[データ分析]ヒストグラムや箱ひげ図で「分布」を可視化 〜 集団の特徴や外れ値を見つける:やさしいデータ分析
データ分析を初歩から学ぶ連載の第10回。グラフを使って集団の特徴や外れ値を可視化します。ヒストグラムや箱ひげ図の作成方法と、ピボットテーブル/ピボットグラフによる視覚的な分析のコツを、ケーススタディを通して学びましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
連載:

この連載では、データをさまざまな角度から分析し、その背後にある有益な情報を取り出す方法を学びます。
データの収集方法、データの取り扱い、分析の手法などについての考え方を具体例で説明するとともに、身近に使える表計算ソフト(ExcelやGoogleスプレッドシート)を利用した作成例を紹介します。
必要に応じて、Pythonのプログラムや統計ソフトRなどでの作成例にも触れることにします。
数学などの前提知識は特に問いません。肩の力を抜いてぜひとも気楽に読み進めてください。
 羽山博
羽山博筆者紹介: IT系ライターの傍ら、非常勤講師として東大で情報・プログラミング関連の授業を、一橋大でAI関連の授業を担当。書道、絵画を経て、ピアノとバイオリンを独学で始めるも学習曲線は常に平坦。趣味の献血は、最近脈拍が多く99回で一旦中断。さらにリターンライダーを目指し、大型二輪免許を取得。1年かけてコツコツと貯金し、ようやくバイクを購入(またもや金欠)。
いきなりですが、読者のみなさんは「分析」という言葉の意味をじっくりと考えてみたことはあるでしょうか。「分」は、分けるということですね(刀で左右に切り離す)。「析」はちょっと難しいですが、細かく分けるという意味です(斤=「おの」で木を切る)。つまり、分析とは大きく分けたり、細かく分けたりすること……なのですが、そのためには全体像を見て、どのように分けるかを決める必要があります。というわけで、今回は可視化により全体像を見ることと、全体が何らかの特徴によってどう切り分けられるかを見ることに焦点を当てます。
具体的には、ヒストグラムと箱ひげ図を利用します。ヒストグラムは、集団の代表値を求めるお話(この連載の第3回)の中で紹介しました。また、箱ひげ図については散布度を求めるお話(この連載の第5回)の中で紹介しました。いずれも、どのようなグラフなのかをお見せしただけで、作成手順については触れていませんでした。そこで、今回はそれらのグラフの具体的な作成手順や書式の設定方法、より詳細な分析方法を見ていくことにします。
ところで、ヒストグラムや箱ひげ図を作成すると、図1のような、いびつなグラフが作られることもよくあります。データは架空のものですが、勤労者世帯の勤め先収入の平均値(月49.2万円)と一致するように作成してあります。平均値の出典は、総務省統計局の家計調査の統計表(Excelファイル)に掲載された2022年の値です。
 図1 全体像を可視化して「切り分ける」ポイントを知る
図1 全体像を可視化して「切り分ける」ポイントを知る数値だけでは分からない特徴を可視化するために、ヒストグラムや箱ひげ図を作成し、まずは分布を見てみよう。この例のように整ったグラフにならないことも多いが、そういう場合こそ、切り分けるポイントが分かりやすい。値が集中している箇所と離れている箇所を大きく分けたり、値が集中している箇所を細かく分けて調べていくとよい。
統計学の教科書で紹介されているヒストグラムは、真ん中あたりに山があって、左右に裾が広がっている「整った」形のグラフが多いようです。ヒストグラムがどのようなものかを理解するにはいいのですが、実際には図1に示したような、いびつな形のヒストグラムになることがよくあります。しかし、整った形のグラフにはそれ以上の特徴があまりありません。むしろ、いびつな形のグラフからの方が、興味深い特徴を見つけやすいものです。
今回は集団の特徴を可視化するというテーマについて、幾つかの例を見ていきます。つまり、図1のグラフをどう切り分けて特徴を見つけていくかということです。また、データを多角的に分析するには、ピボットテーブル/ピボットグラフも便利です。ピボットテーブル/ピボットグラフに苦手意識を持つ人も多いようですが、分かりやすく説明していきます。
