scikit-learn入門&使い方 ― 機械学習の流れを学ぼう:機械学習入門
「知識ゼロから学べる」をモットーにした機械学習入門連載の第2回。実践で役立つ、Pythonライブラリの基本的な使用例として、データの読み込みと加工(pandas使用)から、数値計算(NumPy使用)とデータ可視化(Matplotlib/seaborn使用)、機械学習(scikit-learnの使い方)までを体験しながら学ぼう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
ここを更新しました(公開日:2024年4月11日、更新日:2024年12月2日)
2024年12月2日最新のColab環境で、記事内の全てのコードが正常に動作することを検証しました。
前回は、機械学習の基礎と、主要なPythonライブラリの概要を説明しました。
今回は、Pythonを使った機械学習プログラミングの基本的な流れを、実際にコードを書きながら体験的に学んでいきましょう。具体的には、データの読み込みと加工から、グラフによる可視化、統計的な数値計算、そして簡単な機械学習モデルの構築まで、基本的な一連の流れを体験できます(図1)。

今回で学べること
図1の通り、機械学習プログラミングの基本的な流れに沿って進めると、第1回で紹介した主要なPythonライブラリ(pandas、NumPy、Matplotlib、seaborn、scikit-learnなど)を各場面で使い分けることになります。
各ライブラリを深く理解して使いこなすためには、個別に詳しく学ぶことが必要です。ただし本連載では、詳細には触れず、実践で役立つ基本的な使用例に絞って説明します。もっと深く掘り下げて学びたい人は、『Pythonデータ処理入門』連載を併読することをお勧めします。
まとめると、今回は図2に示す内容を学ぶことができます。

それでは、まずは今回使用するデータの紹介から始めていきます。
連載:

「機械学習は難しそう」と思っていませんか? 心配は要りません。この連載では、「知識ゼロから学べる」をモットーに、機械学習の基礎と各手法を図解と簡潔な説明で分かりやすく解説します。Pythonを使った実践演習もありますので、自分の手を動かすことで実用的なスキルを身に付けられます。
次回からは、具体的な機械学習の手法(例:線形回帰、決定木、k-meansなど)を解説していきます。次回以降の新着記事を見逃さないように、ぜひ以下のメール通知の登録をお願いします。
0. 今回使用するデータセット
今回は、あやめ(Iris)という花のデータセット(Dataset:データの集まり)を使います(配布元:https://doi.org/10.24432/C56C76、ライセンス:CC BY 4.0)。

Irisデータセットは、機械学習の基本的な流れを学ぶ上で理想的な特性を持っています。説明変数が4つとシンプルで、データ数が150件と少ないながらも必要十分です。全体を容易に把握できる規模なのが、初心者にピッタリなので採用しました。
機械学習の初心者向けチュートリアルでよく使われているので「またか……」と思われるかもしれませんが、機械学習の基本的な流れを体験できるように少しアレンジしていますので、新たな気持ちで取り組んでもらえるとうれしいです。
Irisデータセットの説明変数(特徴量)は、
- Sepal Length: がく片の長さ(cm)
- Sepal Width: がく片の幅(cm)
- Petal Length: 花びらの長さ(cm)
- Petal Width: 花びらの幅(cm)
の4項目となっています。なお、がく片も花びらも「花(はな)」を構成する要素で、花を保護する役割を持つ「萼片(がくへん)」は花の一番外側にあり、「花弁(はなびら、かべん)」はがく片よりも内側にあります(図1)。あやめは、がく片が特に美しいですね。

Irisデータセットの目的変数(ターゲット、ラベル)は、あやめの種類(クラス:Class)です。具体的には、
- setosa: セトーサ(日本名:ヒオウギアヤメ)
- versicolor: ヴァーシカラー(日本名:ブルーフラッグ)
- virginica: ヴァージニカ(日本名:ヴァージニカ)
の3種類があります。それぞれ50件ずつで、合計150件です。
今回の機械学習では、データ(4項目の特徴量)を基に、あやめの種類を予測することが目標となります。つまりこれは、分類問題を解くタスクです。
それでは、このデータセットをPythonで読み込んでみましょう。
ノートブックの利用について
本連載は、第1回で説明したように、無料のクラウド環境「Google Colab」の利用を前提としています。基本的には、Colabで新規ノートブックを作って、以降で説明するコードを入力しながら実行結果を自分の目で確かめてください。既に入力済みのノートブックを使いたい場合は、こちらのサンプルノートブックをご利用ください。
1. サンプルデータを読み込んでみよう(pandas使用)
PythonでCSVファイルやExcelファイルのデータを読み込むなら、pandasというライブラリがとても便利です(参考記事)。関数呼び出し一発でデータを読み込めて便利なので、機械学習の実践でよく使われています。なお、機械学習に使える各Pythonライブラリは第1回で説明したので、今回は全て説明を割愛します。
pandasには、CSVファイル用のread_csv()関数や、Excelファイル用のread_excel()関数が用意されています。いずれもファイルシステム上のパスや、インターネット上のURLを、関数の第1引数に受け取ります。よって、URLを指定してインターネット上にあるIrisデータセットを読み込むには、リスト1のように書いてください(ここでは、後述する前処理を実際に試してみるために、データを少し改変したものを筆者のGitHubリポジトリで配布しています)。
import pandas as pd
# データの読み込み
url = 'https://raw.githubusercontent.com/isshiki/machine-learning-with-python/main/02-scikit-learn/iris_processed.csv'
df = pd.read_csv(url)
# データの確認
df.head()
