[NumPy超入門]多次元配列「ndarray」に触ってみよう:Pythonデータ処理入門
NumPyが提供する最重要な要素といえば多次元配列を表すndarrayオブジェクト。このオブジェクトを作成して、その基本となる特性を見てみよう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
前回はNumPyの概要についてお話をしました。だいたい次のようなことです。
- NumPyには多くの数値データを格納する多次元配列(ndarray)が用意されている
- ベクトル化やブロードキャスト、ユニバーサル関数などの機構を使うことで、多次元配列の操作を簡潔に記述して、それを高速に実行できる
- 基本的な統計関数を用いることで多次元配列に格納されているデータの分析が可能
今回はNumPyのインストール手順を見た後で、一番上の多次元配列を実際に作成して、その基本的な属性などを調べてみます。
NumPyのインストール
NumPyはPython処理系とは別に配布されているパッケージです。そのため、使う前にはPython環境にインストールする必要があります。例えば、python.orgからPython処理系をダウンロードして使用している場合には、NumPyのインストールにはpipコマンドを使用します。以下は仮想環境myenvを作成して、そこにNumPyをインストールするコードの例です(macOS/zsh)。
% python -m venv myenv
% source ./myenv/bin/activate
(myenv) % pip install numpy
Windowsなら以下のようになるでしょう。
> py -m venv myenv
> myenv\Scripts\activate
(myenv) > py -m pip install numpy
conda系統のディストリビューションを使用している場合は、Anaconda Navigatorを使うかconda installコマンドを使って自分が使う仮想環境にNumPyをインストールできます。これについてはNumPyのドキュメント「INSTALLING NUMPY」を参照してください。
インストールをしたら、後はPythonのプログラムコードの中からNumPyを使えるようにするだけです。
import numpy as np
上記のコードはnumpyライブラリを「np」として参照できるようにしています(これは慣用句となっています)。これにより、NumPyが提供する機能を「np」に続けてドット「.」と機能名(クラス名や関数名など)によって使えるようになります。例えば、この後で紹介するndarrayオブジェクトを作成するarray関数は「np.array(引数)」のように記述可能です。ただし本連載では、NumPyが提供する機能をパッケージ名込みで紹介するときには「numpy.array」のように「np」ではなく「numpy」を含めることにします。
ndarrayが得意とするデータの種類
本節のまとめ
- NumPyが提供するnumpy.ndarrayオブジェクトは配列、行列、テンソルなど、さまざまな種類のデータを格納できる
- NumPyのnumpy.ndarrayオブジェクトは事前に定められた形式でデータが格納されている「構造化データ」の扱いが得意
- 1つのndarrayオブジェクトが格納するデータの種類は全て同じ(例:整数値のみを格納する多次元配列、32ビット精度の浮動小数点数値のみを格納する多次元配列など)
先ほどもお話した通り、NumPyで最も重要な要素がnumpy.ndarrayと呼ばれる多次元配列オブジェクトです(以下、「ndarray」と表記します)。「ndarray」の「nd」は「N-dimensional」つまり「N次元」を意味しています。
多次元配列の典型的な例は、数値データを格納したCSVファイルや表計算ソフトのワークシートです(2次元配列、表形式データ)。CSVファイルや表計算ソフトのワークシートのデータは列と行があり、それぞれの列には事前に定められた特定のカテゴリの値が収められ、それぞれの行はそれらをひとまとめにした1件のデータを表します(行と列を逆にした格納方法もあるでしょう)。
例えば、「列Aには身長が、列Bには体重が、列Cには年齢が……」のように各列は特定の種類のデータが格納されるものとして、「行1にはAさんの身長/体重/年齢などのデータが、行2にはBさんの身長/体重/年齢などのデータが…‥」のように各行には全体として1件を構成するデータ(レコード)が格納されるといった具合です。
