する
[グループ化のルール]ダイアログボックスで、[最小値]に「10」、[最大値]に「100」、[間隔のサイズ]に「10」を入力し、[OK]ボタンをクリックする
これでクロス集計表が作成できました。ヒートマップの作成は簡単ですね。
- セルH3〜P8をドラッグして選択する
- メニューバーから[表示形式]−[条件付き書式]を選択し、右側に表示される[条件付き書式設定ルール]作業ウインドウで[カラースケール]をクリックする
- [プレビュー]の色が表示されている部分をクリックして、[白→赤]を選択する
- [完了]ボタンをクリックする
- [条件付き書式設定ルール]作業ウインドウの右上の[×]をクリックして、作業ウィンドウを閉じておく
条件付き書式を設定すると、上で見た図9のような表になります。ただし、クラスタリングによって分けられたグループがどのような特徴を持つものなのかを吟味するのは人間の役割です。0番のクラスターは高齢者のグループで、インターネットの利用時間が短めです。1番のクラスターには若年層の人が集中しています。2番はもう少し年齢が高めです。働き盛りのグループでしょうか。3番のクラスターは1番や2番と似ていますが、インターネットの利用時間がかなり長いアクティブユーザーのようです。4番と5番は年齢的には中高年といったところですが、5番の方がインターネットの利用時間が短めですね。というわけで、グループに名前を付けるのは人間がやるべきことですが、ヒートマップを利用すると、グループのまとまりや、グループ間の違いが可視化できるというわけです。
1〜3番のクラスターは年齢構成が似ているように思われますが、どの年代の人が多いかは図9からは分かりません。それを知るためには、各グループを構成する人の人数を集計する必要があります。サンプルファイルには人数を集計した結果([人数を集計]ワークシート)も含めてあります。それを見ると、2番は40歳代の人が多く、3番は10歳代の人が多いことが分かります。なお、年齢とインターネットの利用時間を基に、クラスターごと色分けした散布図を作成すれば、もう少し詳しいことが分かりそうです……が、それについては、次回のお話とします。
コラム k-means法によるクラスタリングのプログラム
図8のようにクラスタリングを行い、グループ分けを行うプログラムは以下に掲載しておきます。このリンクをクリックすれば、ブラウザが起動し、Google Colaboratoryで以下のコードが表示されます(Googleアカウントでのログインが必要です)。[ドライブにコピー]ボタンをクリックすれば、自分のGoogleドライブにコピーできます。コードの部分をクリックして[Shift]+[Enter]キーを押せば、プログラムが実行され、クラスタリングを行った結果がExcelのファイルとして作成されます。コードの詳細についてはこの記事の範囲を大きく逸脱するので割愛しますが、コード中のコメントと説明を参照していただければだいたいの意味は分かると思います。
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# データの読み込み
df = pd.read_excel("https://github.com/Gessys/data_analysis/raw/main/11b.xlsx", sheet_name="年齢と利用時間")
data = df.loc[:, "Age":"Minutes"] # 年齢と時間だけを取り出す
# データを標準化する(年齢と時間では値の大きさが異なるので)
sc = StandardScaler()
data_sc = sc.fit_transform(data)
# k-means法によるクラスタリング
model = KMeans(n_clusters=6, random_state=0, n_init="auto") # 6グループに分ける
model.fit(data_sc)
# 元のデータにクラスター番号を追加する
cluster_no = pd.DataFrame(model.labels_, columns=["Group"])
dfresult = pd.concat([df, cluster_no], axis=1)
# Excelファイルに書き出す
dfresult.to_excel("11b_add.xlsx", index=False)