ノートブックでは、各コードセルの最後に記述された「関数や変数など」の出力が自動的に表示(display)される仕様です。この特徴を利用して、本稿では全て最後のprint()関数を省略しています。しかし、.pyファイルなどでスクリプトを実行して出力を見たい場合は、print(df.head())のように明示的に出力を指示してください。
pandasをインポートしたときの別名は、通常、pdとします。pd.read_csv(url)で読み込んだデータは、DataFrame(データフレーム)と呼ばれる2次元(表形式)データのオブジェクトとして変数dfに割り当てられます。
正常に読み込めたかどうかを確認するために、そのdfオブジェクトのhead()メソッドを呼び出しています。これにより、読み込んだデータの先頭5行が表示されます(図4)。
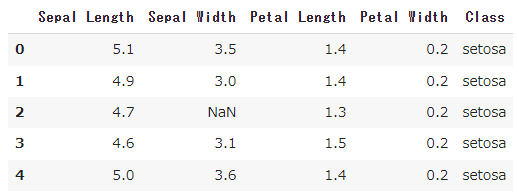 図4 読み込んだデータの内容表示例
図4 読み込んだデータの内容表示例全行を出力すると表示が長大になるので、このように先頭の5行だけを表示しています。機械学習で頻繁に使うテクニックの一つです。

今回のデータ数は150件と少量ですが、現実の機械学習プロジェクトではしばしば巨大なデータセットを扱います。pandasで大規模データセットを読み込もうとすると、コンピュータの物理メモリ(RAM)の不足によりメモリエラーが発生することがあります。
この問題を回避する一つの方法は、「Dask」というライブラリをpandasの代わりに使用することです。Daskはpandasと互換性があり、大規模データの処理に適しています。
ただし、初心者の段階ではDaskの学習は必須ではありません。巨大なデータセットを扱う必要が出てきたときに、Daskやpandasのメモリ管理に関する対処法を学ぶことをお勧めします(対処法の参考記事)。
読み込んだデータは、そのまま使えない?! 前処理の必要性
データを用意できたから、さっそく機械学習を始めよう……ということには、通常、なりません。データを何も確認せずに使うのは危険だからです。特に手入力されたデータの場合、一部の値が誤って入力されたり、欠損していたりすることがよくあります。
例えば0.001を1.0と誤入力されるなどして異常値(もしくは他の値と大きく違う外れ値)が含まれていたり、表データの一部分が空欄、つまり欠損値が含まれていたりすることがあります。例えば前掲の図4にある表データの3行2列目のセルに「NaN」(Not a Number:非数)と表示されていましたが、これは「欠損値」を意味します。
また、図4の[Class]列には「setosa」という文字列が表示されていました。scikit-learnは数値のみを扱うので、カテゴリー値(文字列)は、事前に数値(Pythonのint型やfloat型)に置き換えておく必要があります。
異常値や欠損値の処理や、カテゴリー値の数値への置き換えなど、事前にデータをデータ分析や機械学習に適した形に整える作業は前処理(まえしょり:Preprocessing)と呼ばれます。以下に、代表的な前処理の作業をまとめておきます。
- データクリーニング: データの品質を向上させるために、欠損値や異常値、外れ値を処理するなど。
- データの変換: 機械学習モデルが処理できる形式に、カテゴリー値を数値データに変換するなど。
- 正規化/標準化: 機械学習モデルが処理しやすいように、特徴量(説明変数)のスケール(単位)を統一すること。後述。
機械学習の世界では、この前処理(と後述のコラムに書いた特徴量エンジニアリング)に大半の時間(一説には8割)を費やすと言われています。しかし、この手間を惜しまずに丁寧に行うことで、機械学習モデルの性能が大幅に向上する可能性があります。
そこでここからは、先ほどの説明と順番が前後しますが、「カテゴリー値の数値への置き換え」「欠損値の処理」「異常値の処理」の順で前処理をやってみましょう。
【コラム】特徴量エンジニアリング
前処理と一部が重複する作業に、特徴量エンジニアリングがあります。前処理はデータをきれいに整えることに焦点を当てているのに対し、特徴量エンジニアリング(Feature Engineering)は「機械学習モデルの性能を向上させる」ために新しい特徴量(説明変数)を作り出すことに焦点を当てています。具体的には、主に以下の作業を行います。
- 特徴量の作成: 既存のデータから新しい特徴量を作り出す。例えば[日付]から[曜日]を作り出す。また、[年齢]と[収入]という複数の特徴量を組み合わせて[購買力スコア]という新しい特徴量を作成するなど。
- 特徴量の選択: 機械学習モデルの性能に大きく寄与する特徴量を調べて選択する。また、無関係または類似の特徴量を削除するなど。
特徴量エンジニアリングを行うには、まずデータを深く理解する必要があります。このために、さまざまなPythonライブラリを駆使してデータを分析したり可視化したりするわけです。
また、データを生む分野における専門知識(ドメイン知識と呼ばれます)も必要です。例えば野球データなら「ヒット」や「ホームラン」などの知識は不可欠です。この知識によって、データからより意味のある特徴量を見つけ出せるからです。
2. 前処理:カテゴリー値を数値に置き換えよう(pandas使用)
それでは、DataFrame(pdオブジェクト)の[Class]列に含まれる文字列のカテゴリー値を、int型の数値に置き換えてみます。コードは、リスト2のように書いてください。
# カテゴリー値を数値にマッピング
class_mapping = {'setosa': 0, 'versicolor': 1, 'virginica': 2}
df['Class_ID'] = df['Class'].map(class_mapping)
# データの確認
df.head()
このコードにより、setosa/versicolor/virginicaは、それぞれ0/1/2という数値に置き換えられ、新たな[Class_ID]列がDataFrameに追加されます。変換前の値を参照できるように、元の[Class]列も残しています。図5は実行結果です。
機械学習では、通常、カテゴリー値は0(もしくは1)から始まる連番の整数値に置き換えたりします(この手法はラベルエンコーディングと呼ばれます)。順序が意味を持つカテゴリー(例えば「5段階の満足度」など)の場合は、その順序に沿って数値を割り当てます(この手法は序数エンコーディングと呼ばれます)。ちなみに、この他にも、ワンホットエンコーディングなどの手法がありますが、本稿では説明を割愛します。