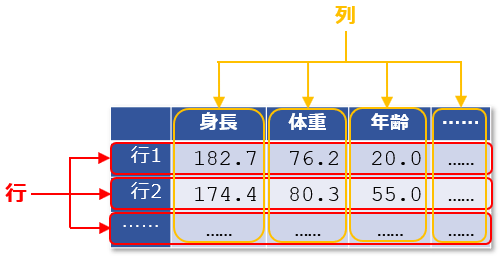 2次元配列
2次元配列このような事前に定められた何らかの規則に従って情報を格納したデータのことを「構造化データ」と呼ぶことがあります。NumPyはこうした構造化データの扱いに長(た)けています。一方、音声データやテキスト、画像データのようなデータのことを非構造化データと呼びます。こちらのデータについていえば、NumPyはそれほど向いているとはいえません。本連載では、基本的に構造化データをNumPyでアレコレしてみながら、その基本的な使い方を学んでいくことを考えています。
なお、上で話した列と行からなる形式のデータは、ndarrayなら2次元の配列(行列、マトリクス)として扱うでしょう。しかし、ndarrayが使えるのはそれだけではありません。1次元のデータ(配列、ベクトル)や、3次元/4次元などのさらに高い次元のデータ(テンソル)を扱うことも可能です。

ここで一つ重要なことがあります。それは1つのnumpy.ndarrayオブジェクト(多次元配列)には同じ型のデータしか格納できないという点です。例えば、整数値を格納するndarrayオブジェクトを作成したとしたら、その配列には浮動小数点数値を格納することはできません(この場合、浮動小数点数値が整数値に型変換されます)。
多次元配列を作成してみよう
本節のまとめ
- ndarrayオブジェクトを作成するにはさまざまな方法がある
- ndarrayオブジェクトの要素を取り出すにはインデックスを使用できる
- ndarrayオブジェクトが格納するデータの型はdtype属性で取得できる
- ndarrayオブジェクトの次元数はndim属性で、各次元の要素数はshape属性で、全要素数はsize属性で取得できる
- ndarrayオブジェクトを作成する関数はたくさんある
難しそうなことをどうこういうよりも、「習うよりも慣れろ」という言葉もありますし、ここで少しNumPyに触りながらndarrayの特徴を見てみましょう。なお、今回紹介するサンプルコードはこちらで公開しています(簡単なコードなので必要ないような気はします)。
numpy.array関数によるndarrayオブジェクトの作成
ndarrayオブジェクトはさまざまな方法で作成できます。簡単なのはNumPyが提供するnumpy.array関数を使うものです(その他の方法については、後ほど簡単に紹介します)。
import numpy as np
a = np.array([0, 1, 2])
print(a) # [0 1 2]
numpy.array関数は引数に指定した配列(ndarrayなど)やPythonに組み込みのシーケンス(リストなど)、スカラー値を基にndarrayオブジェクトを作成するものです。上の例では、Pythonのリストを渡すことで1次元の配列を作成しています。
1次元の配列とは、つまり、その要素が一方向に並んでいる(格納されている)ということです。個別の要素を特定するには何番目の要素であるかを示すインデックスが1つ必要です。ndarrayオブジェクトでは先頭の要素を表すインデックスは0になります。よって、2つ目の要素の値を取得するにはインデックスである「1」を角かっこ「[]」に囲んで指定します。
print(a[1]) # 1
2次元の配列(行列、マトリクス)ならば次のようにして作成できます。
b = np.array([[0, 1, 2], [3, 4, 5]])
print(b)
# 出力結果:
# [[0 1 2]
# [3 4 5]]
今度はnumpy.array関数にリストのリスト(リストを要素とするリスト)を渡しています。外側のリストの第0要素(3つの整数値0、1、2を含むリスト)がndarrayの第0行に、外側のリストの第1要素(3つの整数値3、4、5を含むリスト)がndarrayの第1行になっていることが出力結果から分かりますね。
2次元の配列はその要素が行と列という2つの方向に沿って並んでいます。そのため、何行目の何列目の要素であるか、インデックスを2つ使うことで特定の要素を表せます。以下は第1行の第2列にある要素の値を表示しています。
print(b[1, 2]) # 5
3次元以上の配列(テンソル)でもこれは同様です。
多次元配列が持つ属性