この記事は、データ分析の初歩から応用まで少しずつステップアップしながら学んでいく連載の第10回です。第7回の棒グラフ、第8回の折れ線グラフ、第9回の円グラフ/パレート図から、今回のヒストグラム、箱ひげ図、第11回のクロス集計表、ヒートマップ、第12回の散布図まで、1つずつ可視化の基礎を学んでいきます。これらのグラフの目的と効用などについて、特別予告編で簡単に整理していますので、事前に確認しておくとより理解が深まるでしょう。可視化シリーズを続けて読んでグラフの使い分けをマスターしたい方は、次回を見逃さないために記事冒頭のボタンからメール通知に登録するのがお勧めです。
この記事で学べること
今回は以下のようなポイントについて、分析の方法や目の付け所を見ていきます。
- ヒストグラムの作成と適切な設定 …… 全体的な特徴と部分の特徴を見る
- 箱ひげ図の作成と適切な設定 …… 外れ値を見つける
- ピボットテーブル/ピボットグラフを利用した多角的な分析 …… 属性別にヒストグラムを作成、比較する
では、ヒストグラムの作成から見ていきましょう。まず、特に何も指定せずに図1のようなヒストグラムを作り、書式の設定を変えながら何が読み取れるかを見ていきます。では、サンプルファイルの利用についての説明の後、本編に進みましょう。
サンプルファイルの利用について
本稿では、表計算ソフトを使って手を動かしながら学んでいきます。表計算ソフトMicrosoft Excel用の.xlsxファイルをダウンロードできるようにしています。デスクトップ版のExcelが手元にない場合は、Microsoftアカウントがあれば使える無料のMicrosoft 365オンライン、もしくはGoogleアカウントがあれば使える無料のGoogleスプレッドシート(Google Sheets)をお使いください。Microsoft 365オンラインの場合は、.xlsxファイルをOneDriveにアップロードしてから開いてください。Googleスプレッドシートの場合は、.xlsxファイルをGoogleドライブにアップロードしてから開いた上で[ファイル]メニューの[Google スプレッドシートとして保存]を実行してください(Googleスプレッドシート独自の機能を使っている場合は、ファイルを共有して参照できるようにします。その場合は、該当する箇所で使い方を記します)。
ヒストグラムから特徴を読み取る 〜 いびつなグラフこそ情報の宝庫
最初に見た勤め先収入のデータはサンプルファイル(後述)のセルB4〜B103までに入力されています。セルB3の項目見出しを含めて、ヒストグラムを作成し、設定を変更してみましょう。図2の左側が特に何も指定せずにヒストグラムを作った例で、右側が書式を変更して適切な形式にしたものです。サンプルファイルをこちらからダウンロードし、[勤め先収入1]ワークシートを開いて取り組んでみてください。Googleスプレッドシートの場合はこちらのサンプルファイルを開いて、メニューから[ファイル]−[コピーを作成]を選択し、Googleドライブにコピーしてお使いください。
手順は図の後に箇条書きで示しておきます。ただし、タイトルなど、データ分析そのものにあまり関係のない設定については省略してあります。なお、動画でも手順を解説しているので、操作を一つ一つ追いかけたい方はぜひご視聴ください。
動画1 Excelでのヒストグラムの作り方
 図2 勤め先収入のヒストグラム(取りあえず作成したものと書式を設定したもの)
図2 勤め先収入のヒストグラム(取りあえず作成したものと書式を設定したもの)上側のグラフは特に何も指定せずに作成したヒストグラム。値が集中している左端の部分を詳しく表示し、それ以外の値が離れている部分をまとめたものが下側のグラフ。
手順は以下の通りです。
- セルB3〜セルB103をドラッグして選択する
- [挿入]タブを開き、[統計グラフの挿入]−[ヒストグラム]を選択する
- Googleスプレッドシートの場合は、メニューバーから[挿入]−[グラフ]を選択し、[グラフの種類]のリストから[ヒストグラム グラフ]を選択する
これで上側のグラフが作成できます。左端の棒は、収入が7.3万円より大きく、127.3万円以下である人数を表しますが、かなり幅が広いですね。これではほとんどの人がこの範囲に入ってしまいます。そこで、階級の幅を5万円にして、その部分を詳しく見られるようにしましょう。また、収入が127.3万円より大きい人の数は少ないので、その部分をまとめてしまいましょう。操作を続けます。
