[pandas超入門]ヒストグラムの描画とビニングを体験してみよう:Pythonデータ処理入門
DataFrameオブジェクトの指定した列のヒストグラムを描画することで、データの分布を視覚的に把握できます。また、年齢層のような考え方を基に、列のデータを一定のグループにまとめる(ビニングする)ことが可能です。その方法を見ていきましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
本シリーズと本連載について
本シリーズ「Pythonデータ処理入門」は、Pythonの基礎をマスターした人を対象に以下のような、Pythonを使ってデータを処理しようというときに便利に使えるツールやライブラリ、フレームワークの使い方の基礎を説明するものです。
- NumPy(「NumPy超入門」の目次はこちら)
- pandas(本連載)
- Matplotlib
なお、本連載では以下のバージョンを使用しています。
- Python 3.12
- pandas 2.2.1
前回は欠損値を含む列の削除や欠損値の補完、不要な列の削除、カテゴリカルデータのエンコーディングなどについて見ました。前回の最後にはDataFrameオブジェクトのスケーリングを行うと述べたのですが、積み残してしまった'Age'列のヒストグラムを作成したり、そのビニングをしたりしてみます(スケーリングは次回に取り上げます)。
取りあえず前回作成したCSVファイルを読み込んでおきましょう。
import pandas as pd
df = pd.read_csv('titanic_cleaned.csv')
'Age'列のヒストグラムを作成してみよう
前回に'Age'列の欠損値について話をする中で「まずは'Age'列のヒストグラムを作成するなどして、データの分布を確認することが重要です」と述べたものの、実際にヒストグラムを作成することはありませんでした。以下では、これを試してみることにしましょう。
ヒストグラムとは、データがどのように分布しているかを視覚的に把握するための手法の一つです。'Age'列であれば、どの年齢層の乗客(と乗組員)のどれくらいの数だけいたかをグラフの形で表せます。この年齢層のように、データを区切る区間のことをビンと呼ぶことがあり、データをビンに分類していくことをビニング(離散化)と呼ぶこともあります(ビニングにも種類がありますが、今回は全てのビンが10歳区切りなど一定の幅を持つものとします。これに対して、データを一定の個数ごとにまとめる手法もありますが、今回は紹介しません)。
ヒストグラムは幾つかの方法で作成できます。ただし、ヒストグラムの作成と描画にはMatplotlibが必要です。インストールしていないときには、ターミナルやコマンドプロンプトで「pip3 install matplotlib」「py -m pip install matplotlib」などのコマンドを実行するか、同様なコマンドに「!」を前置したものをノートブックで実行するなどして、これをインストールしておきましょう。以下はWindows上で動作しているVisual Studio Code(以下、VS Code)で「!py -m pip install matplotlib」を実行したところです(macOSやLinuxなら「!pip3 install matplotlib」などとします)。

Matplotlibをインストールしたら、それをPythonから使えるようにmatplotlib.pyplotモジュールをインポートします(pyplotはMatplotlibに対するPythonのインタフェースです)。
import matplotlib.pyplot as plt
これでヒストグラムを作成、描画するための準備ができました。ここではDataFrame.histメソッドを使って、ヒストグラムを作成してみましょう。
pandas.DataFrame.histメソッド
pandas.DataFrame.hist(column=None, bins=10)
指定した列のヒストグラムを作成、表示する。以下に一部のパラメーターを挙げる。全パラメーターについてはpandasのドキュメント「pandas.DataFrame.hist」を参照のこと。
- column:ヒストグラムを作成する列を指定する。文字列で単一の列を指定するか、列インデックス名を要素とするリストを指定する。指定しなかった場合は全列のヒストグラムが作成される
- bins:指定された列のデータを何個の区間に分けるか(ビン分割、ビニング)を指定する。省略時の値は10。整数値またはスカラー値を要素とするリストを指定可能。整数値を指定したときにはその数の区間(ビン)が作成される(このときには、binsパラメーターの値+1個の境界値が自動的に計算されて使われる)。リストを指定したときには、リストの要素数−1個のビンが作成される
最初は何も指定せずに、histメソッドを呼び出してみます。
hist = df.hist()
これをVS Codeで実行した結果が以下です。

文字が重なるなどしてグラフが見づらいのですが、ここでは置いておきましょう。ここでは'Age'列に注目したいと思います。そこで、そのヒストグラムだけを表示するには以下のようにcolumnパラメーターを指定します。
hist = df.hist(column='Age')
以下がその結果です。