先ほどは「1つのnumpy.ndarrayオブジェクト(多次元配列)には同じ型のデータしか格納できない」と述べましたが、どんな種類のデータが格納されているかは、ndarrayオブジェクトのdtype属性で調べられます。先ほど作成した多次元配列について調べてみたのが以下です。
print(a.dtype) # int32
このコードを実行して表示される「int32」は、上で作成した1次元配列(ベクトル)にはint32型の値が格納されていることを示しています(OSや環境によっては「int64」など、異なる結果になるかもしれません)。整数値0、1、2を要素とするリスト「[0, 1, 2]」をnumpy.array関数に渡していたので、これはある意味、その通りの結果です。別の型の値を配列の要素としようとすると、配列の要素の型へと型変換が行われるか、例外が発生します。
a[0] = 'c' # ValueError
a[0] = 1.6 # OK:浮動小数点数値が整数型に変換される
print(a[0]) # 1
print(a[0].dtype) # int32
「int32」のように最後に数字が付いているのは、この配列には32ビットの整数値が格納されていることを意味しています。Pythonそのものとは異なり、NumPyでは整数型(や浮動小数点数型)についてもそれが扱える数値の範囲に応じてさまざまな種類があります。これはNumPyが内部で使用しているC処理系との兼ね合いでそうなっているものです。
NumPyでは、1つの配列に格納される数値データの型は全て同じものとすることで、配列の要素に対する操作を効率的に行えるようにしています。
次に先ほど見たように、NumPyでは1次元の配列(ベクトル)、2次元の配列(行列、マトリクス)、3次元以上の配列(テンソル)を扱えます。あるndarrayオブジェクトがどんな次元数を持っているのか、その形状(各次元の要素数の組み合わせ)、そのサイズ(全要素数)を調べるにはndarrayオブジェクトのndim属性、shape属性、size属性を使えます。
先ほどは以下のような2次元配列を作成しました。
b = np.array([[0, 1, 2], [3, 4, 5]])
これは2つの配列([0, 1, 2]と[3, 4, 5])を要素とする配列です。
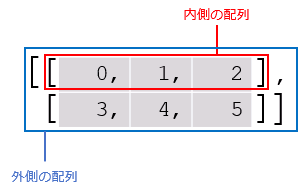 配列を要素とする配列
配列を要素とする配列今述べた3つの属性を使って、この配列の次元数、形状、サイズを調べるコードは次のようになります。
print(b.ndim) # 2
print(b.shape) # (2, 3)
print(b.size) # 6
最初の行はこの配列の次元数をndim属性で調べたものです。配列bは2次元配列なので、その値がそのまま出力されていますね。
次の行はこの配列の形状をshape属性で調べています。形状とは配列の行が幾つで、列が幾つか、(さらに3次元以上の配列であれば各軸の要素数が幾つか)をタプルとして表現しています。作成したのは2行3列の行列だったので、結果は「(2, 3)」です。
最後のsize属性はこの配列の全要素数を表しています。各行が3つのデータを含んでいるので、総数は2×3=6というわけです。
多次元配列を作成する関数たち
今まではnumpy.array関数を使ってndarrayオブジェクト(多次元配列)を作成していましたが、NumPyではndarrayオブジェクトを作成する関数が多数用意されています。以下に幾つか紹介しましょう。
| 関数 | 説明 |
|---|---|
| numpy.array | リストやndarrayなどからndarrayを作成する |
| numpy.arange | 指定した整数範囲の等差数列を要素とするndarrayを作成する |
| numpy.linspace | 指定した実数範囲の等差数列を要素とするndarrayを作成する |
| numpy.zeros | 全ての要素が0.0であるndarrayを作成する |
| numpy.ones | 全ての要素が1.0であるndarrayを作成する |
| numpy.full | 全ての要素が指定した値であるndarrayを作成する |
| numpy.empty | 要素の値が未初期化のndarrayを作成する |
| numpy.identity | 単位行列(対角線上の要素の値が1.0である正方配列)となるndarrayを作成する |
| numpy.eye | 対角線上の要素の値が1.0であるndarrayを作成する(行数と列数が異なっていてもよく、値が1.0となる要素の位置も指定可能) |