- 横軸を右クリックし、[軸の書式設定]を選択する
- [ビンの幅]に5と入力する(階級の幅が5万円になる)
- [ビンのオーバーフロー]のチェックマークをオンにし、「100」と入力する(100万円より大きな階級がまとめられる)
- [ビンのアンダーフロー]のチェックマークをオンにし、「10」と入力する(10万円以下の階級がまとめられ、キリのいい目盛りになる)
Googleスプレッドシートの場合は、以下のように操作します
- グラフを右クリックし[軸]-[横軸]を選択し、[グラフエディタ]を表示する
- [カスタマイズ]タブをクリックする
- [最小値]に「10」を入力する
- [最大値]に「100」を入力する
いかがでしょう。下側のグラフを見ると、全体的に山が左に寄っていますね。つまり、大半の人がこの山の中にいて、収入のかなり大きな人が少数いるということが分かります。特に、収入が30万円より大きく35万円以下の階級の人数が多いようですが、10万円より大きく15万円以下の階級にも小さな山があるようです。このことから、勤労者世帯が、少数の高収入の層、多数の人が属する30万円程度の層、一定数の低収入の層に分かれることが示唆されます。
なお、Googleスプレッドシートでは、最小値以下の階級がまとめられたり、最大値より大きな階級がまとめられるのではなく、単に最小値以下や最大値より大きな階級が表示されなくなるだけです。また、階級の幅も自動的に決められるので、このままでは、上で説明したような3つの階層に分かれるという示唆は得られません(ただし、最大値を「55」に設定して、より詳細に表示すると、図2の下側と同じようなグラフになります)。

図2から、勤め先収入の最頻値は、最も度数の大きな階級の下限と上限の平均、つまり、(35+30)÷2=32.5(万円)であることが分かります。また、空いているセルに「=AVERAGE(B4:B103)」と入力すると、平均値が49.2(万円)であることが分かり、「=MEDIAN(B4:B103)」と入力すると、中央値が31.4(万円)であることも分かります。平均値が大きくなっているのは、分布に偏りがあり、少数の大きな値に引きずられているからですね。
箱ひげ図により四分位範囲を可視化する 〜 大半のデータがどの範囲にあるかを知る
勤め先収入が3つの階層に分かれるのではないかということについて、さらに掘り下げていきたいところですが(後で見るのでお楽しみに!)、その前に、箱ひげ図の作成に取り組んでおきましょう。箱ひげ図を作成すると四分位範囲が可視化できます。つまり、順位を基にして、全体の25%〜75%(中央部分に位置する半数)が属する範囲が分かります。また、大きく離れた値(外れ値)も可視化できます。
では、上で見たファイルの[勤め先収入2]ワークシートを開いて、図3のように箱ひげ図を作成し、設定を変更してみましょう。データは[勤め先収入1]ワークシートと全く同じです。グラフを作成しやすいように別のワークシートにしてあるだけです。残念ながら、Googleスプレッドシートには今のところ箱ひげ図の機能がないので、サンプルファイルには含めていません。
手順は図の後に箇条書きで示しておきます。なお、動画でも手順を解説しているので、操作を一つ一つ追いかけたい方はぜひご視聴ください。
動画2 Excelでの箱ひげ図の作り方
 図3 勤め先収入の箱ひげ図(取りあえず作成したものと書式を設定したもの)
図3 勤め先収入の箱ひげ図(取りあえず作成したものと書式を設定したもの)上側のグラフは特に何も指定せずに作成した箱ひげ図。値が集中している下の部分を詳しく表示するために、小さな●で示された外れ値を除外したものが下側のグラフ。下側のグラフの中央の四角い部分が四分位範囲。四分位範囲の中央にある横線が中央値。上の×が平均値。「ひげ」の上限(上の横線の位置)は第3四分位数+1.5×四分位範囲の値以下の最も近い値となり、下限(下の横線の位置)は第1四分位数−1.5×四分位範囲以上の最も近い値となる。ひげの外側が外れ値となる。
手順は以下の通りです。
- セルB3〜セルB103をドラッグして選択する
- [挿入]タブを開き、[統計グラフの挿入]−[箱ひげ図]を選択する
これで上側のグラフが作成できます。外れ値が幾つかあることはよく分かりますが、値が集中している部分は下の方にわずかに表示されているだけです。外れ値(Excelでは特殊ポイントと呼ばれます)を表示しないようにしてみましょう。
