機械学習の基礎の基礎、行列計算に欠かせないNumPyの基本的な使い方:Pythonで始める機械学習入門(3)(1/2 ページ)
最近流行の機械学習/Deep Learningを試してみたいという人のために、Pythonを使った機械学習について主要なライブラリ/ツールの使い方を中心に解説する連載。今回は、科学的計算の基本的パッケージNumPyを使って、配列の基本操作、スライシングとインデクシング、配列を使った簡単な計算の仕方などを紹介。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
プログラミング言語「Python」は機械学習の分野で広く使われており、最近の機械学習/Deep Learningの流行により使う人が増えているかと思います。一方で、「機械学習に興味を持ったので自分でも試してみたいけど、どこから手を付けていいのか」という話もよく聞きます。本連載「Pythonで始める機械学習入門」では、そのような人をターゲットに、Pythonを使った機械学習について主要なライブラリ/ツールの使い方を中心に解説していきます。
連載第1回の「Pythonで機械学習/Deep Learningを始めるなら知っておきたいライブラリ/ツール7選」では、ライブラリ/ツール群の概要を説明しました。前回は、その中でもJupyter Notebookの基本操作と設定について説明しました。
今回から連載第1回で紹介した各種ライブラリを使う具体的なコードを例示していきますが、Jupyter Notebook形式で書いていきます。今回は数値計算の基本になるライブラリ「NumPy/SciPy」についてです。
なお本稿では、Pythonのバージョンは3.x系であるとします。
機械学習では、サンプルごとの特徴量を示す行列(2次元配列)を扱う
通常、機械学習で使われるデータ行列は、各行(横方向)がサンプルを示し、各列(縦方向)がそれぞれの特徴量に対応します。例えば、連載第1回で紹介した「Scikit-learn」でよく使われるサンプルデータに「あやめ(iris)」があります。このデータの上5行だけ取り出すと、次のような中身になっています。
array([[ 5.1, 3.5, 1.4, 0.2],
[ 4.9, 3. , 1.4, 0.2],
[ 4.7, 3.2, 1.3, 0.2],
[ 4.6, 3.1, 1.5, 0.2],
[ 5. , 3.6, 1.4, 0.2]])
これは、あやめの4箇所の寸法を集めたデータです。1つの行はあやめの花1つを示しており、ここでは5つのあやめのデータが並んでいることになります。横に並んだ数字は、4箇所(Sepal(萼片)の長さ、幅、Petal(花弁)の長さ、幅)の寸法を示しています。
一般に機械学習のアルゴリズムを使って予測や分類、クラスタリングなどを行うときには、このような形式の行列(2次元配列)を用意する必要があります。
NumPyとは、SciPyとは
NumPyは科学的計算の基本的パッケージで、計算効率が良い配列、行列計算、フーリエ変換などの機能を提供します。
SciPyは、NumPyの上位に位置するライブラリで、標準的な科学技術計算のツールを提供します。
NumPyもSciPyも非常に高機能なので、本連載では機械学習のための道具という視点に特化して、最低限のデータの処理に役立つ使い方を紹介します。もっと網羅的な説明は本家ドキュメントを参照してください。今回と次回の2回に分けて説明しますが、今回は主にNumPyの配列の操作についてです。
これから示すソースコードは、次のようにNumPyをインポートしているものとします。

NumPyの配列の基本操作
Python本体には「list」という型(以下リスト型)がありますが、配列に相当する型はありません。リスト型は、要素の型が同じでなくてもよく、気軽に要素を追加できるなどの柔軟性で利点がありますが、数値計算をするときの計算速度などの点ではNumPyの配列型の方が良いです。
リスト型から配列を作るnumpy.array
1次元配列はリスト型と似ていますが、全ての要素が同じ型である必要がある点が異なります。1次元配列は、下記In[2]:のように「numpy.array」を使うことで、リスト型から簡単に作れます。

