知識ゼロからのビジネスAI活用。議事録AIを作ってみよう:AI・データサイエンス超入門
生成系AIが注目を集める中、従来の画像認識や音声認識のAIも依然として非常に有用です。この記事では、誰でも手軽にできる疑似体験を通じて、会議時の音声を文字起こしをする「議事録AI」の作成を試みます。一緒にAIの世界へ一歩踏み出しましょう!
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
ChatGPTや画像を自動で作り出すAI(人工知能)など、いわゆる生成系AIのニュースが毎日のように流れていますね。2023年の春ごろと比べると、生成系AIの大流行はやや落ち着いてきたように感じますが、それでも「新しいAIのブーム」は始まったばかりだと筆者は考えています。
現在の大ブームの1世代前、具体的には2012年〜2022年までの10年間は、さまざまなAIが流行していました(「第3次AIブーム」と呼ばれています)。動物の写真から猫を見分けるAI(画像認識AI)、音声による「今日の天気は?」といった指示を理解するスマートスピーカー(音声認識AI)、映画の感想コメントが肯定的か否定的かの感情を判別するAI(テキストの感情識別AI)などが特にIT業界とビジネス界で注目されました。本連載ではこれらのAIを識別系AIと呼称して、生成系AIと大まかに区別しています(本連載の第1回で詳しく説明しています)。
新しい生成系AIの大ブームの陰で、従来の識別系AIがもはや忘れられかけているかもしれませんね(笑)。でも、従来のAIも依然として非常に役立ちます。例えばキュウリの等級(長さ、太さ、曲がり具合、色など)を自動選別するAIカメラなどといった画像認識AIは、これからも新規に開発されていくでしょう。生成系AIはこのような目的には向いていませんからね。ですので、AIの世界に触れるなら、1世代前の識別系AIにもぜひ触れて体験してみてください。それが、AIを適切に使いこなすための一歩になるでしょう。
ということで今回は「識別系AI」に焦点を当て、特にこれまで「AIは難しそう」「自分の仕事とは関係ない」と感じていた人に向け、気軽な疑似体験を通して識別系AIの魅力をお伝えします。識別系AIには多種多様な用途が考えられますが、一般的なビジネスシーンで直接役立つ“会議の音声を認識して自動的にテキストにする「議事録AI」”を手軽に作ってみようと思います。ここで使用するのは最先端の音声認識モデル「Whisper」で、高い精度と使いやすさが魅力です。具体的には図1のような識別系AIの作成を体験します。

さっそく「議事録AIを作ってみよう」と進めたいところですが、その前に「AIを作ることには何段階かの難易度レベルが考えられ、簡単に作るためのツールもあるよ」という、知っておくと役立つ前提知識を示しておこうと思います。
連載:

この連載では、人工知能(AI)やデータ分析/データサイエンスをこれまでに学んだことがない社会人(新卒の社会人1年生からベテラン社員まで大歓迎!)に向けて、「データ&AIを活用したいなら、最初に知っておくべき全体概要」、具体的にはAI・データサイエンスの概要と、データ分析(数値予測などの分析系AI)、画像認識などの識別系AI、文章生成などの生成系AIを紹介します。
難しい知識の習得よりもシンプルな経験を重視して、手を動かして体験しながら学べる内容ですので、肩の力を抜いてぜひとも気楽に読み進めてください。
識別系AIを作る/使う際の難易度レベル
本連載は、AI関連の専門知識がない社会人をメインターゲットとしています。知識がゼロでも、今の時代にはAIを作ったり使ったりできます。専門知識を駆使して作るAIから、知識ゼロで使うAIまで、AIを作る/使う際の難易度レベルについて、特に1世代前の「識別系AI」に焦点を当てて説明します。本稿では、識別系AIを作る/使う際の難易度レベルを、簡単〜難しい順に下記の5段階に分けました(図2)。
- (1)一般社会人レベル(誰でも): AIサービスをWebサイト上で使う