カテゴリー値を連番の数値に効率的に変換するには、map()メソッドが便利です。これは、pandasのSeries(シリーズ、この例ではdf['Class']で取得した[Class]列を表す1次元データのオブジェクト)に含まれるメソッドで、置き換えの組み合わせ(=マッピング)をdictオブジェクト(この例ではclass_mapping)で受け取って、それに従い変換してくれます。


カテゴリー値を含む列のデータは、カテゴリー変数やカテゴリカルデータとも呼ばれます。
3. 前処理:欠損値がないか確認し、あれば対処しよう
欠損値の有無を調べる(pandas使用)
pandas DataFrameの各列に「欠損値」があるかどうかを確認してみましょう。コードはリスト3の通りです。
# 各列における欠損値の数を確認
df.isna().sum()
isna()メソッドは、NaNなどの欠損値がある配列要素にTrueを、それ以外の配列要素にはFalseを設定した、新しいDataFrameを返します。
sum()メソッドは、DataFrameの列単位で合計値を返します。
図6が実行結果です。bool値を数値にすると、Trueが1で、Falseは0なので、各「合計値」はそのまま「欠損値の数」を意味することになります。
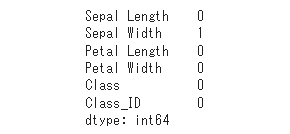 図6 各列の欠損数の表示例
図6 各列の欠損数の表示例[Sepal Width]列に、1件の欠損値があることが確認できました。前掲の図4にあるNaNですね。
欠損値を処理する(pandas使用)
欠損値に対処するには、主に以下の方法があります。
- 欠損値のある行や列の削除: 最も一般的な対処方法。dropna()メソッドが使用できる。データが十分にある場合に有効だが、データが失われる代償が伴う。
- 中央値や最頻値などで補完: 連続値の場合は中央値、カテゴリー値の場合は最頻値などの統計量で、欠損値を埋める。fillna()メソッドが使用できる。手軽だが、データの分布を歪(ゆが)めて機械学習の結果に影響を与える可能性がある。
- 別アルゴリズムで補完: 何らかのアルゴリズムを使用してデータの既知の部分から推測して、欠損値を埋める。例えばk近傍法(k-NN、今後の連載で説明予定)アルゴリズムによる補完(impute)は、scikit-learnのKNNImputerクラスが使用できる。計算コストは高まるが、データの特性をより正確に反映できる可能性がある。
今回の例では欠損値が1つしかなく、「たった1行を削除しても機械学習の結果に大した影響はない」と考えられるので、「欠損値のある行の削除」を行うことにします(リスト4)。
# 欠損値のある行を削除
df_dropped = df.dropna()
# 結果の出力
print('元データの行数: ', len(df))
print('欠損値処理済みデータの行数: ', len(df_dropped))
dropna()メソッドの使い方について補足説明すると、デフォルトでは欠損値を含む行を削除しますが、引数にaxis=1を指定すると列を削除します。特定の列に多くの欠損値が含まれている場合(例えば、その列のデータの半分以上が欠損しているなどの場合)、その列の削除を検討してください。
Pythonのlen()関数の引数にDataFrame(この例ではdf_droppedなど)を渡すと、その行数が分かります。図7はその実行結果で、確かに1行減っていることが確認できました。
リスト4のdf.dropna()という書き方は一例にすぎません。例えば、代わりにdf[~df.isna().any(axis=1)]と書くこともできます(コード内容の説明は割愛します)。以降のコードも、あくまで書き方の一例にすぎないのでご注意ください。
4. 前処理:異常値がないか確認し、あれば対処しよう
グラフから異常値を検出する(Matplotlib使用)
次に、pandas DataFrameの各列に「異常値」(や「外れ値」)があるかどうかを確認してみましょう。異常値は、データをグラフとして可視化すると一目りょう然です。
異常値の検出に役立つグラフとしては、例えば以下のものがあります。図の詳細は、リンク先などを確認してください。
- 箱ひげ図: データの分布を四分位範囲(25%〜75%)の箱で表し、中央値/最小値/最大値の他、外れ値を小さな丸で表す。異常値(外れ値)を視覚的に確認しやすい(参考記事)。
- 散布図: データの2変数(=2つの特徴量)間の関係を点でプロットする(=示す)。異常値は、他のデータポイントから離れた点として目立つので把握しやすい(参考記事)。
- ヒストグラム: データの分布を隣接した棒グラフで表す。異常値は、分布の外れた部分にある小さな棒として検出できる(参考記事)。
- 時系列プロット(折れ線グラフなど): グラフの横軸に時間軸を取って値をプロットする。時間の経過とともにデータがどのように変化しているかを確認できる。異常値は、他のデータポイントよりも高い値または低い値として表示される(参考記事)。
今回は最も基本的な箱ひげ図を描画してみましょう(リスト5)。
import matplotlib.pyplot as plt
# 4つの特徴量(説明変数)を選択
df_features = df_dropped.loc[:, ['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width']]
# 箱ひげ図を表示
df_features.boxplot()
plt.show()
Pythonで基本的なグラフを描画するには、ライブラリ「Matplotlib」を使います。そのグラフ描画モジュールであるmatplotlib.pyplotをインポートしたときの別名は、通常、pltとします。
ここでは、4つの特徴量に対して箱ひげ図を作成することにします。そこで、DataFrameから特徴量だけを抽出します。これには、行列データの一部を抽出できるlocメソッドが使えます。
リスト6では、locメソッドの引数に対して:で全行が、["Sepal Length", "Sepal Width", "Petal Length", "Petal Width"]で4つの特徴量が指定されています。df_features変数には4つの特徴量だけを含む新たなDataFrameが割り当てられます。
そのDataFrameのboxplot()メソッドを呼び出すと、内部でMatplotlibを使った箱ひげ図が作成されます。
