[NumPy超入門]相関係数とヒートマップ、散布図を使ってデータセットをさらに可視化してみよう:Pythonデータ処理入門(1/2 ページ)
2種類のデータの関連の度合いを調べるには相関係数やそれを可視化したヒートマップ、散布図を使ってデータセットの調査をさらに進めていきましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
連載概要
本連載はPythonについての知識を既にある程度は身に付けている方を対象として、Pythonでデータ処理を行う上で必須ともいえるNumPyやpandas、Matplotlibなどの各種ライブラリの基本的な使い方を学んでいくものです。そして、それらの使い方をある程度覚えた上で、それらを活用してデータ処理を行うための第一歩を踏み出すことを目的としています。
前回はCalifornia Housingデータセット(カリフォルニアの住宅価格のデータセット)の中でもMedInc列とMedHouseVal列に着目して、箱ひげ図とヒストグラムを使い、それらを可視化してみました。今回はそれらのデータの間に関連があるかどうかを、相関係数と散布図を使って考えてみましょう。
なお、今回は相関係数の可視化にseabornというライブラリを用います。これはPythonには標準で付属していないので「pip install seaborn」「py -m pip install seaborn」などのコマンドでインストールしておく必要があります。また、前回同様にカリフォルニア州の住宅価格のデータを以下のコードで読み込み、列名を使って各列へアクセスできるように辞書を設定しています。
import numpy as np
import matplotlib.pyplot as plt
data = np.loadtxt('test.csv', delimiter=',', skiprows=1)
with open('test.csv') as f:
header = f.readline()
columns = header.replace('# ', '').strip().split(',')
col = {k: v for v, k in enumerate(columns)}
print(col)
相関係数を求めて可視化する
相関係数とは、ある変数と別の変数との間にどのくらい強い相関関係があるかを示す値のことです(詳しくはリンク先を参照のこと。相関係数にも幾つかの種類がありますが、今回、NumPyが提供しているnumpy.corrcoef関数を使って計算するのは「ピアソンの積率相関係数」といわれているものです)。
今回の話に関していえば変数は各列のデータのことであり、例えば'MedInc'列と'MedHouseVal'列との間に関連があるかどうか(所得が多い人が住んでいる地区の住宅価格は高いかどうかなど)を調べられるということです。2つの変数の間に正の相関があれば(所得の高い人が住んでいる地区では住宅価格が高くなっているのであれば)、その値は1に近づきます。負の相関があれば(所得の高い人が住んでいる人の地区では住宅価格が低くなっているのであれば)、その値は-1に近づきます。関係がなければ、その値は0に近くなります。
以下に相関係数を求めて、可視化するコードを示します。
import seaborn as sns
corrs = np.corrcoef(data, rowvar=False)
sns.heatmap(corrs, cmap=sns.color_palette('Reds', 10), annot=True,
fmt='.2f', xticklabels=columns, yticklabels=columns)
