データ分析もChatGPTの機能(旧Code Interpreter)でできるか、やったみた【番外編】:AI・データサイエンス超入門
ChatGPTの「高度データ分析」機能がデータサイエンスを変える? 素人でも簡単にデータ分析ができるようになるのか? 筆者が実際に挑戦し、実体験に基づく感想と洞察をお届けします。連載の流れとは関係がない番外編です。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
『AI・データサイエンス超入門』という名前の本連載では、「専門家ではない、つまりAIエンジニアやデータサイエンティストではない、全く素人の一般的な社会人でも、新卒の社会人一年生からでも学び始められる」という読者ターゲット設定で、全4回の記事を展開し、既に完結しています。その中の第2回では、最も基本的なデータ分析の流れを手元で体験しました。

だけどこれからの時代、データ分析はChatGPTに“お願い”すれば誰でもできちゃうよね?! 「分析の基礎知識を学び、分析スキルを身に付ける」なんてムダムダムダムダムダ……
そんなふうに思っている人も少なくないのではないでしょうか。ChatGPTに「Code Interpreter」(旧名で、現在は「高度データ分析:Advanced Data Analysis」と改名)という機能が登場した2023年7月当時、データサイエンティストですら「ChatGPTが自動的に行うデータ分析が想像以上の実力だ」と驚き、このまま高度なデータ分析までもが民主化されて「データサイエンティストの仕事が奪われるかも」と危機感を抱く論調も世の中にはありました。
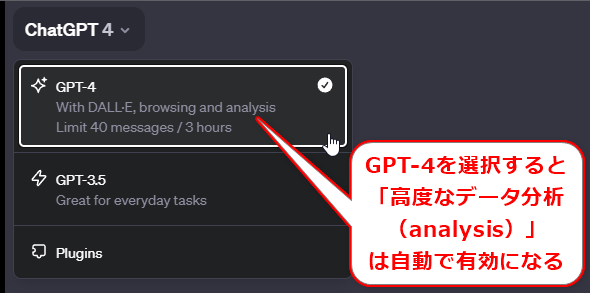 図1 ChatGPTの「高度データ分析」機能の有効化(有料のPlusユーザーが利用できる)
図1 ChatGPTの「高度データ分析」機能の有効化(有料のPlusユーザーが利用できる)2023年12月5日時点では、GPT-4の基本機能として提供されている。あくまで執筆時点での話だ。機能内容は刻々と変わっているので、注意してほしい。
実際にどうなのか? 例えば第2回と同じことが、ChatGPTならチャチャッと素早く完全自動でできてしまうのか? 筆者が試してみたので、その内容や、筆者が思った感想、意見を書いていこうと思います。今回は連載とは直接関係しない【番外編】とし、コラム的な読み物として参考にしていただければ幸いです。
結論から言うと、確かに高度なデータ分析が半自動で実施できます。ですが、筆者の場合、何度も壁にぶつかりました。それを解決するためにも「やはりデータ分析の基礎知識と実践スキルが求められる」と結論付けました。ではどのような壁にぶつかったのか? というのが、本稿の面白いポイントだと思いますので、ぜひ最後まで読んでいただけるとうれしいです。
なお、同じことをChatGPTで試す方もいらっしゃるかもしれません。その際の応答ややりとりは、筆者が体験した内容と異なる場合があることをご了承ください。
1. ChatGPTに「データ分析」をしてもらおう
まずはhttps://chat.openai.com/を開いて、「ChatGPT 4」(GPT-4)を選択します(前掲の図1)。これだけで「高度データ分析」が自動的に使えるようになります。
問題定義と目標設定
準備が整ったので、データ分析をChatGPTにお願いしてみましょう。筆者は第2回の記事内容を参考に、下記のプロンプト(質問テキスト)を入力しました。
プロンプト1
まず前提条件を説明するので、取りあえず話を聞くだけにしてください。なお、今回は「高度データ分析」機能を使用して処理を実行してほしいです。
「気温が低いとアイスクリームが余ってしまい、気温が高いと売り切れが多くなって、ビジネスの機会を逃している」という現場の声があったと仮定します。この問題を解決するために、下記の2つの目標を設定しました。
- 架空のアイスクリーム屋さんの売り上げデータ(100件分)を使って、気温がアイスクリームの売り上げにどのくらい影響するのかを調べる
- 次の日の気温と曜日から、アイスクリームの売り上げ(101件目)を予測する。これによって、「アイスクリームをどれだけ用意すべきか」が事前に把握できるようにする
すると図2のように出力されました。

