AWS ToolkitでTomcatクラスタをAmazon EC2上に楽々構築:ユカイ、ツーカイ、カイハツ環境!(12)(3/3 ページ)
Amazon EC2のTomcat Clusterを使いこなす3つのテク
EC2のTomcat Clusterはちょっと試してみる分には問題はありませんが、実際にシステムを運用するうえでは、「ログが各Tomcatインスタンス上に分散される」「セッション情報が利用できない」などの問題があります。
ここでは、以下のTomcat Clusterをさらに使いこなす3つのテクニックを紹介します。
【1】Syslogによるログの集約
Tomcatクラスタ上で動作するWebアプリケーションのログは、ファイルに書き出すと各インスタンス上に保存され、Webアプリケーションのログ解析をする際に各インスタンスのログを確認する必要があります。
特に、haproxyのデフォルトの設定ではstickyセッションが無効のため、リクエストごとに別のインスタンスにログが書き出される可能性があり、解析が大変です。ここで、Syslogとlog4jのSyslogAppenderを利用すると、ログサーバにログを集約できデバッグが楽になります(図10)。
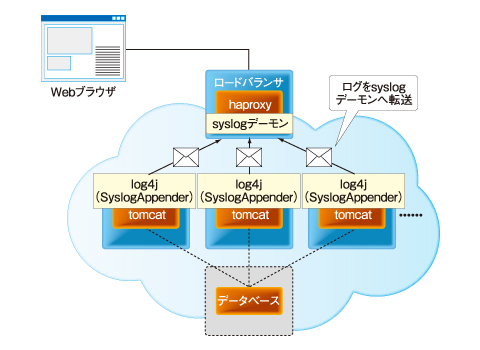 図10 syslogによるログの集約
図10 syslogによるログの集約ここで、ロードバランサをログサーバとして設定して、ログを集約する例を紹介します。EC2のロードバランサでは、「rsyslog」があらかじめインストールされているので、ここではrsyslogを利用した設定例を紹介します。syslogやSyslogAppenderの詳細については、下記のサイトをご覧ください。
最初に、アプリケーションのログを出力するファシリティ(ログの種別)を定義します。ここでは、ファシリティ「local0」にアプリケーションのログを出力するように設定します。設定するには、「/etc/rsyslog.conf」に下記の1行を追加します。
local0.* /var/log/application.log
log4jでは、デフォルトでUDPのsyslogへのログ出力をサポートしているため、UDPによるログの受付を有効にします。rsyslogでUDPのログの受付を有効にするには、「/etc/sysconfig/rsyslog」ファイルの「SYSLOGD_OPTIONS」に「-r514」(514番のUDPポートでログの受付を許可する設定)を追加します。
SYSLOGD_OPTIONS="-m 0 -r514"
設定した後、下記のコマンドによりrsyslogdを再起動すると、ログの受付の準備は完了です。
# /etc/init.d/rsyslog restart
Webアプリケーション側では、log4jの設定でSyslogAppenderを利用する設定を行います。SyslogAppenderを利用したログ出力の設定例をリスト3に示します。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="syslog" class="org.apache.log4j.net.SyslogAppender">
<param name="SyslogHost" value="ec2-75-101-219-128.compute-1.amazonaws.com:514" />
<param name="Facility" value="local0" />
<param name="FacilityPrinting" value="true" />
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern"
value="%d %-5p [%t] %C{2} (%F:%L) - %m%n"/>
</layout>
</appender>
<root>
<priority value ="debug" />
<appender-ref ref="syslog" />
</root>
</log4j:configuration>
これで、すべてのWebアプリケーションで出力したログがログサーバ上の「/var/log/application.log」に集約されます。
【2】プロキシサーバの設定のカスタマイズ
デフォルトでは、haproxyの設定は8080番ポートとなっており、同一のWebブラウザからアクセスするアプリケーションサーバを固定するstickyセッションもサポートされません。ロードバランサのインスタンスのhaproxyの設定を変更することにより、HTTPのポートを一般的な80番に変更したり、stickyセッションを有効にすることによりアプリケーション内でセッションを利用できるようになります。
haproxyの設定を変更するには、ロードバランサのインスタンスにログインして、「/etc/haproxy.cfg」を下記のように書き換えます。
……
listen proxy
bind :8080
balance roundrobin
server s1 ip-10-243-118-79.ec2.internal:8080