- データ系列(グラフの箱やひげの部分)を右クリックし、[データ系列の書式設定]を選択する
- [データ系列の書式設定]作業ウィンドウの[系列のオプション]ボタンをクリックする
- [特異ポイント]をクリックしてチェックマークをオフにする
図3の下側のグラフになり、四分位範囲がよく分かるようになりました。20万円〜40万円あたりですね。この四分位範囲はQUARTILE.EXC関数で求められる値を基に描かれています。QUARTILE.INC関数で求められる値を基にしたい場合には、上で見た[データ系列の書式設定]作業ウィンドウで[四分位数計算]の[包括的な中央値]をクリックして、設定をオンにします。
空いているセルに「=QUARTILE.EXC(B4:B103,1)」と入力すれば、第1四分位数が23.05であることが分かります。また、「=QUARTILE.EXC(B4:B103,3)」と入力すれば、第3四分位数が39.08であることが分かります。
なお、外れ値として表示されている小さな●にマウスポインタを位置付けると、その値がポップアップ表示されます。図3の左の例では、上から順に1600、200、124、68.7の4つが外れ値と見なされています。外れ値の検出には、この連載の第4回で紹介したスミルノフ・グラブス検定なども使えます。
コラム バイオリン図では値が集中している箇所も分かる
箱ひげ図の四分位範囲は四角で表されているので、ヒストグラムのような「山」が表せません。そこで、度数を反映したような表示にできるバイオリン図(バイオリンプロット)が使われることもあります。残念ながらExcelやGoogleスプレッドシートにはバイオリン図の機能がないので、PythonやRなどを使う必要があります。
以下の例は、PythonからExcelのデータを読み込み、バイオリン図を作成したものです。このリンクをクリックすれば、ブラウザが起動し、Google Colaboratoryで以下のコードが表示されます(Googleアカウントでのログインが必要です)。[ドライブにコピー]ボタンをクリックすれば、自分のGoogleドライブにコピーできます。コード(リスト1)の部分をクリックして[Shift]+[Enter]キーを押せばグラフ(図4)が描画されます。ぜひ試してみてください。
import pandas as pd
import matplotlib.pyplot as plt
# データの読み込み
df = pd.read_excel("https://github.com/Gessys/data_analysis/raw/main/10a.xlsx",
sheet_name="勤め先収入1", usecols="A:B", skiprows=2,
index_col="サンプル")
# バイオリン図の作成
graph = plt.violinplot(df.loc[:, "勤め先収入(万円)"],
showmedians=True, showmeans=True, quantiles=[0.25, 0.75])
graph['cquantiles'].set(color="C1") # 四分位範囲をオレンジ色で表示する
graph['cmedians'].set(color="C2", linewidth=0.5, linestyle="dotted") #中央値を緑色で表示する
graph['cmeans'].set(color="C3", linewidth=0.5, linestyle="dotted") # 平均値を赤色で表示する
plt.ylim([0, 200])
plt.xticks(ticks=[1],labels=["income"])
plt.show()
詳細については割愛するが、pandasモジュールのread_excel関数でExcelのデータを読み込み、matplotlib.pyplotモジュールのviolinplot関数にデータや中央値の表示(showmedians)、平均値の表示(shoemeans)、四分位範囲の表示(quantiles)などの引数を指定して描画を行う。
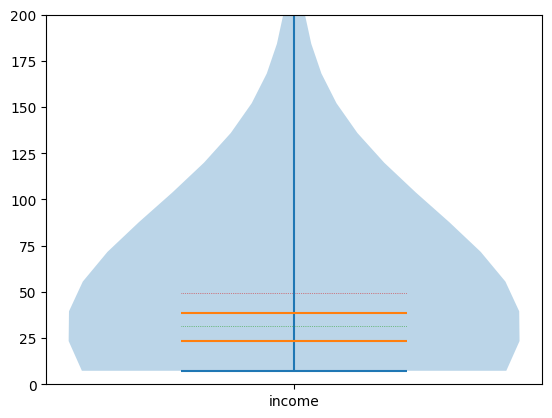 図4 バイオリン図の例