| numpy.random.rand | 乱数の値を要素とするndarrayを作成する |
| ndarrayオブジェクトを作成する関数 | |
表の一番上には、ここまでに使ってきたnumpy.array関数があります。以下にこの関数の構文を示します(ここでは主に使うであろうパラメーターだけを示しています。詳細な構文はNumPyのドキュメント「numpy.array」を参照してください)。
numpy.array(object, dtype=None)
パラメーターobjectにはndarrayや、任意のシーケンス(リスト、タプル、ネストしたリストなど)を受け取ります。パラメーターdtypeには作成するndarrayの要素の型を指定します。NumPyで定義されている要素の型としては例えば以下のようなものが指定可能です(その他、Pythonのint、floatなども指定できます)。
| 型 | 別名 | 説明 |
|---|---|---|
| numpy.int8 | numpy.byte | 8ビットの符号付き整数 |
| numpy.int16 | numpy.short | 16ビットの符号付き整数 |
| numpy.int32 | numpy.intc | 32ビットの符号付き整数 |
| numpy.int64 | numpy.int_ | 64ビットの符号付き整数 |
| numpy.uint8 | numpy.ubyte | 8ビットの符号なし整数 |
| numpy.uint16 | numpy.ushort | 16ビットの符号なし整数 |
| numpy.uint32 | numpy.uintc | 32ビットの符号なし整数 |
| numpy.uint64 | numpy.uint | 64ビットの符号なし整数 |
| numpy.float16 | numpy.half | 半精度(16ビット)の浮動小数点数 |
| numpy.float32 | numpy.single | 単精度(32ビット)の浮動小数点数 |
| numpy.float64 | numpy.double/numpy.float_ | 倍精度(64ビット)の浮動小数点数 |
| numpy.float128 | numpy.longdouble/numpy.longfloat | 4倍精度(128ビット)の浮動小数点数 |
| NumPyで定義されているdtype(一部) | ||
64ビット精度の浮動小数点数値を格納するndarrayオブジェクトを作成する例を以下に示します。
c = np.array([0, 1, 2], dtype=np.double)
print(c.dtype) # float64
c = np.array([0, 1, 2], dtype=np.float64)
print(c.dtype) # float64
先ほどの表に掲載した多くの関数では、今見たようなパラメーターdtypeによる要素のデータ型の指定が可能です(numpy.random.rand関数では指定できません)。
というわけで、もう一つ、関数の使い方を見てみましょう。
d = np.arange(10, dtype=np.float64)
print(d) # [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
print(d.dtype) # float64
numpy.arange関数はPythonのrange関数と同様に、スタート値/ストップ値/ステップ値を指定することで等差数列の要素を格納するndarrayを作成するものです。
numpy.arange([start,] stop[, step,] dtype=None)
おおよその動作は次のようになっています。
- ストップ値だけを指定したときには、0からストップ値−1の範囲の値を格納するndarrayが作成される(等差1)
- スタート値とストップ値を指定したときには、スタート値からストップ値−1の範囲の値を格納するndarrayが作成される(等差1)
- スタート値とストップ値とステップ値を指定したときには、スタート値からストップ値−1の範囲でステップ値を等差とする等差数列の値を格納するndarrayが作成される
上の例では「dtype=np.float64」としているので、実際には整数値の等差数列が浮動小数点数値のそれに変換されています。
他の関数にはついては連載のサンプルコード中で、必要に応じて紹介をしていきます。
CSVファイルからデータを読み出す