……
……
listen proxy
bind :80
appsession JSESSIONID len 32 timeout 3600000
balance roundrobin
server s1 ip-10-243-118-79.ec2.internal:8080
……
haproxy.cfgの値を書き換えたら、起動しているhaproxyを停止し、下記の要領でhaproxyを再起動します。
[root@ip-10-244-131-230 ~]# ps axlww F UID PID PPID PRI NI VSZ RSS WCHAN STAT TTY TIME COMMAND …… 1 99 440 1 15 0 2288 740 - Ss ? 0:00 /env/haproxy/haproxy -D -f /etc/haproxy.cfg -p /var/run/haproxy.pid -sf …… [root@ip-10-244-131-230 ~]# kill 440 (haproxyプロセスを削除) [root@ip-10-244-131-230 ~]# /env/haproxy/haproxy -D -f /etc/haproxy.cfg -p /var/run/haproxy.pid -sf
haproxyの詳細は、haproxyの公式サイトを参照してください。
【3】TomcatのJDBCStoreによるフェイルオーバ
stickyセッションを有効にしても、アプリケーションサーバが何らかの障害によりダウンすると、セッションの内容はクリアされてしまいます。Tomcatの「JDBCStore」機能を利用すると、セッションの内容をデータベースで永続化でき、障害によりアプリケーションサーバがダウンしたときでも、ほかのサーバで処理を引き継げるようになります。JDBCStoreを利用して、信頼性を向上しましょう。
JDBCStoreは、Tomcatのセッション情報をデータベースを利用して共有します。そのため、データベースが利用できるインスタンスを起動しておき、セッション情報を格納するテーブルを作成する必要があります。
例えば、PostgreSQLを利用した場合は、次のようなSQLを実行して「TOMCAT$SESSIONS」テーブルを作成します。
# CREATE TABLE TOMCAT$SESSIONS ( ID VARCHAR(100) NOT NULL PRIMARY KEY, APP VARCHAR(255), VALID CHAR(1) NOT NULL, MAXINACTIVE INT NOT NULL, LASTACCESS BIGINT NOT NULL, DATA BYTEA );
次に、Eclipse上で[プロジェクト・エクスプローラー]のServerプロジェクトから、ローカル・ホストの「Amazon EC2 Tomcat v6.0 Cluster-config/context.xml」に、データベースを利用してセッションを管理するJDBCStoreの設定を、下記のように追加します。JDBCドライバやconnectionURLは、実際のデータベースの設定に応じて変更してください。
<Manager className="org.apache.catalina.session.PersistentManager"
debug="0" saveOnRestart="true" maxActiveSessions="2048" minIdleSwap="600"
maxIdleBackup="10" distributable="true">
<Store className="org.apache.catalina.session.JDBCStore"
driverName="org.postgresql.Driver"
connectionURL=
"jdbc:postgresql://204.236.208.212:5432/tomcat?user=postgres&password=postgres" />
</Manager>
Tomcat Clusterを起動後、Tomcatが起動している各インスタンスのTomcatの「lib」ディレクトリ(/env/tomcat/lib)にJDBCドライバをインストールしTomcatを再起動すれば、データベースによるセッションの共有が有効になります。
JDBC Storeの設定についての詳細は、「Apache Tomcat Configuration Reference(JDBCStore)」を参照してください。
なお、Tomcatのセッションの同期を取る方法として「SimpleTcpCluster」を利用する方法がありますが、EC2では、SimpleTcpClusterを利用するために必要なマルチキャストを利用できないため、SimpleTcpClusterは利用できません。
Google App Engine for Javaと比較して