データ分析の手順
図2の応答は、第2回の「今回のデータ分析の流れ」で示した内容とほぼ同じです。
- ステップ1: 「データの収集と準備」は、第2回記事では「データを収集する」と「データを整理/変換する: 基本的なデータ操作」という2つの手順でした。
- ステップ2: 「探索的データ分析(EDA:Explanatory Data Analysis)」という用語については、本連載では説明していませんでした。EDAとは、いきなり機械学習モデルを作るのではなく、事前にデータの内容をグラフにして可視化するなどして、その特徴をあらかじめ把握しておく作業です。第2回記事では「データを可視化する: グラフ作成」という手順で実施しました。
- ステップ3: 「相関分析」は、相関係数を算出するなどしてデータを分析し考察することです。第2回記事では「データの特徴を把握する: 統計量の確認」という手順でした。
- ステップ4: 「モデルの構築と評価」は、回帰分析などの機械学習モデルを作成し、その性能を評価することです。第2回記事では「データから数値(例えば売上金額)を予測する: 回帰分析」という手順に該当します。
- ステップ5: 「予測と意思決定」は、実際に機械学習モデルで予測し、それを何らかの意思決定に役立てることです。第2回記事では、先ほどと同じ「データから数値を予測する」と「得られた知見をビジネスに生かす: 意思決定」という2つの手順にまたがる内容です。
データ分析のプロセスは、誰が考えてもこうなりますよね。このまま進めて問題ないでしょう。

こういった基礎的な判断には、本連載で学んだ基礎知識が有用ですね。
2. 初っぱなから失敗の連続だった「データアップロード」
先ほどのChatGPTの応答(図2)では、最後に「架空のデータを生成しましょうか?」と聞かれています。データは第2回で使ったものと同じにしたいので、筆者(ユーザー)側からアップロードすることにしましょう。
データの準備(データファイルのアップロード)
データのアップロードは簡単です。第2回の記事からサンプルファイル(analytic_ai.xlsxファイル)をダウンロードし、それをドラッグ&ドロップ操作でChatGPTにアップロードするだけ。アップロード時のプロンプトは次のように書きました。
プロンプト2
架空のデータセットはこちらを使ってください。
まずはデータ分析用にデータの整理や変換を行いたいです。
その前処理として異常値や欠損値を処理してください。
また、カテゴリー値は回帰分析などがしやすい数値データに変換してください。
各処理方法はデータを見てベストなものを自動的に選択してください。
取りあえず前処理までで作業は止めてください。
これですんなりと進む想定だったのですが、結果は図3の通りのエラー!

なぜか英語になっていますが、「アップロードされたファイルへのアクセス」時に何らかのエラーが発生したようです。自動的にもう一度、試行して、それでもエラーになっています。最後に、「前処理の方法をガイドする」という代案を進める許可を求めています。
失敗:アップロード時に発生したエラーの原因究明
しかし、この応答内容では「なぜエラーになったか」という原因が全く分かりません。筆者はここで原因を探ろうとしました。ChatGPTの「高度データ分析」機能は、裏でPythonコードが自動生成されて実行される仕組みです。応答テキストの最後にある[>_](View analysis)というリンクをクリックすると、そのPythonコードが見られます。図4は、2回目の試行エラーのPythonコードの内容です。
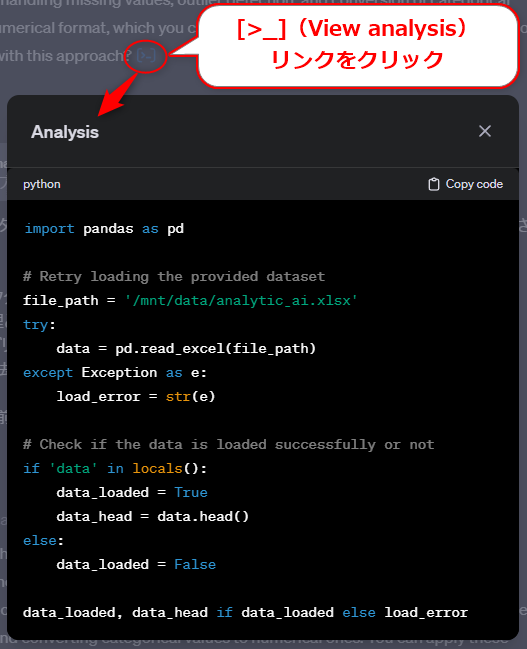 図4 ChatGPTの「高度データ分析」機能のPythonコード表示例
図4 ChatGPTの「高度データ分析」機能のPythonコード表示例Pythonのpandasライブラリーで、Excelファイル(analytic_ai.xlsx)を読み込んでいます。次に、正常に読み込んだかどうかを判別し、成功の場合はそのデータの先頭5行分を表示し、失敗の場合はエラーを表示する処理になっています。