- (2)ITエンジニアレベル(初級): AIサービスをAPI(=プログラミング用の操作窓口)経由で使う
- (3)ITエンジニアレベル(中級): 既存のAIモデルをそのまま使う
- (4)AI専門家レベル(初級): 既存のAIモデルをカスタマイズ(調整)して使う
- (5)AI専門家レベル(中級): AIの専門知識を駆使して、ゼロから独自のAIモデルを作る

今回は、(1)の“AIサービスをWebサイト上で使う”方法を体験します。具体的には、音声認識モデル「Whisper」をWebサイト上で使ってみます。
生成系AIの場合
ちなみに、「生成系AI」を作る/使う際の難易度レベルも、識別系AIと同様の5段階に分けられます。しかし、ChatGPTの基盤である大規模言語モデル(LLM)のようなものを「(5)ゼロから作る」のは、識別系AIの場合よりも格段にハードルが高いです。その主な理由は、データ量や計算量などが多いほどAIが賢くなる「スケーリング則」という特性にあります。このため、巨額の資金を投資できる方が有利になり、米国IT企業のMeta社やOpenAI社などが生成系AIの最先端をリードするようになってきています。
生成系AIの場合、大企業や有名大学以外の多くのAI専門家にとって手掛けやすいのは「(4)既存のモデルを調整する」ことでしょう。一方で、一般社会人やITエンジニアにとってWebサイトやAPIを通じて「(1)(2)生成系AIのサービスを使う」のは識別系AIの場合よりも簡単です。そのおかげもあって、仕事やプライベートでAIを使う機会がどんどん増えているのだと思います。
識別系AIの話に戻しましょう。先ほど「(4)既存のAIモデルをカスタマイズして使う」のは「AI専門家レベル(初級)」に相当すると示しました。しかし、このようなAIカスタマイズ作業を含めて、ITエンジニアや一般社会人でも識別系AIを簡単に試せるツールが出てきています。皆さんが手軽に試して学べるように、代表的なツールを紹介しておきます。
誰でも簡単に使える識別系AI作成ツール
識別系AIが解決する主要なタスク(問題)には、画像認識や音声認識などが挙げられます(第1回で説明)。これらに対応したツールとして、誰でも簡単に使える「Webサイト/アプリ」を軽く紹介しておきます。
以下がお勧めのWebサイト/アプリです。いずれも専門知識やプログラミング/コーディング(コードを書くこと)は不要で、画面上でのマウス操作とテキスト入力だけで手軽に試せます。直感的に操作できるので、基本的に操作説明は不要でしょう。
- 画像認識&音声認識: GoogleのTeachable Machine(ティーチャブル・マシーン)
- 画像認識: MicrosoftのLobe(ローブ)
いずれも基本的にWebカメラやマイクが必要になるので、それらが内蔵されているノートPCを使うとよいでしょう。デスクトップPCを使用する場合も、リモート会議用にWebカメラとマイクを接続しているケースが多いため、利用環境は整いやすいと思います。
画像認識&音声認識: Teachable Machine
特にお勧めしたいのがTeachable Machineで、ブラウザから誰でも簡単に使えるWebサイトです。下記の3種類のプロジェクトを提供しており、画面も日本語に対応しています。
- 画像プロジェクト: 新たな画像データ(例:犬の画像)を学習させることで、既存のAIモデルをカスタマイズする。例えば犬を画像認識できるAIが作れる
- 音声プロジェクト: 新たな音声データ(例:「おはよう」と「おやすみ」の音声)を学習させることで、既存のAIモデルをカスタマイズする。例えば「おはよう」と「おやすみ」を音声認識できるAIが作れる
- ポーズプロジェクト: 新たな画像データ(例:グリコのポーズ)を学習させることで、既存のAIモデルをカスタマイズする。例えばグリコのポーズを画像認識できるAIが作れる