作成されたグラフをノートブック上に表示するには、plt.show()メソッドを呼び出します。図8はその実行結果です。
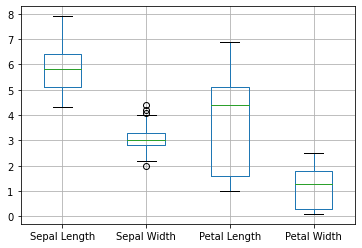 図8 異常値を発見するために箱ひげ図を表示した例
図8 異常値を発見するために箱ひげ図を表示した例[Sepal Width]列には小さな丸が幾つか表示されており、(箱ひげ図の基準で)少し外れ値があるようですが、極端に離れた場所には表示されていないので許容範囲でしょう。今回は異常値はないものとして、そのまま全てのデータを使うようにします。
もし異常値がある場合は、先ほどの欠損値と同じように削除するか補完するなど、状況に応じて判断しましょう。基本的には、異常値のある行や列を削除するのがお勧めです。外れ値が「異常」ではなく実態を反映していると考えられる場合は、そのまま利用するのが適切です。
統計量からも異常値を確認する(pandas使用)
グラフだけでなく、統計量の数値でも二重に確認しておくと安心です。リスト6がそのコードです。
# 選択した特徴量の基礎統計量を表示
df_features.describe()
4つの特徴量だけを含むDataFrameのdescribe()メソッドを呼び出すと、図9のように統計量がまとめて表示されます。便利ですね。
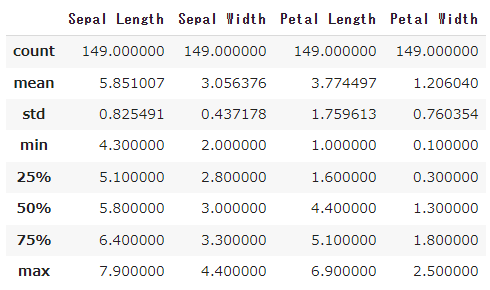 図9 基本的な統計量をまとめて表示した例
図9 基本的な統計量をまとめて表示した例統計量を見ることで、データの全体像を把握し、異常値の存在を感じ取ることができます。特に、最小値(min)が第1四分位数(25%)から、もしくは最大値(max)が第3四分位数(75%)から大きく離れている場合は、異常値の可能性が高いと考えられます。
他には、平均値(mean)と中央値(50%)が大きく乖離(かいり)していたり、標準偏差(std)が異常に大きい、つまりデータが広くバラついていたりする場合は、データの偏りや異常値の存在を示唆している可能性があります。
【応用テクニック】より洗練された可視化と数値計算
より高度なグラフ描画(seaborn使用)
先ほどは異常値の検出に役立つグラフとして箱ひげ図や散布図などを紹介しましたが、いずれもMatplotlibで作成できます。さらにseabornライブラリも活用することで、より多様なグラフを作成できるようになります。その一例が「ビースウォーム図」です。
- ビースウォーム図(Bee Swarm Plot:蜂群図): 散布図と箱ひげ図の特性を組み合わせたもので、データポイントを重ねずに表示し、データの分布をより明確に示す。異常値は、他のデータポイントから離れた点として目立つので把握しやすい。ただし、小規模なデータサイズ向きで、大規模データセットには向かない。
ここではビースウォーム図を作成してみましょう。まずはリスト7のコードを実行して、seabornライブラリをインストールします。
! pip install seaborn
ノートブックのコードセルでは、!で始まる行がOSのシェルコマンドとして実行されます。
Pythonディストリビューション「Anaconda」のcondaを使っている場合は、代わりにconda install seabornコマンドをターミナルで実行してください。
次に、ビースウォーム図を描画します(リスト8)。seabornはMatplotlibベースのライブラリなので、やはりmatplotlib.pyplotモジュールのインポートが(基本的に)必要です。
# seabornライブラリのインポート
import seaborn as sns
import matplotlib.pyplot as plt
# seabornでビースウォーム図を作成する
sns.swarmplot(data=pd.melt(df_features), x="variable", y="value", size=2.5)
plt.show()
ライブラリ「seaborn」のseabornモジュールをインポートしたときの別名は、通常、snsとします。ちなみに「sns」は、あるテレビドラマの登場人物「Samuel Norman Seaborn」に由来するそうです。
ビースウォーム図を作成するには、sns.swarmplot()メソッドを呼び出します。そのdata引数にpd.melt(df_features)を指定していますが、これはswarmplot()メソッドが「ロング形式」の表形式データ(Tabular data:行と列の形式で整理されたデータ)を前提としているためです。
ロング形式(Long-form)とは表形式データを「縦長」形式で、またワイド形式(Wide-form)とは「横長」形式で整理する方法です(参考記事)。例えばIrisデータセットは、各行が1つのデータポイントで、各列が特徴量(がく片の長さ、がく片の幅、花びらの長さ、花びらの幅)になっているワイド形式の表形式データです。
これをロング形式に変換する場合、各特徴量を個別の4つの列から「特徴量の種類」として1つの列にまとめ、「値」をもう1つの列で表します(図10)。
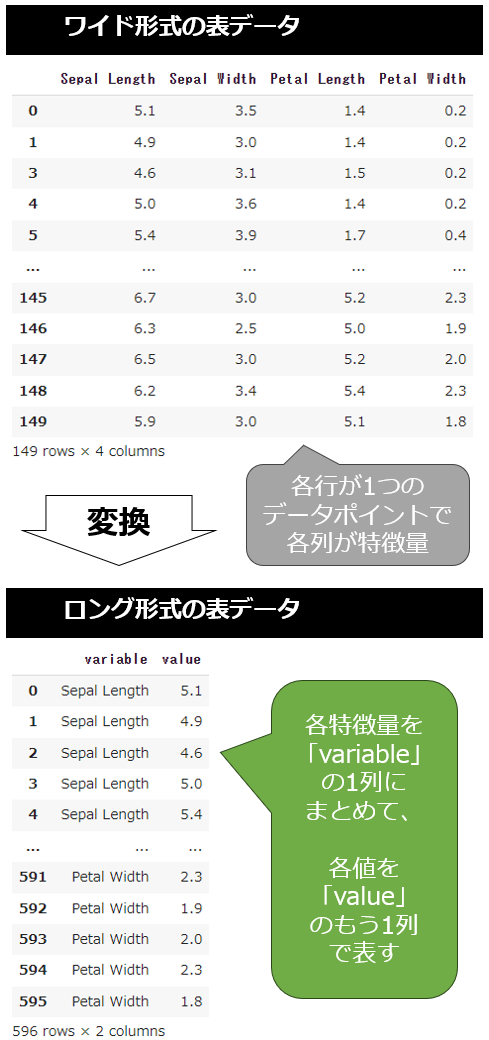 図10 Irisデータセットをワイド形式からロング形式に変換した例
図10 Irisデータセットをワイド形式からロング形式に変換した例このようなワイドからロングへの形式変換は、pd.melt()メソッドを呼び出すだけでできます。デフォルトで「特徴量の種類」列はvariable、「値」列はvalueという名前になります。sns.swarmplot()メソッドのx="variable", y="value"という引数はこの名前を指定しているわけです。
size=2.5引数は、プロットされる点(データポイント)の大きさを指定しています。ビースウォーム図は、点を重ねずに表示する仕様です。データ数が多いと点が重なり、メソッド呼び出し時に警告が表示されます。それを回避するために、点自体を小さくしています。
あとは先ほどと同様にplt.show()メソッドで、ノートブック上に表示するだけです(図11)。
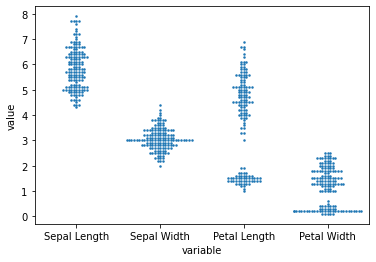 図11 異常値を発見するためにビースウォーム図を表示した例
図11 異常値を発見するためにビースウォーム図を表示した例今回のビースウォーム図には、他から大きく離れたデータポイントはなく、異常値が存在しないのを確認できます。