余談ですが、プログラミング未経験の方は、突然のPythonコードで焦った人もいるかもしれません。しかしChatGPTの「高度データ分析」機能を使いこなすには、Pythonコードを読めるレベルの基礎プログラミングスキルは必須になります。でないと、今回のようにエラーが発生したときやおかしな結果が出力されたときに、原因が探れずに手詰まりになるからです。
@ITのDeep Insiderフォーラムでは「AI・データサイエンスの学びをここから」というキャッチコピーで、Python&データ分析の基礎知識と実践スキルをステップ・バイ・ステップで基礎から積み上げるためのコンテンツを用意中です。完結済みの『Python入門』と、連載展開中の『Pythonデータ処理入門』の順で読むことをお勧めします。
2回目の試行もエラーになっているのに、そのエラーの内容は応答に含まれていません。これではエラー問題を解決できないです。ということで、ここから筆者の悪戦苦闘が始まります。というか、データ分析を始める前のここが一番苦労しました。
失敗:問題解決に向けた試行錯誤
最初に気付いたのが、Excelファイルにはワークシートがあり、そのワークシート名をプロンプトで指示していませんでした。「これが原因か」と当たりを付け、再度プロンプトを書きましたが、同じくファイルアクセスのエラーが発生。
ここでもエラーが英語だったので、ここで「エラーメッセージも日本語でお願いします。」とプロンプトを書きました。
次に「エラー内容も出力してください。何が問題なのか判断ができません。」とプロンプトを書いたところ、「ファイルの読み込みに関してエラーが発生しています。エラーの具体的な内容は、内部的な例外 (`AceInternalException`) として報告されており、これは一般的にはシステムの内部的な問題を示しています。」という応答がありました。そこで「ChatGPT AceInternalException」というキーワードでGoogle検索したところ、同様のエラーの報告が幾つかあり、ChatGPT特有の問題だと分かりました(2023年12月5日時点)。いずれ問題は修正されると思いますが、このままでは手詰まりです。
成功:問題の回避
そこで、Excelファイル(具体的にはanalytic_ai.xlsxファイルの[生データ]ワークシート)を、テキストのCSV(カンマ区切り)形式のファイル(UTF-8文字エンコード)のデータに変更してみました。「よりシンプルなファイル形式なら読み込めるのでは?」と期待して。これが成功して、無事に図5のように読み込めました。

ここからは順調に進められそうですね。
3. 楽々と進んだ「前処理」と「データ可視化」と「相関分析」
前処理
先ほどのChatGPTの応答(図5)では、最後に「欠損値の処理、異常値の検出と処理、カテゴリー値の数値変換を行います。それでは、前処理を始めましょうか?」と聞かれています。このまま進めてもらうことにしましょう。そこでプロンプト3のように書きました。
プロンプト3
はい、前処理を実行してください。そこまででまた次のステップについて聞いてください。
その結果、図6の応答が出力されました。

問題はありません。が、第2回記事では「250℃」は「25℃」の書き間違いと推定して、そのように数値を修正しました。これもChatGPTにお願いしてみましょう(入力:プロンプト4、応答:図7)。
プロンプト4
250℃は25℃の可能性が高いので、そのように修正してください。再度、前処理したデータを提示した上で、次のステップについて聞いてください。

全く問題ありませんね。ちなみに念のため筆者は、データ内容全体を第2回記事と比較しましたが、全く同じでした。さらにここで筆者は、Pythonコードを開いて“おかしな処理”などがないかもチェックしましたが、問題はありませんでした。