図3の例は音声プロジェクトで、「おはよう」と発言したところ、[出力]の「おはよう」がリアルタイムに64%というメーター表示に変わったところです。[出力]には「バックグラウンド ノイズ」「おはよう」「おやすみ」という3つの分類があり、合計で100%になります。通常は「バックグラウンド ノイズ」がほぼ100%に表示されており、何かをしゃべると「おはよう」や「おやすみ」の%表示が動きます。

画像認識: Lobe
一方のLobeは、WindowsとmacOS向けのデスクトップアプリです。このツールは、新たな画像データを学習させて既存のAIモデルをカスタマイズできます。具体的には、上記の「画像プロジェクト」と同様の画像認識AIを作成することができます。こちらに解説記事がありますので参考にしてください。ただし、画面やヘルプが日本語には対応していないため、英語が読める方がよりスムーズに使えるでしょう。
文章認識(テキスト分析)について
画像&音声認識用の手軽な識別系AI作成ツールを紹介しましたが、「新たなテキストデータを学習させて既存のAIモデルをカスタマイズする」ことに対応した文章認識用の“手軽”な「識別系AI」作成ツールは存在しないかもしれません(少なくとも筆者は知りません)。よってTeachable Machineなどと同格のツールを紹介できませんでしたが、そういったWebサイト/アプリの代わりに、Microsof AzureやAWSといったクラウドプラットフォームが提供するプログラミング用のAPIを使う方法や、「生成系AI」のチャットAI(ChatGPT)などで代用する方法はあります。プログラミング経験者ならAPIの使用をお勧めしますが、本稿はプログラミング未経験の読者もいることを想定して、「APIを使う方法」の説明は割愛します。もう一方の「チャットAIで代用する方法」については、もう少し詳しく説明しておきましょう。
今では、人間が使う日本語文章などを処理する自然言語処理(NLP:Natural Language Processing)の分野は、生成系AIがかなりの部分を担うようになってきています。例えば冒頭で「映画の感想コメントが肯定的か否定的かの感情を判別するAI(テキストの感情識別AI)」という例を挙げましたが、これはChatGPTでも代用できます。試しに「主演俳優のアクションがかっこよかった。」という映画の感想コメントがあったとして、ChatGPTに「この感想は肯定的ですか? 否定的ですか? %で答えてください。」と書いて質問するだけで、「肯定的なコメントとして解釈される場合が多いです。具体的なパーセンテージで表すのは主観的な要素も含まれるため難しいですが、一般的には90%以上肯定的と見られるでしょう。」というような返答が得られます。このようにチャットAIに質問するだけなら、誰でも非常に簡単に「文章認識(テキスト分析)」を試せますね。
上記の感情識別タスクだけではなく、ChatGPTなどの生成系AIは大半の自然言語処理のタスクで代用できると考えられます。自然言語処理のタスクには多様なものがありますが、その一つに、製品名などの固有表現を抽出する「固有表現抽出(NER:Named Entity Recognition)」というタスクがあります。多様なタスクで代用できる例として、その固有表現抽出タスクでの代用例も示しておきましょう。試しにChatGPTに「以下の文章から製品名だけを抽出してください。」という指示と「プログラミングにはVisual Studio Codeが便利です。」という製品名を含む文章を入力するだけで、「製品名:Visual Studio Code」という返答が得られます。確かに固有表現を抽出できていますね。
ここまでの例で「すごい。チャットAIがあれば十分」と思ったかもしれませんが、実際には十分ではありません。ChatGPTなどの生成系AIは、例えば固有表現抽出など特定のタスクに特化して作られているわけではないため、専門的なタスクに特化して使うには限界があるからです。例えば、上記の感情識別タスクでは正確な%の数値を出力できていません。識別系AIであれば、前述の音声プロジェクトの64%のように明確な数値を出力できます。よって、専門的なタスクに特化して大量に処理できるように自動化したいのでれば、依然として生成系AIではなく識別系AIとして独自のAIモデルを作成する方がお勧めです。