sklearn.clusterモジュールのKMeans関数によりk-means法のモデルを用意し、標準化したデータdata_scに当てはめる。クラスタリングされた結果はmodel.labels_で取得できるので、元のデータdfと取得したクラスター番号をつないでExcelのファイルに書き出す。
作成されたExcelファイルは以下の手順でダウンロードできます。
- Google Colaboratoryの左側の領域に表示されているファイル一覧の中にある「11b_add.xlsx」の右側にマウスポインタを合わせる
- ファイル一覧が表示されていない場合は、画面の左端にあるフォルダの形のアイコンをクリックする
- 3つの点が縦に表示されたアイコンをクリックし、[ダウンロード]を選択する
図8のサンプルファイル(11b.xlsx)は、元のファイルと11b_add.xlsxファイルをひとまとめにして、書式などを設定したものです。もちろん、データをExcelに移さず、ピボットテーブルの作成からヒートマップの作成までをPythonで実行することもできます。コードは以下の通りです。リスト1のコードに続けて実行すれば、ピボットテーブル(クロス集計表)とヒートマップが作成されます。
# 年齢の階級を作る
bins = range(10, 100, 10)
dfresult["AgeClass"] = pd.cut(dfresult["Age"], bins, right=False)
# クロス集計表を作る
from pandas.core.groupby import grouper
cross_table = pd.pivot_table(dfresult, values="Minutes", index="Group", columns="AgeClass", aggfunc="mean", fill_value=0)
cross_table
pandasモジュールのcut関数により、クラスタリングされた結果(dfresult)の年齢を10以上101未満まで10刻みの階級に分けた列を作る。引数right=Falseを指定すると階級が「〜以上〜未満」となり、Excelの結果と同じになる。引数rightを指定しないと階級は「〜より大〜以下」となる。クロス集計表はpandasモジュールのpivot_table関数やcrosstab関数で作成できる。ここではpivot_table関数を使った。引数valuesに集計する項目を指定し、引数indexには行の見出しを、引数columnsには列の見出しを指定する。引数aggfuncには集計の方法を指定。ここでは平均を表す"mean"を指定した。引数fill_valueは、値が存在しないとき(NaNのとき)に代わりに出力する値を指定する。
# ヒートマップを作成する
import seaborn as sns
sns.heatmap(cross_table, annot=True, fmt=".1f", cmap="Reds")
ヒートマップはseabornモジュールのheatmap関数にクロス集計表を指定するだけでできる。引数annotは値を表示するかどうかの指定、fmtは値の書式。ここでは、小数点以下1桁まで表示するようにした。引数cmapは配色の指定。
実行結果は以下のようになります(図10)。
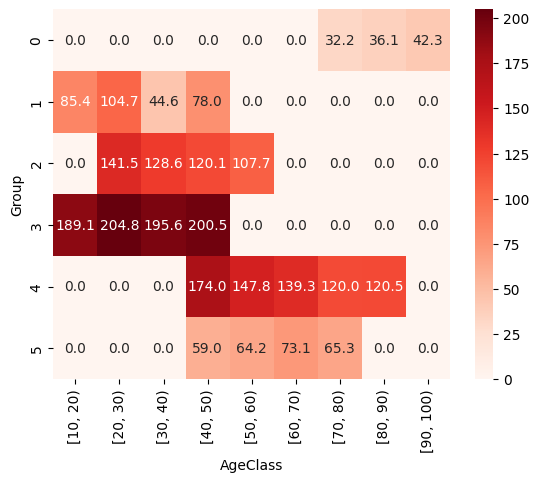 図10 クラスタリングの結果を基にピボットテーブル/ヒートマップを作成する
図10 クラスタリングの結果を基にピボットテーブル/ヒートマップを作成するExcelで作成したヒートマップと同様の結果になる。画像を右クリックして[名前を付けて保存]を選択すれば、ヒートマップをPNGファイルとして保存できる。
今回は、ピボットテーブルを利用してクロス集計表を作成し、ヒートマップを作成しました。ヒートマップでは、値の大小を色分けすることにより、項目同士の関係を可視化したり、集団を幾つかのグループに分けるヒントを得ることができます。
次回も「関係」に注目し、散布図を作成することとします。関係の可視化だけでなく、外れ値の可視化や、値の飽和(サチュレーション=測定限界を超えた値が数多く存在すること)などの検出もできます。また、多くの項目同士の関係を見るため、複数の散布図をまとめて表示したり、グループごとに色分けして散布図を表示したりする方法も併せて紹介します。次回もどうぞお楽しみに!
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。