自動生成されたPythonコードを完全には信用できないので、やはりPythonコードの目視チェックは必須ですよね。だとしたら、最初からPythonコードも表示してくれた方がいい。
Pythonコードも見たい場合は、「Pythonコードも全て表示してください。」という文も最後に付け加えると、表示されるようになります。
ちなみに筆者は、このデータ分析の後半では、常にPythonコードを表示するようにプロンプトに書き加えるようになりました。お勧めです。
データ可視化
さて、先ほどのChatGPTの応答(図7)では、最後に「次のステップとして、このデータに対して探索的データ分析(EDA)を行うことができます。……(中略)……EDAを行うか、それともモデル構築に進みますか、または他にご希望がありますか?」と聞かれています。ここではEDAのためにデータを可視化してもらうことにしましょう(入力:プロンプト5、応答:図8)。
プロンプト5
まずはEDAを行うためにデータを可視化してください。

散布図を第2回記事と比較すると同じです。完璧ですね。どんどん進めましょう。
相関分析
先ほどのChatGPTの応答(図8)では、最後に「次のステップとして、このデータを使用して予測モデルを構築することも考えられます。また、さらなる分析や別のアプローチに関するご要望があれば、お知らせください。」と聞かれています。散布図で「気温(Temperature)と売上金額(Sales)には正の相関関係がありそう」と分かるので、相関係数を算出して数値でも裏付けを取っておきましょう(入力:プロンプト6、応答:図9)。
プロンプト6
予測モデル構築の前に相関分析をして数値的に分析してください。

「気温と売上金額の相関」は0.972と算出されました。これは第2回記事と同じ値です。図9で数値の下にある説明の内容も完璧ですね。
ちなみに、「気温と売上金額」以外の項目同士の相関係数も求めてくれています。「気温と曜日」の相関関係は無意味なので無視します。「曜日と売上金額」は0.778と正の相関が見られますので、回帰分析のデータ項目として使えそうですが、今回は記事が長くなってしまうので説明を割愛します。

ここまでに散布図や箱ひげ図、相関係数など、統計学に基づくデータ分析の手法が出てきました。ChatGPTでデータ分析をするにしても、やはりこれらの知識や活用スキルが求められるということです。知識が不足していると、図の見方や計算値の意味が分からないでしょう。
知識ゼロの状態から「データ分析の基礎的な知識と考え方、実践スキルを身に付けたい」という方は、まずは(展開中の)連載『社会人1年生から学ぶ、やさしいデータ分析【Excel/エクセルで学べる】 』を読破することをお勧めします。
さらに続けましょう。データから売上金額を予測する機械学習モデルを作ってもらいます。
4. 機械学習の知識が試された「回帰分析」
教訓1:ざっくりとした指示はダメ
先ほどのChatGPTの応答(図9)では、最後に「次に、このデータを基に予測モデルの構築を進めますか、それとも他に何か分析を行いますか?」と聞かれています。散布図と相関係数で「気温と売上金額」には強い正の相関があると分かっているので、これをうまく活用して[気温]データから[売上金額]を予測する「回帰分析」の機械学習モデルの構築を指示することにします。とはいえ、もっと適切な手法があるかもしれないので、ここではざっくりとプロンプト7のように指示してみました。
プロンプト7
はい、予測モデルを構築してください。
これにより、図10のように出力されました。Pythonコードが表示されていないので、何をやっているかが分かりづらいですね。Pythonコードを開くと、scikit-learnという機械学習ライブラリーでLinearRegression(線形回帰:回帰分析の一種)クラスを使って回帰分析を実施していました。これは筆者の意図通りです。

しかし機械学習モデルの内容や結果値は、第2回の記事と異なっています。
具体的には、第2回記事では[気温]という1つのデータ項目から[売上金額]を予測する機械学習モデルを作成しましたが、Pythonコードを開くと、[気温]と[曜日]という2つのデータ項目から[売上金額]を予測する機械学習モデルが作られていました。ちなみに1つのデータ項目から数値を予測する回帰分析は「単回帰分析」、2つ以上のデータ項目から数値を予測する回帰分析は「重回帰分析」と呼ばれます。
なお、結果自体は正しいようなので、これはこれで間違いではありません。筆者の想定や意図と異なるだけです。
ざっくりとした指示はやはりダメですね。例えばプロンプト8のように明示的かつ具体的に指示すべきでした。
プロンプト8
[気温]データから[売上金額]を予測する回帰モデルを構築してください。その際のPythonコードも全て表示してください。
教訓2:機械学習の知識も不可欠
さらにプロンプト8で実行しても、機械学習モデルの内容や結果値は、第2回の記事と同じになりませんでした。ここでもChatGPTが実行するPythonコードの内容を見て「どのように処理されているか」を確認しました(図11)。