このコードの「corrs = np.corrcoef(data, rowvar=False)」行が相関係数を求めている部分です。次の行ではその結果をヒートマップの形で可視化しています。ヒートマップとは、何らかのデータの値を色分けして表示することで、その値の大小や強弱を分かりやすくしたものです。ここでは、得られた相関係数の大小を色分けして表示することで、各列の相関の強弱が一目で分かるようになっています。以下がその例です。

先ほどのコードでは、住宅価格データセットの全ての列同士の相関を計算してヒートマップに表しています(左上から右下に濃い赤を背景色として「1.00」という値が並んでいますが、これは同じ列同士の相関係数を求めた結果だからです)。この図をざっくりと見ると、'AveRooms'列と'AveBedrms'列には強い相関があることが分かります。これは「部屋数が多くなれば、寝室の数も増える」ことを示しているのでしょう。
また、'MedInc'列と'AveRooms'列にも相関がありそうです。これは「所得が高ければ、多くの部屋がある住宅を購入しやすい」ことを表しているのかもしれません(逆に「多くの部屋を持つ住宅がある地区には、所得の高い人たちが住んでいる」のかもしれません。さらにいえばもっと別の要因で平均所得と寝室数には何らかの相関があるように見えているだけかもしれません。その辺りはここからだけでは分からないでしょう)。
そして何より、'MedInc'列と'MedHouseVal'列の相関係数(右上の「0.69」)を見ると、ここにもそれなりの相関があるように見えます。「所得の高い人たちが住んでいる地区の住宅価格は高い」とか「住宅価格の高い地区に住んでいる人たちの所得は高い」という正の相関があるように見えます(これについても隠れた別の要因でそのように見えているだけかもしれませんが)。実際のデータを散布図に表すことで、正の相関があるかどうかを確認できるのですが、その前に正の相関、負の相関についてもう少し見てみましょう。
以下のコードは、X軸が0から9.8の範囲で(間隔は0.2)、正の相関、無関係、負の相関となるようなY軸の値を計算するものです。np.random.random関数は-1.0から1.0の範囲の数値を得るものでばらつきを出すために付加しています。また、ここではX軸の値と同じ数の値を求めるようにsizeパラメーターに指定をしています。
x = np.arange(0., 10., .2)
size = x.shape[0]
y1 = x * 2 + 2.0 + np.random.random(size=size) # 乱数を付加してばらつきを出す
y2 = x * 0 + 1.0 + np.random.random(size=size)
y3 = x * -1 + 3.0 + np.random.random(size=size)
print(x)
print(y1)
plt.scatter(x, y1)
例えば、これを基にxの値をX軸に、y1の値をY軸に取ると次のようなグラフが得られます。
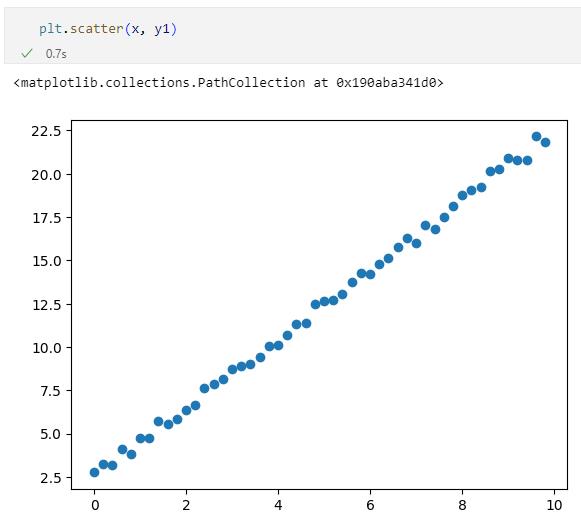 正の相関がある場合のグラフの例
正の相関がある場合のグラフの例見事なくらいに右肩上がりのグラフとなりました。X軸の値とY軸の値に相関がない場合の例が次です。
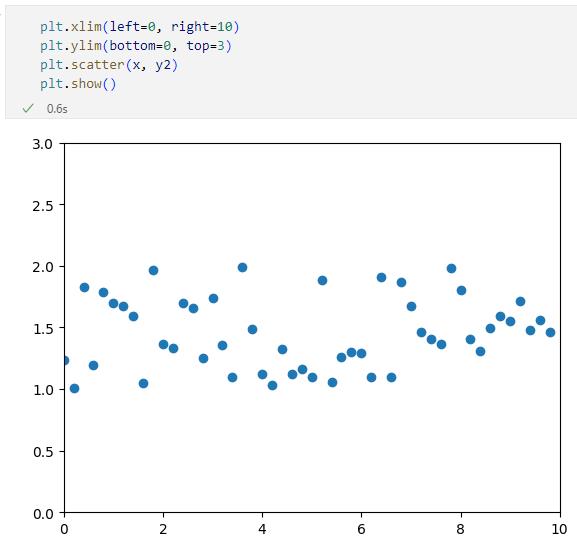 相関がない場合のグラフの例
相関がない場合のグラフの例負の相関があると次のようになります。
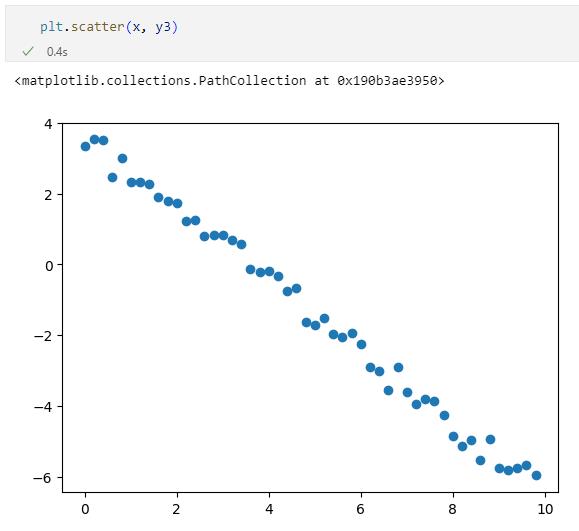 負の相関がある場合のグラフの例