また、1次元配列「a」のi番目の要素にアクセスするにはリストと同様に「a[i]」とします(In[3]:)。ただしPythonでは、インデックスは0から始まるので、要素を順に「0番目」「1番目」と呼ぶことにします。2次元配列の場合の「i行目」「j列目」の呼称も同様です。
なおIn[4]:の「a.shape」は「a」の形状(縦横のサイズ)を表していて、In[5]:の「a.dtype.name」は要素の型の名前を示しています。
等差数列を要素とする配列を作るnumpy.arange
等差数列を要素とする配列を作るには「numpy.arange」を使います。

名前付き引数「dtype」で配列の要素の型を指定する
配列の要素の型は自動的に設定されますが、下記In[11]:のように名前付き引数「dtype」で明示的に指定することもできます。

リストのリストから2次元配列を作る
先ほどの「あやめ」のようなデータを用意するには、In[12]:のようにリストのリストから変換する方法が便利です。リストは要素の追加が容易なので、一度リストのリストを作ってから変換するのはよく行われます。

2次元配列aの要素を取り出すのには「a[i,j]」のようにします(In[13]:)。
csvファイルからの入力を配列に変換する
入力処理をリストのリストで行った後に配列に変換することもよく行われます。次のコードは、csvファイルからの入力を配列に変換します。
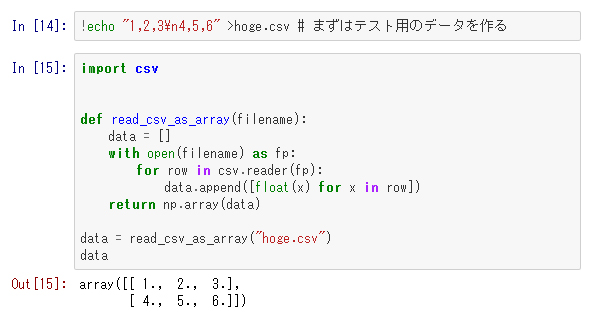
実際にcsvファイルを読み込むのが目的なら、「numpy.genfromtxt」や、連載第1回で紹介した大規模データ処理用のライブラリ「Pandas」を使った方が便利で処理も速いのですが、ここでは一般的な入力処理の例ということで、あえて手動で設定しています。一般には入力が何になるか分からないので、このコード例が役に立つかと思います。
要素が全部0である行列を作るnumpy.zeros、要素が全部1である行列を作るnumpy.ones
あらかじめ決められた値の入った配列が必要なこともよくあります。要素が全部0である行列は、In[16]:のように「numpy.zeros」で、要素が全部1である行列はIn[17]:のように「numpy.ones」で作れます。これらもdtypeで要素の型を指定できます(In[18]:)。

配列の入れ物だけ用意するnumpy.empty
「中身は何でも構わないから、ただ配列の入れ物だけ用意して、要素は後で入れる」という場合、In[19]:のように「numpy.empty」を使います。これは、配列の入れ物を用意するだけで要素への設定は行わないので、配列の要素が何になるかは分かりません。たまたま配列のメモリ領域を確保したときに、そこにあった値がそのまま使われます。
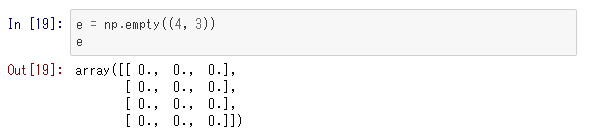
※注:この結果は環境依存なので、必ずしもこうなるとは限りません。
乱数値を要素に持つ配列を作る
初期値設定を行う場合などでは、乱数値を要素に持つ行列やベクトルが必要になることがあるかもしれません。一様乱数が欲しい場合はIn[20]:のように「numpy.random.rand」を、正規乱数が欲しい場合はIn[21]:のように「numpy.random.randn」を使います。

また、シミュレーションの再現性を保証したい場合は、乱数といえども何度実行しても同じ乱数が欲しいことがあります。その場合は、「numpy.random.seed」によって乱数のタネ(シード)を指定します(In[20]:)。
関連記事
 機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
本連載では、さまざまなソフトウェアのインストール、実行するためのセットアップ設定、実行確認、アンインストールの手順を解説する。今回は、Pythonとは何か、Pythonのインストールとアンインストールについて解説。Pythonがよく使われる機械学習やビッグデータ解析を始める参考にしてほしい。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。