中国の零一万物(01.AI)、コーディング用LLM「Yi-Coder」をオープンソースとして公開:「10B未満のパラメーターで最先端のコーディング性能」
中国のAIスタートアップ零一万物(01.AI)は、コーディング用大規模言語モデル(LLM)「Yi-Coder」をオープンソースとして公開した。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
中国のAIスタートアップ(新興企業)である零一万物(01.AI)は2024年9月5日(中国時間)、コーディング用大規模言語モデル(LLM)「Yi-Coder」をオープンソースとして公開した。
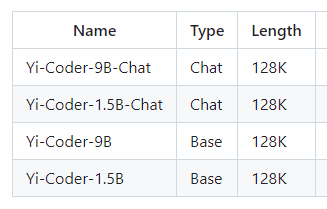
Yi-Coderは、15億(1.5B)パラメーターと90億(9B)パラメーターのモデルがあり、それぞれベース版とチャット版がある。いずれもコンテキストウィンドウは12万8000(128K)トークンとなっている。01.AIは、「100億(10B)未満のパラメーターで最先端のコーディングパフォーマンスを実現する」とうたっている。
 (提供:01.AI)
(提供:01.AI)Yi-Coderは、効率的な推論と柔軟なトレーニングが可能になるように設計されており、特に「Yi-Coder-9B」は、01.AIのオープンソースLLMファミリー「Yi」の一つである「Yi-9B」をベースに、高品質の2.4兆(2.4T)トークンの追加データを用いたトレーニングによって構築されている。このデータは、GitHubのリポジトリレベルのコードコーパスと、CommonCrawlからフィルタリングされたコード関連データから厳密に調達されている。
Yi-Coderの主な特徴は以下の通り。
- Java、Python、JavaScript、C++など、52の主要なプログラミング言語をカバーする高品質の2.4Tトークンでの継続的な事前トレーニング
- ロングコンテキストのモデリング:最大128Kトークンのコンテキストウィンドウにより、プロジェクトレベルでのコードの理解と生成が可能
- 小規模でも強力:Yi-Coder-9Bのパフォーマンスは、パラメーターが10B未満の他モデル(CodeQwen1.5 7B、CodeGeex4 9Bなど)を上回り、DeepSeek-Coder(DS-Coder)33Bに匹敵する
01.AIは、Yi-Coderを発表したブログ記事で、Yi-Coderがコード生成や推論、コードの編集、補完、ロングコンテキストのモデリング、数学的推論に関するベンチマークテストで、優れた成績を収めたことを以下のように紹介している。
コーディング:LiveCodeBench
LiveCodeBenchは、LLMのプログラミング能力の包括的で公平な評価を目的としたプラットフォームだ。LeetCode、AtCoder、CodeForcesといった他のプラットフォームからリアルタイムで新しい問題を収集し、動的かつ包括的なベンチマークライブラリを形成する。
01.AIは、Yi-Coderのトレーニングデータのカットオフが2023年末だったため、2024年1〜9月までの問題を選択し、テストに使用した。

コード生成と推論:HumanEval、MBPP、CRUXEval-O
HumanEval、MBPP、CRUXEval-Oといった一般的なベンチマークにより、Yi-Coderの基本的なコード生成能力と推論能力を評価した。

コード編集:CodeEditorBench
Yi-Coderのコード編集タスクにおける能力を評価するために、デバッグ、多言語への変換、要件変更、最適化という4つの主要分野をカバーするCodeEditorBenchを利用した。

コード補完:CrossCodeEval
PythonコードとJavaコードについて、関連コンテキストを取得する(W/retrieval)、取得しない(W/o retrieval)という2つのシナリオで、CrossCodeEvalによってコード補完能力を評価した。


ロングコンテキストのモデリング:コード内の針
Yi-Coderのロングコンテキストモデリング能力をテストするために、「コード内の針」という合成タスクを作成し、128Kの長いシーケンスを使用した。
このタスクでは、カスタマイズされたシンプルな関数を長いコードベースにランダムに挿入し、モデルがその関数をコードベースの末尾で再現できるかどうかをテストした。
このテストの目的は、モデルがロングコンテキストから重要な情報を抽出できるかどうかを評価し、長いシーケンスを理解する基本的な能力を把握することにある。
下図の緑一色の結果は、Yi-Coder-9Bが128Kの長さの範囲内で、このタスクを完璧に完了したことを示している。

プログラムを用いた数学的推論
プログラム支援環境(PAL:プログラム支援言語モデル)の下で、7つの数学的推論ベンチマークでYi-Coderを評価した。各ベンチマークでは、モデルにPythonプログラムを生成させ、そのプログラムを実行して最終的な答えを返すよう求めた。

関連記事
 日本と中国を含むアジア太平洋地域の生成AI支出、2027年までに260億ドルに IDC予測
日本と中国を含むアジア太平洋地域の生成AI支出、2027年までに260億ドルに IDC予測
IDCによると、アジア太平洋地域(日本と中国を含む)では、生成AIの導入がかつてなく急速に進んでいることから、生成AI支出が2027年までに260億ドルに増加し、2022〜2027年の年平均成長率は95.4%に達する見通しだ。 xAI、X上でリアルタイムに情報処理できるLLM「Grok-2」「Grok-2 mini」β版をリリース 性能はGPT-4oに匹敵?
xAI、X上でリアルタイムに情報処理できるLLM「Grok-2」「Grok-2 mini」β版をリリース 性能はGPT-4oに匹敵?
xAIはGrok-2のβ版をリリースした。Grok-2は最先端の推論機能を備えたLLMで、X PremiumまたはPremium+ユーザーは、Xアプリ上で利用できる。 AIコーディングツール導入のメリット、課題、企業の取り組み状況は? GitHub調査
AIコーディングツール導入のメリット、課題、企業の取り組み状況は? GitHub調査
GitHubは、米国、ブラジル、インド、ドイツの企業におけるソフトウェア開発者など2000人を対象に、ソフトウェア開発におけるAIコーディングツールの導入状況や導入のメリット、課題などを調査した結果を発表した。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。