図4 バイオリン図の例四分位範囲がオレンジの実線で、中央値が緑の点線で表示されている。赤の点線で表示されている平均値が四分位範囲の外にあることも分かる。最小値は青の実線で表示されているが、y軸の範囲を限定したので最大値は表示されていない。どのあたりの度数が大きいかも分かるのがバイオリン図のメリット。
ピボットテーブル/ピボットグラフを活用する 〜 属性別にヒストグラムを作る
実は、勤め先収入のデータは、性別や雇用形態が全て「込み」になっています。答えから先に言うと、中央値よりも左の階級に小さな山があるのは、性別や雇用形態による収入の格差が原因です。性別や雇用形態を含めたデータは図5のようなものになっています。
 図5 勤め先収入のデータ(性別・雇用形態別)
図5 勤め先収入のデータ(性別・雇用形態別)データはセルB3〜D103に入力されており、3行目は項目の見出しになっている。性別はFが女性、Mが男性を表す。雇用形態はRが正規職員、Nが非正規職員を表す。性別と雇用形態で勤め先収入の分布がどう違うかを知りたいのだが、単純にヒストグラムを作るのはちょっと面倒。そこで、ピボットテーブル/ピボットグラフを使う。
この例では、明らかに性別や雇用形態といった属性が分かるようになっていますが、現実には、隠された要因によるものであることもよくあります。ともあれ、性別と雇用形態別にヒストグラムを作成し、それらを比較してみましょう。
これまでの方法で、男性だけのヒストグラム、女性だけのヒストグラム……のようにグラフを作成してもいいのですが、かなり面倒ですね。そこで、ピボットテーブル/ピボットグラフを使いましょう。ピボットグラフを使えば直接グラフが作成できます。
手順は以下の通りです。ステップごとに図を示しておくので、操作が細かくなるので、丁寧に進めてください(といっても、いくらでもやり直しはできます)。動画でも手順を解説しているので、手順を確認しながら進めるのが苦手な方や、ステップごとに操作を追いかけたい方は、ぜひ動画をご視聴ください。
動画3 Excelでのピボットテーブル/ピボットグラフの使い方
では、手順です。サンプルファイルをこちらからダウンロードし、[勤め先収入3]ワークシートを開いて取り組んでみてください。Googleスプレッドシートではピボットテーブルの作成とグラフ作成の機能が別になっているので、Excelでの操作の後にまとめて手順を掲載します(Microsoft 365オンラインでは、後述の[グループ化]ができないため、説明を割愛します)。
Excelでの操作手順
- セルA3〜D103のいずれかのセルをクリックしておく
- [挿入]タブを開き、[ピボットグラフ]−[ピボットグラフとピボットテーブル]を選択する
- [ピボットテーブルの作成]ダイアログボックスの[テーブルまたは範囲を選択]がオンになっていることを確認する
- [テーブル/範囲]が「勤め先収入3!A3:D103」になっていることを確認する
- [ピボットテーブルレポートを作成する場所を選択してください]の下の[既存のワークシート]をクリックしてオンにする
- [場所]ボックスをクリックし、セルF3をクリックする
これで、空のピボットテーブルと空のピボットグラフが作成されます。画面は図6のようになります。
 図6 空のピボットテーブルと空のピボットグラフが作成された
図6 空のピボットテーブルと空のピボットグラフが作成されたこの段階では、どの項目のどの値を集計し、グラフ化するかが指定されていないので、ピボットテーブルもピボットグラフも空の状態になっている。ここから、集計項目や集計の方法などを指定していく。
まず、勤め先収入ごと、性別ごとに人数を集計しましょう。
- [ピボットテーブルのフィールド]のリストにある[勤め先収入(万円)]を[軸(分類項目)]の欄にドラッグする
- [ピボットテーブルのフィールド]のリストにある[性別]を[凡例(系列)]の欄にドラッグする
- [ピボットテーブルのフィールド]のリストにある[サンプル]を[Σ値]の欄にドラッグする
- [Σ値]の欄の「合計/サンプル」をクリックし、[値フィールドの設定]を選択する
- [選択したフィールドのデータ]リストから[個数]を選択し、[OK]をクリックする
この段階では、勤め先収入の値(F列)に対する人数が、1つずつ表示されています。たとえば、7.3万円の女性が1人、7.9万円の女性が1人といったぐあいです(図7)。