例えば「PDF文書から製品名を抽出する」という専門的なタスクに特化して大量に自動処理するのであれば、チャットAIで代用するのではなく、それ専用の識別系AIモデルを作成することをお勧めします。ちなみに実際に作成するには、Googleが2018年10月に発表した「BERT」という大規模言語モデル(LLM)がありますので、これをカスタマイズ(調整)するなどして活用することが考えられます。BERTは有名でよく使われていますので、書籍も多数あり情報が得やすいのも利点です。ただしBERTを使いこなすには、AI専門家レベルの専門知識とプログラミングスキルが求められますので、本稿が想定する「AI関連の専門知識ゼロの社会人」には向いていません。文章認識で識別系AIを作りたいのであれば、AI専門家に協力を求めたり、本腰を入れて自分で勉強したりする必要があるでしょう。
初めての識別系AI。手軽に体験してみよう
前置きが長くなりましたが、ここからが本題です。本稿では、気軽な疑似体験を通して識別系AIの雰囲気をお伝えします。皆さんが仕事や業務で識別系AIを活用する際の参考になれば幸いです。
ここからは、図4の流れに沿って識別系AIの一つである音声認識AIの作成(厳密にはプログラミング不要で、既存のサービスを利用するだけなので簡単です)を体験していきます。

1. 問題を定義する
仕事で会議は避けて通れないもの。特に「言った」「言わなかった」のトラブルを避けるため、議事録が必須とされている会社も少なくありません。今回は、そうした会社を前提に話を進めていきましょう。
この会社では2つの大きな問題が浮上しています。
- 書記係は、会議中に議事録をリアルタイムで書くのに忙しく、発言するのが難しい
- 議事録は作成されるものの、実際にはあまり活用されず、時間効率(タイパ)が悪い
2. 解決策を考える
これに対する解決策として、以下のような意見が出されました。
- 音声を自動認識してテキスト化する“議事録AI”の開発
- 会議内容のテキストデータを業務知識用データベース(ナレッジベースと呼ばれます)に蓄積していき、後から簡単に“検索&参照”できるようにする
これらのアイデアの実現可能性を検証するために、試作版のAI(試作品は「プロトタイプ」とも呼ばれます)を作成する計画が立てられました。このような検証の工程は、一般に「PoC(Proof of Concept:概念実証)」と呼ばれています。
3. AIの技術や手法を選定する
問題は2つありますので、1つずつ解決していきましょう。今回は1つ目の「議事録AIの開発」に焦点を当てます。2つ目の「議事録の検索機能」は、次回の「生成系AIの体験」の中で説明します。事情を先に説明しておくと、チャットAIに質問する形で生成系AIによる議事録検索ができるようにする予定だからです。
議事録AIを開発するには、音声をテキストに変換する、いわゆる「文字起こし」をする必要がありますね。最近、「Whisper(後述)という音声認識用のAIモデルによる文字起こしの精度が非常に高い」と耳にしました。そこで今回、Whisperを用いて試作版を作成することにしました。
なおOpenAIの“Whisper”とは、音声データを高精度でテキストに変換できる最先端の音声認識用AIモデルです。2022年9月に登場しました。WhisperのAIモデルは誰でもダウンロード可能なので、自社環境で運用できるというメリットがあります。もし自社運用の手間はかけたくないのなら、公式のOpenAIが安価に提供しているWhisperのAPIを利用するのがお勧めです。また、Microsoft Azureというクラウドプラットフォームでも同様のAPIが提供されています。前述の「識別系AIを作る/使う際の難易度レベル」で言えば、Whisperなら「(3)既存のAIモデルをそのまま使う」と「(2)AIサービスをAPI経由で使う」の両方に対応できるということです。