AWS Toolkitを利用すると、EC2のサーバの起動・停止ができるだけでなく、WTPを利用した通常のアプリケーションサーバ上でのWebアプリケーションの実行・デプロイと同じようにTomcatクラスタ上でWebアプリケーションをデプロイできます。
最近は、クラウド上でのアプリケーション開発としてクラウドのインフラをあまり意識せずにスケール可能なWebアプリケーションが開発できるGoogle App Engineが注目を浴びていますが、EC2でもAWS Toolkitを利用することにより、PaaSレイヤでのアプリケーション開発ができるようになります。
単にWebアプリケーションを起動するだけなら、AWS Toolkitを利用すればGoogle App Engineに匹敵するほど簡単にアプリケーションを起動できます。しかしながら、データベースを利用したり、本格的にWebアプリケーションを運用しようとすると、Google App Engineに比べると、手間が掛かります。
その分、データベースサーバを選択できたり、Google App Engineのようにファイルアクセスやネットワークアクセスに制限はないので、自由度の高いアプリケーション開発が可能であり、いままでのノウハウを生かしたクラウドアプリケーションを開発できます。もし、Google App Engineの制約に不満のある方は、AWS Toolkitの利用を検討してみる価値はあると思います。
- exe/dmgしか知らない人のためのインストール/パッケージ管理/ビルドの基礎知識
- これでGitも怖くない! GUIでのバージョン管理が無料でできるSourceTreeの7つの特徴とは
- DevOps時代の開発者のためのOSSクラウド運用管理ツール5選まとめ
- GitHubはリアルRPG? そして、ソーシャルコーディングへ
- ついにメジャーバージョンUP! Eclipse 4.2の新機能7選
- いまアツいアジャイルプロジェクト管理ツール9選+Pivotal Tracker入門
- Git管理の神ツール「Gitolite」なら、ここまでできる!
- Java開発者が知らないと損するPaaSクラウド8選
- Eclipse 3.7 Indigo公開、e4、Orion、そしてクラウドへ
- AWSの自由自在なPaaS「Elastic Beanstalk」とは
- Ant使いでもMavenのライブラリ管理ができるIvyとは
- 「Hudson」改め「Jenkins」で始めるCI(継続的インテグレーション)入門
- Bazaarでござ〜る。猿でもできる分散バージョン管理“超”入門
- Review Boardならコードレビューを効率良くできる!
- Team Foundation ServerでJava開発は大丈夫か?
- コード探知機「Sonar」でプロジェクトの深海を探れ!
- 単体テストを“神速”化するQuick JUnitとMockito
- Java EE 6/Tomcat 7/Gitに対応したEclipse 3.6
- AzureのストレージをJavaで扱えるWindowsAzure4j
- 究極の問題解析ツール、逆コンパイラJD-Eclipseとは
- AWS ToolkitでTomcatクラスタをAmazon EC2上に楽々構築
- DB設計の神ツール「ERMaster」なら、ここまでできる
- Webのバグを燃やしまくるFirebugと、そのアドオン7選
- Googlerも使っているIntelliJ IDEAのOSS版を試す
- JUnit/FindBugs/PMDなどを総観できるQALab/Limy
- ブラウザを選ばずWebテストを自動化するSelenium
- Eclipse 3.5 Galileoの「実に面白い」新機能とは
- App Engine/AptanaなどJavaクラウド4つを徹底比較
- Aptanaなら開発環境とクラウドの連携が超お手軽!
- 分散バージョン管理Git/Mercurial/Bazaar徹底比較
- SubversionとTracでファイル管理の“迷宮”から脱出
- Trac Lightningで始めるチケット式開発「電撃」入門
関連記事
- Amazon EC2で大規模サービス、クラウド時代のシステム開発とは(@IT News)
- Google App Engineの3つの「簡単」コンセプトとは
インタビュー特集:Google直伝!(4) - Ubuntuで始めるクラウドコンピューティング
Amazonとユーカリ、コアラが好きなのはどっち? - Amazon S3とAdobe AIRで“クラウドRIA”を作ってみた
クラウドの“クライアント”としてRIAを試す(2) - App Engine/AptanaなどJavaクラウド4つを徹底比較
ユカイ、ツーカイ、カイハツ環境!(5) - 6つの主要クラウドとRIAの現状を総ざらい
クラウドの“クライアント”としてRIAを試す(1) - クラウド活用「雲活」のために押さえるべき39のポイント
安藤幸央のランダウン(50) - Javaはクラウドのプラットフォームになり得るのか
小山博史のJavaを楽しむ(11) - クラウド技術入門
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。