 図7 性別ごとに勤め先収入の人数を集計する
図7 性別ごとに勤め先収入の人数を集計する勤め先収入が縦方向(F列)に、性別が横方向(4行目)に並ぶようにして、それぞれの人数を集計する。[Σ値]に指定した項目は、そのままだと合計が求められる。人数、つまりデータの個数を求めたいので、個数を求めるように集計の方法を変えておく。
これではヒストグラムにならないので、勤め先収入を階級に区切って人数が集計されるようにしましょう。
- F列の値(どれでもいい)を右クリックして[グループ化]を選択する
- [グループ化]ダイアログボックスで[先頭の値]に「10」を入力、[末尾の値]に「100」を入力、[単位]に「5」を入力する
これで、勤め先収入が階級に区切られ、性別ごとのヒストグラムが作成できました(図8)。
 図8 勤め先収入をグループ化し、階級を作る
図8 勤め先収入をグループ化し、階級を作る10万円未満の人数と100万円より大きい人数がまとめられた。各階級は「以上〜未満」となる。例えば10〜15という階級は10万円以上15万円未満の人数。ただし、[末尾の値]の直前の階級のみ「以上〜以下」となる。この例では、95〜100という階級が0人なのでグラフには表示されていないが、95〜100の階級だけ、95万円以上100万円未満の人数となる。
このままでも分布の特徴は分かりますが、ヒストグラムらしくするために、棒の間隔を「0」にしておきましょう。
- 系列(グラフの棒の部分)を右クリックして[データ系列の書式設定]を選択する
- [系列のオプション]ボタンをクリックする
- [系列の重なり]に「0」(%)を入力する
- [要素の間隔]に「0」(%)を入力する
グラフは以下のようになります(図9)。
 図9 性別ごとに勤め先収入のヒストグラムを作成した例(完成例)
図9 性別ごとに勤め先収入のヒストグラムを作成した例(完成例)全体的に女性の収入が低いことが分かる。男性のヒストグラム(オレンジ色)は30万円〜35万円の山が最も高くなっている。女性のヒストグラム(青色)は30万円〜35万円の山と10万円〜15万円の山が最も高い。
性別によるヒストグラムを見ると、明らかに男女間で収入の格差があることが分かります。特に、女性で10万円〜15万円のところに山ができていることも分かりますね。もちろん、このデータは架空のデータなので、実態を表しているわけではありませんが、実態としては、2021年の男性の収入を100とすると、女性の収入は75.2となっています(内閣府男女共同参画局の「男女間賃金格差(我が国の現状)」による。一般労働者の給与水準)。ちなみに、サンプルデータの中央値は男性が34.9万円、女性が25.9万円で、ほぼその割合(34.9/25.9=0.74)になるようにしてあります。
ピボットテーブル/ピボットグラフでは、項目(フィールド)や集計項目をドラッグ操作で自由に入れ替えられるので、さまざまな方向からの分析ができます。以下に、幾つかの例を示しておきます(図10、図11)。[データ系列の書式設定]ウィンドウの右上に表示されている[×]ボタンをクリックすれば、[データ系列の書式設定]ウィンドウが閉じられ、[ピボットグラフのフィールド]ウィンドウが表示されます。ぜひ、試してみてください。
 図10 雇用形態ごとに勤め先収入のヒストグラムを作成した例
図10 雇用形態ごとに勤め先収入のヒストグラムを作成した例[ピボットテーブルのフィールド]に表示されている[性別]のチェックマークをオフにし、[雇用形態]を下の[凡例(系列)]の欄にドラッグすると、雇用形態ごとのヒストグラムが作成できる。全体的に非正規職員の収入が低いことが見て取れる。
 図11 男女ごと、雇用形態ごとに勤め先収入のヒストグラムを作成した例
図11 男女ごと、雇用形態ごとに勤め先収入のヒストグラムを作成した例[ピボットテーブルのフィールド]に表示されている[性別]を下の[凡例(系列)]の欄にドラッグし、[雇用形態]を[軸(分類項目)]の欄の[勤め先収入(万円)]の上にドラッグすると、男女ごと、雇用形態ごとのヒストグラムができる。女性の非正規職員に10万円〜15万円の大きな山があることが分かる。
Googleスプレッドシートでの操作手順
Googleスプレッドシートでの操作は以下の通りです。こちらのサンプルファイルを開いて、メニューから[ファイル]−[コピーを作成]を選択し、Googleドライブにコピーしてお使いください。[勤め先収入3]ワークシートにデータが入力されています。