今回は試作版の作成でできるだけ手間をかけずに済ませたいので、ダウンロードでもAPIでもなく、Web上でデモを試してみることにしましょう。これは難易度レベルで言えば、「(1)AIサービスをWebサイト上で使う」に相当しますね。
4. 試作版のAIを作成する: 音声認識AIの検証まで
Whisperデモで音声認識を試す
さっそく、Whisperのデモページ(図5)で音声認識を試してみましょう。
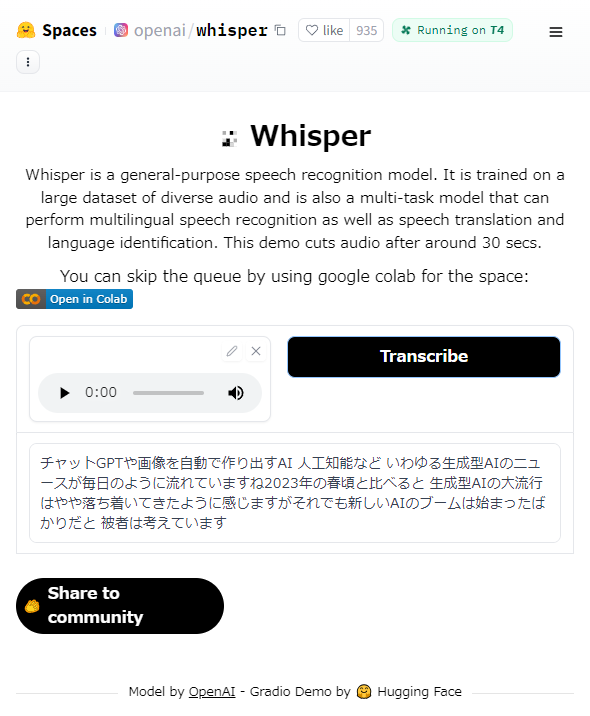 図5 Whisperのデモページで音声認識を試しているところ
図5 Whisperのデモページで音声認識を試しているところ※プログラミング経験者であれば、[Open in Colab](Google Colabという無料で使えるPythonコード実行環境に用意されたColabノートブックが開く)ボタンからColabノートブックに掲載されているコードを実行しても同様のことが試せます。その場合、難易度レベルの「(3)既存のAIモデルをそのまま使う」に相当します。
図5には表示されていませんが、中央左側の部分には[Record from microphone](マイクから録音)ボタンが表示されますので、このボタンを押して何かをしゃべってみてください(※録音は最大30秒まで可能です)。筆者の場合、この記事の冒頭の第1段落を読み上げました。ボタンの表記が[Stop recording](録音を停止)に変わっていますので、これをクリックして録音を完了させてください。
次に、図5の中央右側の部分にある[Transcribe](文字起こし)ボタンをクリックしてください。数秒〜数十秒待つと(※ネットワーク状況によってはもう少し時間がかかる場合もあります)、下部に文字起こし結果のテキストが表示されます。筆者の場合、以下のように文字起こしされました。
チャットGPTや画像を自動で作り出すAI 人工知能など いわゆる生成型AIのニュースが毎日のように流れていますね2023年の春頃と比べると 生成型AIの大流行はやや落ち着いてきたように感じますがそれでも新しいAIのブームは始まったばかりだと 被者は考えています
かなり正確に音声認識されていると思いますが、完璧ではありません。例として、「ChatGPT」が「チャットGPT」になっていたり、「筆者」が「被者」に誤記されていたりします。また、恐らく読み上げ時に息継ぎしたタイミングで間が空いたためか、半角スペースが挿入されていますね。逆に、文末で息継ぎがなかったためか、本来は文が分かれるべき「流れていますね 2023年の春頃」といった箇所には、半角スペースが挿入されておらず一続きになってしまっています。
他には、今回は1人だから問題ありませんが、会議は複数人で行うものなので「誰が話したか」が重要です。つまり、話者を分離する必要があります。
ここで優先的に解決したい課題は、1)句読点の不足と、2)話者の識別です。以下では、これらについて検討しましょう。
課題 1)句読点の不足
音声認識では、句読点が挿入されない問題はよくあります。この問題をChatGPTで解決しているのを筆者は見たことがあります(参考:「Whisperで文字起こしをした文章をChatGPTでいい感じにする」)。そこでここでは、次回の「生成系AI」の分野に少し入ってしまいますが、ChatGPTに次のようなプロンプトを入力して書き起こしの文章を修正してもらいましょう。
以下の文章に適切に句読点を入れて、無駄な半角スペースはカットしてください。
チャットGPTや画像を自動で作り出すAI 人工知能など いわゆる生成型AIのニュースが毎日のように流れていますね2023年の春頃と比べると 生成型AIの大流行はやや落ち着いてきたように感じますがそれでも新しいAIのブームは始まったばかりだと 被者は考えています
その結果、次のような応答が得られました。
チャットGPTや画像を自動で作り出すAI、人工知能など、いわゆる生成型AIのニュースが毎日のように流れていますね。2023年の春頃と比べると、生成型AIの大流行はやや落ち着いてきたように感じますが、それでも新しいAIのブームは始まったばかりだと筆者は考えています。