負の相関がある場合のグラフの例これら3組のデータについて以下のコードで相関係数を求めてみましょう。
print(np.corrcoef(x, y1))
print(np.corrcoef(x, y2))
print(np.corrcoef(x, y3))
ここでは2つの一次元配列同士の相関係数を求めていますが、numpy.corrcoef関数にはそれらを個別の行データとして渡しているので、最初に見たnumpy.corrcoef関数呼び出しで指定していたrowvarパラメーターはデフォルト値(True)のままとなっています。これに対して、最初の例では「corrs = np.corrcoef(data, rowvar=False)」のように「rowvar=False」としています。これにより、特定のデータ(説明変数、特徴量。ここでは'MedInc'列など)は列ごとに保存されているので、列同士から相関係数を求めるように指示しているわけです。
結果は次のようになります。
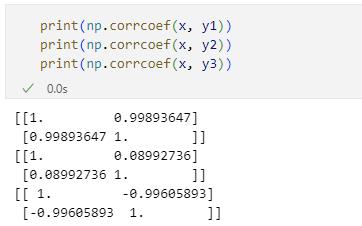 実行結果
実行結果これら3つの配列は、先ほど見たヒートマップと同様に、ただし、今回は2つの行から得た相関係数の一覧です。
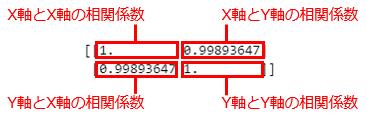 X軸の値とY軸の値の相関係数
X軸の値とY軸の値の相関係数左上から右下に1が並んでいるのは、先ほどと同様に同じデータ同士の相関係数だからです。よって、右上(または左下)の値がX軸の値とY軸の値の相関係数となります。インデックスでいえば、[0, 1]もしくは[1, 0]でアクセスできます。さらにいえば、右上は先頭行の末尾列、左下は末尾行の先頭列でもあるので、[0, -1]や[-1, 0]でもよいでしょう(むしろ、汎用《はんよう》性はこちらの方が高いかもしれません)。というわけで、相関係数を取り出すコードは次のようになります。
print(np.corrcoef(x, y1)[0, 1])
print(np.corrcoef(x, y2)[0, -1])
print(np.corrcoef(x, y3)[-1, 0])
実行結果は以下の通りです。
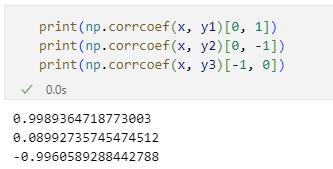 インデックスを用いて相関係数を取り出したところ
インデックスを用いて相関係数を取り出したところこれらの値を見ると、正の相関があれば1に近い値が、相関がなければ0に近い値が、負の相関があれば-1に近い値が得られるというのが実感できるのではないでしょう。
住宅価格データセットの相関係数もヒートマップを使わずに、先ほどと同様なコードで得られます。
corrs = np.corrcoef(data, rowvar=False)
print_op = np.get_printoptions() # これまでの表示設定を取得しておく
np.set_printoptions(precision=4) # 小数点以下の桁数を4桁に設定
print(corrs)
np.set_printoptions(**print_op) # 設定を元に戻す
ここでは第7回で紹介したnumpy.set_printoptions関数を使って小数点以下の精度を4桁にしています。このため、上で見たヒートマップとは少々違う値が表示されますが(小数点以下2桁)、同様の値が得られていることが分かります。

とはいえ、ヒートマップの方がテキストのみの表示よりも見た目に分かりやすいですね。可視化の力は、注目すべき点がすぐに分かることにあるといえるでしょう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。