【コラム】探索的データ分析で有用なseabornのpairplot
seabornのpairplot関数が有用なので紹介します。使い方は簡単なので説明不要でしょう(リスト9)。ちなみに、pandasにも同様のことができるscatter_matrix()関数が存在します。
sns.pairplot(df_features)
plt.show()
この関数は、DataFrame内の各特徴量でペアを作って多数のグラフを一度に作成してくれます。4つの特徴量がある場合、16個の図(4×4のマトリックス)が作成されます(図12)。

特徴量間の関係や各特徴量の分布を一目で確認できます。対角線上のセル(例:1行1列目の[Sepal Length]同士のペア)では「各特徴量の分布」がヒストグラムで、その他のセル(例:1行2列目の[Sepal Length]と[Sepal Width]のペア)では「2つの特徴量間の関係」が散布図で描画されます。
このようにpairplot関数を利用すると、特徴量間の相関や、分布の形状、異常値の有無など、データセットの概要を素早く把握できます。
機械学習プロジェクトでは、(前処理によって品質が向上した)データセットを深く理解することが、特徴量の選択やハイパーパラメーター(=訓練前に人間によって指定する設定項目)のチューニング(調整)のために非常に重要です。この作業は探索的データ分析(EDA:Exploratory Data Analysis)と呼ばれますが、その初期段階でこの関数が役立ちます。
より高速な数値計算(NumPy使用)
前掲のリスト6ではpandasを使って統計量を求めました。しかし、特に大量のデータで数値計算や配列操作をする際には、pandasよりもNumPyの方が効率が良い場合が多いので、NumPyがお勧めです。
数値計算ライブラリ「NumPy」のndarrayと呼ばれる配列データは、pandasのDataFrameに比べて、アクセスや数値計算がより高速だからです。これは、ndarray(内の全ての値)が一様なデータ型で構成され、低レベルの最適化が施されているためです。

試しに筆者がColab上で速度を比較したところ、2次元データ(NumPy ndarray vs. pandas DataFrame)では、NumPyがpandasよりも「配列要素へのアクセス」は約200倍速く、「平均の計算」は約30倍速い結果が、また1次元データ(NumPy ndarray vs. pandas Series)では、NumPyがpandasよりも「配列要素へのアクセス」は約1000倍速く、「平均の計算」は約8倍速く、「掛け算の計算」は約100倍速い結果が出ました(参考:サンプルノートブックで試せます)。ただし、結果は実行環境やデータ内容によって変わりますのでご注意ください。
一方のpandasは、これまでに説明したデータの前処理や分析の初期段階で便利です。pandasとNumPyの両ライブラリは、利用シーンで適切に使い分けるとよいでしょう。
ここでは、pandasで前処理を行ったデータをndarrayに変換し、平均を計算してみます(リスト10)。
import numpy as np
# pandasのDataFrameをndarray(NumPy配列)に変換
features_array = df_features.to_numpy(dtype='float32')
# NumPyで各列の平均値を計算する
mean_features = np.mean(features_array, axis=0)
mean_features # 出力例: array([5.8510065, 3.0563755, 3.7744968, 1.2060403], dtype=float32)
numpyモジュールをインポートしたときの別名は、通常、npとします。
pandasのto_numpy()メソッドで、DataFrameをNumPyのndarrayに変換できます。ndarrayはDataFrameと異なり、一様なデータ型に統一する必要があるため、引数にdtype='float32'を指定して明示的にデータ型を統一しています。
さらに、NumPyの数値計算メソッドの一例としてnp.mean()メソッドを呼び出しています。計算結果は、pandasを使った図9のmeanと同じです。
【コラム】正規化や標準化を行うにはscikit-learnが便利
機械学習では、各特徴量(データ)のスケール(単位)を統一する作業である正規化(Normalization)を行うことで、学習効率の向上や機械学習モデルの性能向上が期待できます。正規化の代表的な手法の一つが標準化(Standardization)です。
標準化は、各特徴量で平均(つまりデータの分布の中心)を「0」に、標準偏差(つまり平均からのデータのばらつき具合)を「1」のスケールに変換(=スケーリング)する手法です。この計算は、データから平均値を引いた上で、標準偏差で割るだけ(例:(data - mean) / std)なので、NumPyやpandasでも簡単に実装できます。
scikit-learnを使えばもっと簡単です。sklearn.preprocessingモジュールに用意された、さまざまな正規化のためのクラスが利用できます。標準化には、StandardScalerクラスが使えます(リスト11)。
from sklearn.preprocessing import StandardScaler
# scikit-learnで全ての特徴量を標準化
scaler = StandardScaler()
sk_scaled = scaler.fit_transform(features_array)
sk_scaled[:2] # 先頭2行を表示する
# 出力例:
# array([[-0.9128386, 1.0181674, -1.353994 , -1.3275825],
# [-1.1559356, -0.1293889, -1.353994 , -1.3275825]], dtype=float32)
fit_transform()メソッドにより、データが変換(この場合は標準化)されます。標準化は、データセット内の全特徴量(この例ではfeatures_array)に対してまとめて行うのが一般的です。
