ハミング距離(Hamming distance)とは?:AI・機械学習の用語辞典
用語「ハミング距離」について説明。同じ長さの2つの系列(文字列やビット列)を比較して、異なる位置の数をカウントすることで、2系列間の距離(または類似度)を計測する方法。エラーチェックやデータ比較、クラスタリングに利用され、データ間の違いや類似度を直感的に評価できる。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
用語解説
情報理論/機械学習/自然言語処理におけるハミング距離(Hamming distance)とは、同じ長さの2つの系列(文字列やビット列など)間の「異なる位置の数」をカウントすることで、「距離」を計算する方法である。例えば、
- whisper
- whiskey
という2つの文字列間のハミング距離は2である。また、例えば、
- 1111001
- 1001011
というビット列間のハミング距離は3だ。計算方法は、同じ長さの2つの文字列やビット列を比較して、異なる箇所を数えるだけである(図1)。

※ここでの長さn個のビット列は数学的な概念であり、通常は単純に0と1の配列として扱われる。このビット列には、コンピュータのハードウェアやプログラミングなどで見られる上位ビットや下位ビットといった概念は含まれないので注意してほしい。
定義と数式
系列xと系列yのハミング距離を求める数式は、以下のように定義できる。nは「系列(文字列やビット列など)の長さ」とする。
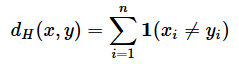
この数式における1(xi ≠ yi)は、条件(xi ≠ yi)が真の場合は1、偽の場合は0を返す関数(指示関数)である。つまり、系列xとyの各位置iにおいて、異なる場合に1をカウントし、合計することでハミング距離を求めている。
使い所と注意点
ハミング距離は、以下のような場面で活用できる。
- エラーチェック: 例えば、データ転送時のエラーを検出して訂正する「ハミング符号」などに利用。
- データ比較: 例えば、同じ長さの2つの文字列やバイナリデータ、遺伝子のDNAシーケンスで類似度を測定するのに使用。
- クラスタリング: 例えば、ビット列データに対するクラスタリングで、距離を計算するのに使用。センサーデータの状態をビット列で表現することで、似た状態をグループ化(=クラスタリング)する場合など。
このようにハミング距離は、幅広い分野で利用されている。ただし、機械学習や自然言語処理、データサイエンスの分野では、必ず学ぶ基礎知識ではあるものの、ハミング距離を利用する機会は少ないかもしれない。現実には、より高度な「レーベンシュタイン距離(編集距離)」(後日解説予定)や「コサイン類似度」などを使うことが多いだろう。
【応用】レーベンシュタイン距離との関係
ハミング距離と同様に、2つの系列(文字列)間の距離を測定する方法にレーベンシュタイン距離(別名:編集距離)がある。ハミング距離は「レーベンシュタイン距離の一種」とも言え、「レーベンシュタイン距離の特殊なケース」として捉えられている。
大きな違いは適用範囲にある。レーベンシュタイン距離が長さの異なる系列(文字列)間にも適用できるのに対し、ハミング距離は同じ長さの系列(文字列)にしか適用できない。さらに、レーベンシュタイン距離は「挿入」「削除」「置換」の3つの操作を考慮して系列を変換するが、ハミング距離は「置換」のみを対象とする。このため、ハミング距離はより制限された状況下で使われるが、特定の用途では簡便に利用できる。
ここを更新しました(2024年9月9日)
2024年9月9日:「【応用】レーベンシュタイン距離との関係」を追記しました。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。