図11で注目してほしい箇所を赤枠で囲みました。トレーニングセット(訓練用)とテストセット(テスト用)にデータを2分割していますね!!!
確かに機械学習では、データを訓練用/テスト用に2分割し、ハイパーパラメーター(調整可能な設定項目)の調整が必要な場合は訓練用/検証用/テスト用に3分割します。この分割は、機械学習モデルが訓練中だけでなく、実際の運用時にも未知のデータに対して良好な性能(「汎化《はんか》性能」とも呼ばれます)を維持するかどうかを確認するために行われます(これを「ホールドアウト検証」と言います)。
第2回記事では、予想モデルを作って運用することよりも、全データを使ってデータを分析し意思決定することに重きを置いていたため、このようなデータ分割は実施していませんでした。今回のChatGPTと第2回の記事で、その違いが出ているというわけです。

機械学習のことを全く知らない人は、ホールドアウト検証のためのデータ分割や汎化性能などの説明に戸惑ったかもしれませんね。このように、ChatGPTを使ってデータ分析を行う際にも、機械学習の最低限の知識は求められます。
@ITのDeep Insiderフォーラムでは、2024年から『Pythonで学ぶ「機械学習」入門』という連載を本格的に展開していきますので、ぜひ一緒に学んでいきましょう。
単回帰分析
実質的には図11の機械学習モデルで問題ありませんが、第2回の記事と比較できるように、あえて第2回の記事と同じになるように指示します(入力:プロンプト9、応答:図12)。
プロンプト9
テストセットを分割していますが、分けないようにしてください。全てのデータで回帰モデルを作成してください。その場合のPythonコードも全て表示してください。

これで第2回の記事と完全に同じです。
決定係数
第2回記事と同様に、決定係数R2(アール2乗)も求めておきましょう(入力:プロンプト10、応答:図13)。
プロンプト10
この場合の決定係数R^2を計算してください。Pythonコードも表示してください。

決定係数も第2回の記事と一致しました。
* プロンプト10にある「^2」は、数式が表記しやすいTeX/LaTeXの書式に基づく書き方です。この書式だけでも覚えておくと、Google Colaboratoryノートブックなどのテキスト中に例えば$R^2$のような形で数式が書けるので便利です。
散布図への回帰直線の描画
ついでに、前掲の図8で表示された散布図の上に、回帰分析モデルを表す直線である「回帰直線」を引いてみましょう(入力:プロンプト11、応答:図14)。
プロンプト11
先ほどの散布図にこの回帰モデルの直線を引いてください。

回帰直線の図も、第2回の記事と同様の内容になりました。
5. 分析結果から得られる知見をまとめさせて「意思決定」
ということで、データ分析は一通り完了です。
最後に、ここまでのデータ分析からどのようなことが言えるのか。何らかのビジネス上の意思決定につながるように、知見をまとめてもらいましょう(入力:プロンプト12、応答:図15)。
プロンプト12
ここまでのデータ分析で得られた知見はどのようなものでしょうか?
「暑い日はアイスクリームの在庫が足りず、寒い日は在庫が過剰になり、ビジネス上の機会損失があるので改善したい」という課題があります。この課題に対する意思決定に、得られた知見を役立てることは可能でしょうか?

知見のまとめも良いですね。内容は参考になると思います。
ちなみに筆者は、この後でさらにより高い精度の機械学習モデルの構築を模索しました。具体的には、[気温]と[曜日]という2つのデータ項目から[売上金額]を予測する重回帰分析モデルを作成し、3次元の散布図に回帰平面を描くという作業をChatGPTに実施させました。今回はここまででもかなり長い記事になってしまったので、その説明は割愛させていただきます。
本当に、ChatGPTでデータ分析ができてしまいましたね。ただし、全自動で何も知らなくても完璧にできるというわけではなかったです。
Pythonの知識や、データ分析の知識、機械学習の知識といった基礎的なAI&データサイエンスのリテラシーを持ち、自分だけの力でもデータ分析できるという人が、自分で実施予定の作業を効率化/自動化するためにアシスタントAIとして活用する、というのが最も適切なChatGPTの活用法だと筆者は思います。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。