注意点として、scikit-learnとNumPyやpandasでは、標準偏差の計算方法が微妙に異なる可能性があります。scikit-learnではデフォルトで母集団の標準偏差を使用し、NumPyやpandasでは引数ddof=1を指定することで不偏標準偏差(=標本から母集団の標準偏差を推定した値)を選択できます。ddof=0を指定すると、scikit-learnと同じ標準偏差になります。
具体例として、NumPyやpandasでは(data - data.mean(axis=0)) / data.std(axis=0, ddof=0)というコードで標準化を実装できます。引数のaxis=0は、列方向(つまり特徴量ごと)の計算を意味します(参照:NumPyのヘルプ、pandasのヘルプ)。小数点以下の丸め誤差などにより、scikit-learnとNumPyやpandasの計算結果は、完全に一致しないこともあります。
このような数値の変換方法をもっと知りたい場合は、こちらの記事内の「特徴量エンジニアリング」―[数値変数]の説明を参考にしてください。
ここまで、「データの読み込み」から、欠損値や異常値の処理といった「前処理」を行い、データの品質を向上させてきました。また、少し応用的になりますが、データ可視化などによりデータセットを深く理解する「探索的データ分析」と、特徴量の新規作成や選択などを行う「特徴量エンジニアリング」についても、コラムで紹介しました。これらはいずれも、機械学習モデルの性能を向上させるために重要な作業です。ここからは、いよいよ機械学習の段階に入ります。
5. 機械学習の準備:データを訓練用とテスト用に分割しよう(scikit-learn使用)
機械学習モデルを訓練する前に、データを訓練用データセット(Training set:訓練セット)とテスト用データセット(Test set:テストセット)に分割することが一般的です。これは、モデルが学習に使用されていない「未知のデータ」に対してどれだけうまく予測できるか、すなわちモデルの汎化性能(はんかせいのう)を正確に評価するためです。
モデルの訓練プロセスから分離独立したテストセットを用意することで、「実世界の未知のデータに対するモデルの真の性能」(=汎化性能)を把握できるようになります。これにより、モデルが訓練データに過剰に適合(「Over-fitting:過学習」とも呼ばれます)してしまう問題を検出できるようになります。
そこで今回は、データの90%を訓練セットに、10%をテストセットに割り当てます(図13)。分割の割合に明確な基準はありませんが、今回はデータ数が149件と少ないので、テストセットは少なめにしました。一般的には80%:20%か70%:30%が多いようです。訓練セットを多くすると学習しやすくなり、テストセットを多くすると汎化性能を適切に評価しやすくなると考えられます。

scikit-learnライブラリを使えば、データ分割が簡単に行えます。具体的にはsklearn.model_selectionモジュールのtrain_test_split()関数で、データセットを訓練用とテスト用に分割できます(リスト12)。
from sklearn.model_selection import train_test_split
X = df_features # 入力データ(X:特徴量):モデルへ入力する説明変数
y = df_dropped['Class_ID'] # 正解値(y:ラベル):予測したい目的変数
# データを訓練セットとテストセットに分割(テストセットは全体の10%に設定)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
# 訓練セットの特徴量とラベルを結合して、先頭5行を表示
pd.concat([X_train, y_train], axis=1).head()
入力データとなる4つの特徴量はXという変数に、モデルによる予測結果と比較するための正解値となるラベル(目的変数)はyという変数に割り当てています。これは、数学を意識した書き方で、大文字のXは行列データ(=2次元の配列データであるDataFrame)を、yはベクトルデータ(=1次元の配列データであるSeries)を意味します。
train_test_split()関数の引数には、そのXとyに加えて、test_size=0.1が指定されています。これはデータの10%(=0.1)をテストセットにすることを意味します。
前掲の図3で見たように、Irisデータセットは先頭が全て「setosa」種になっているなど、特定の順序で並んでおり、データが偏っています。そのため、データのシャッフルが不可欠です。train_test_split()関数は、デフォルトでshuffle=Trueが設定されており、引数を指定しなくても自動的にデータをシャッフルします。
random_state=42は、乱数シードと呼ばれる、ランダムにシャッフルする際の基準となる数値です。特定の乱数シード値を指定することで、結果の再現性を保証します。つまり、同じ乱数シードを使用することで、他の人が同じコードを実行した際にも、同じデータの分割結果が得られるようになります。
乱数シードには42という値がよく使われます。『銀河ヒッチハイク・ガイド』(ダグラス・アダムス著)の中で、スーパーコンピュータが750万年かけて「生命/宇宙/万物についての究極の疑問に対する答え」を計算した結果が42だったからです。この数値は、科学技術の文脈でよく引用され、楽しみながらも実験結果の再現性を確保するための一種の伝統となっています。
train_test_split()関数は、訓練セットの特徴量(X_train)、テストセットの特徴量(X_test)、訓練セットのラベル(y_train)、テストセットのラベル(y_test)という4要素のリストを返します。
最後のpd.concat()関数で、訓練セットの特徴量とラベルを1つのDataFrameに連結しています。引数のaxis=1は列に連結することを意味します。
検証用データセットも必要な理由
機械学習モデルを最適化し、その性能を最大限に引き出すためには、適切なハイパーパラメーターのチューニングが不可欠です。チューニングするには、データを訓練セット、検証セット(Validation set:検証用データセット)、テストセットの3つに分割する必要があります。
ハイパーパラメーターのチューニングにテストセットを使用すると、テスト時のデータが事実上「未知」でなくなってしまいます。つまり汎化性能を適切に評価できなくなります。よって、テストセットは使わずに「未知」のまま残して、チューニング時に使う検証セットが新たに必要になるというわけです。