- セルA3〜D103のいずれかのセルをクリックしておく
- メニューバーから[挿入]−[ピボットテーブル]を選択する
- [ピボットテーブルの作成]ダイアログボックスの[データ範囲]が「勤め先収入3!A3:D103」になっていることを確認する
- [挿入先]の下の[既存のワークシート]をクリックしてオンにする
- [データ範囲を選択]ボタン(田のマークのボタン)をクリックして、セルF3をクリックし、[OK]をクリックする
- [作成]ボタンをクリックする
これで、空のピボットテーブルが作成されます。画面の右側にピボットテーブルエディタが表示されるので、以下のように操作しましょう。
- 右側に表示されている項目一覧の[勤め先収入(万円)]を、左側の[行]の下にドラッグする
- [総計を表示]のチェックマークをクリックしてオフにする
- 右側に表示されている項目一覧の[性別]を、左側の[列]の下にドラッグする
- [総計を表示]のチェックマークをクリックしてオフにする
- 右側に表示されている項目一覧の[サンプル]を、左側の[値]の下にドラッグする
- [集計]ボックスからの[COUNT]を選択する
集計が行われますが、図7で見たような勤め先収入に対する人数(F列)が、1つずつ表示された表になります。そこで、勤め先収入の階級を設定します。
- 作成されたピボットテーブルの[勤め先収入(万円)]の値(F列の値ならどれでもいい)を右クリックして[ピボットグループのルールを作成]を選択する
- [グループ化のルール]ダイアログボックスで、[最小値]に「10」、[最大値]に「100」、[間隔のサイズ]に「5」を入力し、[OK]ボタンをクリックする
これで、図8で見たようなピボットテーブルが作成されます。後は縦棒グラフを作成するだけです。
- 作成されたピボットテーブル(セルF3〜H18)のいずれかのセルをクリックする
- メニューバーから[挿入]−[グラフ]を選択する
- グラフエディタで[グラフの種類]のリストから[縦棒グラフ]を選択する
ピボットテーブルエディタで項目を入れ替えると、グラフも自動的に表示し直されるので、雇用形態別のヒストグラムなども簡単に作成できます。ただし、図11と同様の、男女ごと、雇用形態ごとのヒストグラムにするには、以下のような操作を行います。なお、ピボットテーブルエディタが表示されていない場合には、セルF3〜H18に作成されているピボットテーブルの左下にマウスポインタを位置付け、[編集]ボタン(鉛筆のアイコンのボタン)をクリックしてください。
- ピボットテーブルエディタで、[雇用形態]を、左側の[行]の下、[勤め先収入(万円)]の上にドラッグする
ただし、この段階では、女性だけのヒストグラムしか表示されないので、グラフエディタで系列を追加する必要があります。
- グラフを右クリックし[データ範囲]を選択する
- グラフエディタで[系列を追加]ボタンをクリックし、[データ範囲の選択]ボタン(田のマークのボタン)をクリックして、セルI4〜I24をドラッグする
- [OK]ボタンをクリックする
ピボットテーブルエディタでの設定とグラフエディタでの設定が正しくできれば、図12のようなグラフになります。
 図12 男女ごと、雇用形態ごとに勤め先収入のヒストグラム(Googleスプレッドシート)
図12 男女ごと、雇用形態ごとに勤め先収入のヒストグラム(Googleスプレッドシート)Excelで作成した図11の例と同じグラフ。Googleスプレッドシートでは、棒の間隔を変えることができないので、やや見た目は異なるが、分析を行う上での支障はない。
今回は、ヒストグラムや箱ひげ図により、集団の特徴を可視化する方法を見てきました。まず、全体像を見た上で、データを切り分けていくことにより、外れ値を発見したり、集団の中に含まれる幾つかの特徴や「層」を見いだしたりする流れを紹介しました。
次回は、クロス集計表を作成したり、ヒートマップを作成することにより、複数の項目同士がどう関係しているか、その関係の中からどのような特徴が見いだせるかを、ケーススタディーを通して追いかけていきます。次回もどうぞお楽しみに!
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。