注:「被者」を正しく「筆者」と修正しました。
これはすごいですね。かなり適切に修正されました。「流れていますね。2023年の春頃」と適切に句点(くてん)が挿入され、「感じますが、それでも」と適切に読点(とうてん)が挿入されています。
さらに何も指示せずとも「被者」を「筆者」と正しく修正してくれています。本当にすばらしい。
ということで、「Whisperで音声認識」→「ChatGPTで文章修正」という流れを含めると、効果的な議事録AIが作れそうです。もう一つの課題も見てみましょう。
課題 2)話者の識別
「話者の識別はどうすればよいか」が全く分からなかったので、「OpenAI Whisper 話者分離(speaker diarization)」といったキーワードでGoogle検索を行ってみました。その結果として、OpenAI公式の議論掲示板(参考:「openai/whisper ・ Speaker identification」)や、幾つかの記事(参考:「WhisperとPyannoteを用いた話者分離と音声認識 | Hakky Handbook」や「pyannote.audioを使って誰がいつ話したのかを判定する話者ダイアライゼーションをやってみた | DevelopersIO」)が見つかりました。特にpyannote.audioというPythonライブラリーが、話者分離の解決策として有望そうです。
次にこのライブラリーを活用して実際に話者の分離が適切に行えるかを検証したいですね。ただし、これにはPythonプログラミングのスキルが求められるため、試作版のAIの作成はいったん「ここまで」としましょう。興味がある方は、ぜひ話者分離にもチャレンジしてみてください。
5. 正式版のAIの開発に向けて
今回の試作版で用いた簡易な手段とデモページは、議事録AIの実装方針を素早く探るためでした。通常の業務フローにおいては、このような初期の試作結果を資料にまとめて社内でプレゼンテーションを行い、次のステップに進むかの意思決定を行うとよいでしょう。その後も、最初から完成版は作らず、実用最小限の機能だけを持つ製品(MVP:Minimum Viable Product)を作り、そこから徐々に必要な機能を付け足していくのがお勧めです(この製品開発のマネジメント手法はリーンスタートアップと呼ばれます)。
また、今回は多くの手作業が含まれていましたが、長期的にはこれらのプロセスをソフトウェアとITシステムで自動化することが理想的です。例えば「WhisperのAPIで音声認識」→「pyannote.audioライブラリーで話者分離」→「ChatGPTのAPIで文章修正」といった流れは、Pythonコードで自動化できると思います。このような開発には、プログラミングスキルが必要となります。そのため、ITエンジニアやAI専門家に作業を依頼するか、あるいは自らがプログラミングを学んで実装する必要があるでしょう。
今回は識別系AIの一部を体験してみました。もっと試したいと思った方には、記事中に紹介したTeachable Machineを今度は自分だけで試してみることをお勧めします。
さらに続けて、より詳しく学んでいきたい方は、「5分で分かるディープラーニング」と「機械学習&ディープラーニング入門(概要編)」を一読して、識別系AIの基本技術となるディープラーニングに対する理解を深めておくと役立ちます。ビジネスでの利活用を目指すのであれば、『文系AI人材になる: 統計・プログラム知識は不要』という書籍が参考になります。
次回は生成系AIについて体験していきます。議事録AIが完成したと想定して、「議事録の検索機能」を実現します。次回記事「生成AI入門:議事録を答えるチャットAI(RAGアプリ)を作ってみよう【プログラミング不要】」もお見逃しなく!
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。