上で紹介したように、NumPyには配列を作成するための関数が多数用意されています。が、実際にはインターネットやデータベースなどからデータを探してきて、その結果をファイルに保存するなどしてから、NumPyで使いたいということもよくあるはずです。
NumPyでは、numpy.loadtxt関数とnumpy.genfromtxt関数を使って、CSVファイルからデータを読み込めます。
ここではnumpy.loadtxt関数を見てみましょう(numpy.genfromtxt関数については別稿で取り上げます)。
numpy.loadtxt(fname, dtype=<class 'float'>, comments='#', delimiter=None, skiprows=0, usecols=None)
それぞれのパラメーターが意味するところは次のようになっています。
- fname:データを読み込むファイルの名前(ジェネレーター/文字列を要素とするリストも指定可能だが本稿では取り上げない)
- dtype:作成するndarrayの要素のデータ型。省略時はfloatが指定されたものと解釈される
- comments:CSVファイル内でコメントを表すために使われている文字。省略時には'#'が指定されたものと解釈される
- delimiter:CSVファイル内で要素を区切るのに使われている文字。省略時は空白文字が指定されたものとして解釈される
- skiprows:CSVファイルの先頭を何行読み飛ばすかの指定。CSVファイルの先頭には各列の説明となるテキストが含まれていることがあり、それらを読み込まないようにするときに使える。省略時は0が指定されたものとして解釈される(先頭行からデータを読み込む)
- usecols:読み込む列の指定。先頭列が0、次の列が1、……のように0始まりな点に注意。読み込む列を表す値をタプルにまとめて指定する(例:usecols=(1, 2, 4))。省略時は全ての列のデータを読み込む
例えば、次のようなCSVファイルがあったとします。
col0, col1, col2
0, 1, 2
3, 4, 5
6, 7, 8
このCSVファイルの名前が「test.csv」だとして、その内容を読み込むには次のようになります。
csv_value = np.loadtxt('test.csv', skiprows=1, delimiter=',')
csv_value
test.csvファイルの先頭行は「col0, col1, col2」のように各列の説明となるヘッダーです。そのため、これを読み込む必要はありません。読み飛ばすにはパラメーターskiprowsに読み飛ばす行数として「1」を指定すればよいでしょう。また、numpy.loadtxt関数ではデフォルトで空白文字(半角の空白文字やタブ文字)をデータとデータの区切りとして解釈しますが、上記のtest.csvファイルではカンマ「,」が区切り文字となっています。そのため、パラメーターdelimiterに区切り文字がカンマであると指定しています。
上のコード例を実行した結果を以下に示します(Visual Studio Codeを使用)。
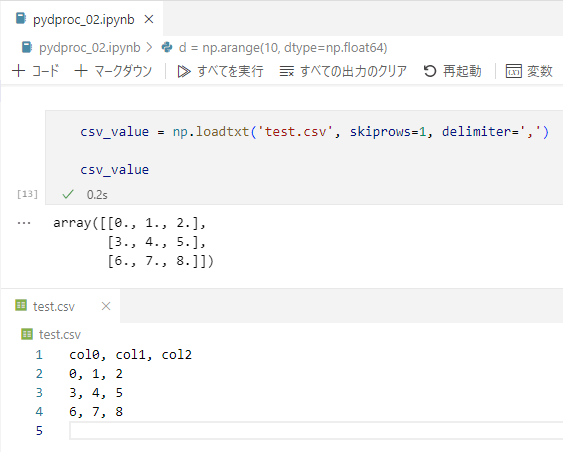 CSVファイルからデータを読み込む
CSVファイルからデータを読み込む最初の列と最後の列のデータだけを読み込みたいのであれば、以下のようにします。
csv_value = np.loadtxt('test.csv', skiprows=1, delimiter=',', usecols=(0, 2))
csv_value
パラメーターusecolsに読み込みたい列を(0始まりで)タプルを使って指定しています(usecols=(0, 2))。これによりtest.csvファイルの最初の列と最後の列からデータが読み込まれるようになります。

もう1つのnumpy.genfromtxt関数については機会があれば取り上げて取り上げることにします。こちらはデータの読み込み時により込み入った制御が行えます。
また、データをCSVファイルに書き込む関数も(もちろん)あります。これらについても別の回で取り上げることにしましょう。
今回はNumPyが提供するndarrayオブジェクトについて駆け足で眺めました。次回はndarrayオブジェクトの操作についてもう少し詳しく見ていくことにしましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。