機械学習の解説記事では、検証セットを用意していない場合も多いですが、これはハイパーパラメーターをチューニングしないためだと考えられます。本連載でも、基本的には3分割せずに、訓練セットとテストセットの2分割で済ませるようにします。実際のプロジェクトでは、検証セットを含めた3分割が推奨されます。
検証セットの分割割合は、テストセットと同じくらいにするのが一般的です。それに従い今回は、訓練セットが80%、検証セットとテストセットがそれぞれ10%ずつの割合で分割します(図14)。

今回は、テストセットを既に10%に分割済みなので、訓練セットからさらに検証セットを分割します。90%のうちの10%を分割するのでtrain_test_split()関数の引数にはtest_size=1/9と指定します(リスト13)。1/9(=10%÷90%)と分数形式にしているのは、0.111...という実数値にすると意図が分からないと考えたからです。
# 訓練セットからさらに検証セットを分割(検証セットも全体の10%に設定)
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=1/9, random_state=42)
X_validが検証セットの特徴量で、y_validが検証セットのラベルです。以上で、データの準備が整いました。
【コラム】ホールドアウト検証と交差検証の違い
固定的に訓練セット/検証セット/テストセットに3分割(もしくは訓練セット/検証セットに2分割)して、機械学習モデルの性能を評価する手法をホールドアウト検証(Hold-out Validation)と呼びます。
ホールドアウト検証は、明快で分かりやすいですが、今回のように少ないデータ件数のデータセットを分割すると、分割後の各セットのデータ件数がさらに少なくなってしまう問題があります。また、「シャッフルしている」とは言っても、固定的なデータで訓練し評価することになるので、偏った学習や評価結果になる可能性を否定できません。
できれば「全てのデータ」を余すことなく使って訓練し、偏りがないようバランス良く評価することが望ましいでしょう。これを可能にするのが、交差検証(CV:Cross Validation、クロスバリデーション)です。ただし交差検証でも、最終評価のために事前にテストセットは分割して残しておくようにしましょう。
交差検証は、特にデータ量が少ない場合に有効ですが、計算コストが余計にかかるデメリットもあります。もしランダムで偏りのないデータが大量にあるなら、ホールドアウト検証で十分です。
交差検証の一手法にk-fold交差検証があります。この手法では、データセットを等分なk個のフォールド(fold:部分)に分割し、1つのフォールドを検証セットとして、残りのk−1個のフォールドを訓練セットとして使用します(図15)。このプロセスをk回繰り返し、各フォールドが一度は検証セットとして用いられるようにします。
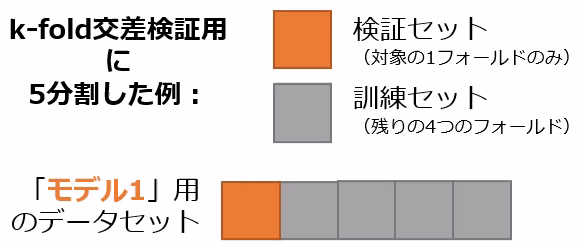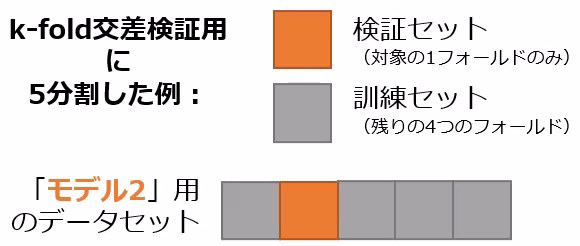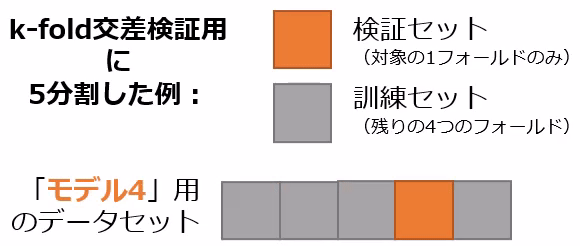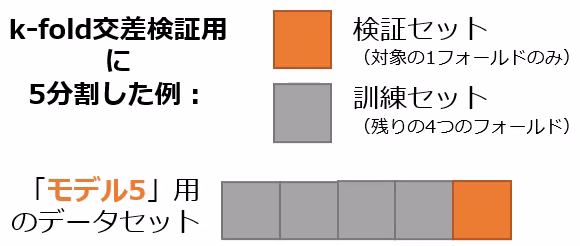 図15 k-fold交差検証で5分割したときの訓練セットと検証セット
図15 k-fold交差検証で5分割したときの訓練セットと検証セット図15はk=5の場合で、「モデル1〜5」と表示されるように5個の機械学習モデルで訓練と検証(評価)をする例です。例えば「回帰分析」のモデルなら、少しずつ異なる5つの訓練済みモデルが作成されます。各モデルを検証セットで評価して、その平均を取ることで、総合的なモデルの性能を評価します。
交差検証は、適切なハイパーパラメーター値(の組み合わせ)を探す目的で役立ちます。scikit-learnには、この目的で使えるsklearn.model_selectionモジュールのGridSearchCVクラスが用意されています(参考記事)。これにより見つかった最適なハイパーパラメーター値で、全ての「訓練セット+検証セット」を使って再訓練して1つの機械学習モデルを作成するのが、一般的な実用方法の一つです。
また、k-fold交差検証で作成したk個のモデルを全て使い、テストセットに対するk個の予測値を取得して、それを平均することなど(アンサンブル学習と呼ばれます)で1つの予測値とすることも、一般的な実用方法の一つです。この方法は、機械学習の競技大会であるKaggleコンペティションでもよく採用されています。実際にこちらの記事で実装しているので参考にしてください。
6. 機械学習の実践:訓練〜予測〜評価しよう(scikit-learnの使い方)
長かったですが、いよいよ最後のステップです。今回は、機械学習に共通する流れを紹介します。個別の機械学習アルゴリズムの内容については、次回以降で個別に詳しく説明していきます。
機械学習プロジェクトでは、機械学習のアルゴリズム(例:回帰分析)を選択し、訓練セットを用いて機械学習モデルを訓練(fit)し、テストセットを用いて訓練済みモデルによる予測(predict)を行います。scikit-learnライブラリを使って、この基本的な流れを簡潔に理解しましょう。なお、現実のプロジェクトでは、訓練時に検証セットを用いてハイパーパラメーターのチューニングも行いますが、今回を含め本連載では基本的に省略します。
今回は機械学習のアルゴリズムとして、迷惑メールの仕分けに使われたことで有名なナイーブベイズ分類器(単純ベイズ分類器)を使用します。scikit-learnでは、sklearn.naive_bayesモジュールのGaussianNBクラスとして、その機能が提供されています。
まずは、機械学習のアルゴリズムや手法を選択します(リスト14)。
from sklearn.naive_bayes import GaussianNB
# 機械学習のアルゴリズムを選択
model = GaussianNB(var_smoothing=1e-9) # ナイーブベイズ分類器
引数にあるvar_smoothingパラメーターは、ナイーブベイズ分類器における分散を平滑化するためのハイパーパラメーターです。特に訓練セットが少ない場合に起こる過学習(過剰適合)の問題を防ぎ、モデルの安定性を向上させるために使用されます。デフォルト値は1e-9(=0が9個で0.000000001)です。
次に、訓練セットを機械学習モデル(model)に入力して、モデルを訓練します(リスト15)。
# 訓練セットを入力して、機械学習モデルを訓練
model.fit(X_train, y_train)
scikit-learnでは基本的に、訓練はmodel.fit()メソッドで行います。fit()メソッドに入力している訓練セットは、pandas DataFrameのX_trainとSeriesのy_trainです。scikit-learnの内部では、基本的にNumPyのndarrayが使われていますが、入出力にはpandasのDataFrameなどもサポートされています。
次に、テストセットを機械学習モデル(model)に入力して、訓練済みモデルで予測します(リスト16)。
# テストセットを入力して、訓練済みモデルで予測
pred_test = model.predict(X_test)
pred_test
# 出力例: array([1, 0, 2, 1, 2, 0, 1, 2, 1, 1, 2, 0, 0, 0, 0], dtype=int64)
scikit-learnでは基本的に、予測はmodel.predict()メソッドで行います。predict()メソッドに入力しているテストセットは、pandas DataFrameのX_testです。このように複数のデータをまとめて予測処理できます。
predict()メソッドの戻り値として、NumPyのndarrayの1次元の配列データが返されています。これには、予測結果がテストセットのデータ順に格納されています。
その予測結果(pred_test)とテストセットの正解値(y_test)を答え合わせして、何%の正解率(Accuracy)かを評価します(リスト17)。
from sklearn.metrics import accuracy_score
# テストセットによる、予測結果の評価
print(f'Accuracy:{accuracy_score(y_test, pred_test)}')
# 出力例: Accuracy:0.9333333333333333
scikit-learnでは、正解率の評価はsklearn.metricsモジュールのaccuracy_score()関数で行えます。なお、評価指標には正解率以外にも適合率やF1スコアなど他にもさまざまなものがあります(参考記事)。
accuracy_score()関数の戻り値として、float値が返されています。0.9333...は「93%」の正解率を意味します。今回は、非常に高い正解率になりました。
テストする前にもしハイパーパラメーターをチューニングするには、リスト14にあったハイパーパラメーターのvar_smoothing値を少し変えて、リスト15の訓練を実行してみてください。リスト16〜17と同じ方法で検証セット(X_validとy_valid)を使って、予測、評価します。正解率がより高い数値になるように、この手順を繰り返すことで最適なハイパーパラメーター値を見つけ出します。
ちなみに検証セットを使って、予測、評価すると正解率は100%でしたので、今回のIrisデータセットとナイーブベイズ分類器の組み合わせでは、ハイパーパラメーターをチューニングをする余地はほとんどなさそうです。
今回は、Pythonによる機械学習の基本的な流れを説明しました。今回の内容を何も見ずにコードを書いていけることが好ましいです。自信がなければ、ぜひ何度も最初からやり直してみてください。また、余裕があれば、末尾の実力試しもやってみてください。
より実践的な機械学習の手順を学びたい人は「『無料のKaggle公式講座×コンペ初参戦』で機械学習を始めよう」という連載記事を一読することをお勧めします。
次回からは、具体的な機械学習の手法(例:線形回帰、決定木、k-meansなど)を解説していきます。各機械学習のプログラミングに共通する内容は今回説明したので、次回からそれと重複する説明は基本的に省略します。
次回は線形回帰をPythonでプログラミングしてみます。お楽しみに。
実力試しクイズ
オレンジ色の部分をクリックまたはタップすると答えが表示されます。ヒントが欲しい場合は、緑色の部分をクリックしてください。穴埋め問題に使える選択肢が表示されます。
問題
機械学習では、まずPythonのライブラリ「pandas」のread_csv()関数を使ってデータを読み込み、DataFrameと呼ばれる2次元(表形式)データのオブジェクトとして取得します。
読み込んだデータには、異常値や欠損値の処理や、カテゴリー値の数値への置き換えなど、事前にデータをデータ分析や機械学習に適した形に整える前処理が不可欠です。
異常値や外れ値は、データをグラフとして可視化すると一目りょう然です。Pythonで基本的なグラフを描画するには、ライブラリ「Matplotlib」を使います。
機械学習プロジェクトでは、データセットを深く理解することが重要です。この作業は探索的データ分析(EDA)と呼ばれます。これは、特徴量を選択したり作成したりする特徴量エンジニアリングにも役立ちます。
より高度なグラフの描画には、特徴量間の関係や各特徴量の分布に関する多数のグラフを一度に作成できるpairplot()関数などがあるライブラリ「seaborn」が有用です。
高速な数値計算にはNumPyのndarrayと呼ばれる配列データが適しています。ライブラリは目的に応じて使い分けるのがお勧めです。
データセットは、訓練に使う「訓練セット」と、ハイパーパラメーターのチューニングに使う「検証セット」と、汎化性能を評価するために使う「テストセット」に3分割しましょう。
機械学習の基本的な流れでは、機械学習のアルゴリズムや手法を選択し、モデルを訓練し、訓練済みモデルで予測した結果と正解値を比べて性能を評価します。
ヒント: TableFrame ndimdata 探索的データ分析 pandas 予測 生成 scikit-learn 確認セット 検証セット seaborn Dask Bokeh データマイニング 前処理 ndarray 特徴量エンジニアリング DataFrame 可視化 Matplotlib 汎化性能 データパイプライン ファインチューニング
「機械学習入門」
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。