前回に「'Age'列のヒストグラムでは左に偏った分布が見られ、若年層が多いことが分かります」と述べた通り、30代より低い年齢層の乗客(と乗組員)の方が高年齢層の乗客(と乗組員)よりも多いことが分かります。が、惜しいことにX軸の10刻みのグリッドとグラフの幅が一致していないことが気になります。そこで、'Age'列の最大値と最小値を調べてみます。
print(df['Age'].min()) # 0.42
print(df['Age'].max()) # 80.0
binsパラメーターを省略すると、0歳代から80歳までが10個の区間(ビン)に分割されるため、グラフとグリッド線の間でズレが生じていたということですね。そこで、これを8個にビニング(ビン分割)してみましょう。
hist = df.hist(column='Age', bins=8)
すると、結果は次のようになりました。
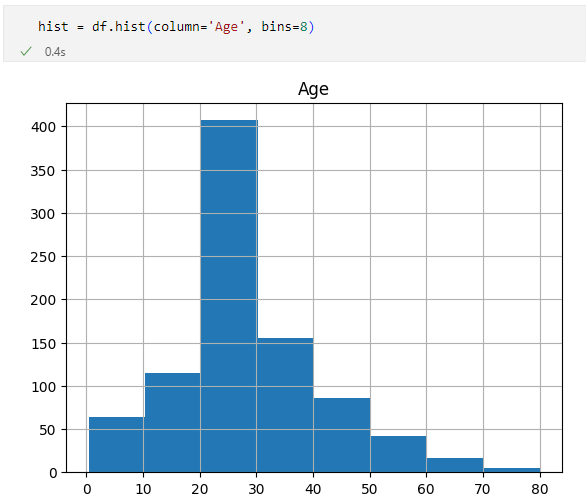 8個にビニングした結果
8個にビニングした結果20歳代が一番多いことが明確に分かりました。視覚的にはこれで十分に分かりやすいのですが、数字としても確認したいと思いませんか。
DataFrameオブジェクトのビニング
上で見たヒストグラムの結果を数字として確認するには、'Age'列をビニングして新たなデータを作成するのがよいでしょう。ヒストグラムをhistメソッドで描画する分には気にしていませんでしたが、ビニング(離散化)にはある列に含まれるデータをひとまとまりのグループにまとめて、そのグループを眺めることで新たな知見を得るというメリットがあります。
PandasでDataFrameオブジェクトのビニングを行うにはpandas.cut関数を使います(データを一定の個数ごとにまとめるpandas.qcut関数もありますがここでは取り上げません)。
pandas.cut関数
pandas.cut(x, bins, labels=None)
xに与えた値をビニングした結果を返す。一部のパラメーターを以下に示す。全パラメーターについてはpandasのドキュメント「pandas.cut」を参照のこと。
- x:ビニングの対象となる配列。一次元(Seriesオブジェクトなど)でなければならない
- bins:ビニングの基準。整数値を与えた場合、ビンの数を意味し、データはその範囲内で等分割される。スカラー値を要素とするリスト(シーケンス)は各ビンに格納される値の境界を指定する
- labels:ビニングの結果に付加するラベルの指定。Falseを指定すると、どのビンに含まれるかを意味する整数値がラベルとなる
これを使って、'Age'列をビニングしてみます。
tmp = pd.cut(df['Age'], bins=8)
tmp
結果を以下に示します。

出力を見ると、これがSeriesオブジェクトであることが分かります。その値は「(20.315, 30.263]」などのようになっています。「(a, b]」というのは'Age'列で対応する行の値をxとすると「a < x <= b」の範囲に含まれることを意味しています(このような区間のことを半開区間と呼びます)。「(20.315, 30.263]」であれば、「20.315 < その行の値 <= 30.263」の範囲に含まれるということです。概要を知ることが目的なので、これで十分という人もいるでしょうが、境界はきっちりとしたいというのであれば、binsパラメーターにそれらを指定します。
tmp = pd.cut(df['Age'], bins=[0, 10, 20, 30, 40, 50, 60, 70, 80])
tmp
すると、結果は次のようになりました。

出力の最下行を見ると、「(0, 10] < (10, 20] < (20, 30]……」のように境界値がスッキリしたことが分かります(筆者の気持ちも少しスッキリしました)。
この結果を元のDataFrameオブジェクトに結合させれば、'Age'列をビニングした情報を含ませられるでしょう。ただし、pandas.cut関数が戻したのは「(0, 10]」「(10, 20]」のように数値データにはなっていないので(カテゴリカルデータ)、機械的な処理が面倒です。このようなときにはlabelsパラメーターにFalseを指定することで、返されるラベルを整数値にできます。
tmp = pd.cut(df['Age'], bins=[0, 10, 20, 30, 40, 50, 60, 70, 80], labels=False)
tmp
実行結果を以下に示します。

これを元のDataFrameオブジェクトに新しい列として結合すればよいでしょう。以下では'BinnedAge'列としています(これに伴い、'Age'列のデータは削除することも考えられますが、ここでは取りあえずそのままにしておきます)。
df['BinnedAge'] = tmp
df
'BinnedAge'列はその値が0であれば0歳から10歳を、1であれば10歳から20歳を、……というように年齢層を示しています(ただし、最小値は範囲に含みません。

上で見たように、'Age'列の最小値は0.42だったので、実質的には問題にはならないでしょう)。そこで、この列の値がどのような分布になっているかを数字で確認してみます(これがビニングの目的でした)。
df['BinnedAge'].value_counts()
この結果は次の通りです。
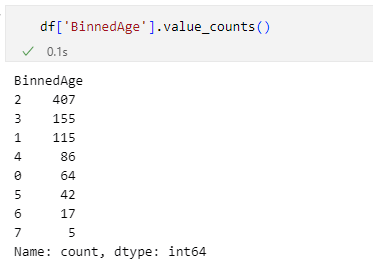 20歳代、30歳代、10歳代が多いことが数字でも確認できる
20歳代、30歳代、10歳代が多いことが数字でも確認できる20歳代、30歳代、10歳代の順に乗客(と乗組員の)数が多いことが分かりました。
ここで、DataFrame.histメソッドでのヒストグラム描画についても上と同様に境界値を明確に指定するとどうなるでしょうか。比較用にbinsパラメーターに8を指定したときのヒストグラムを以下に示します。
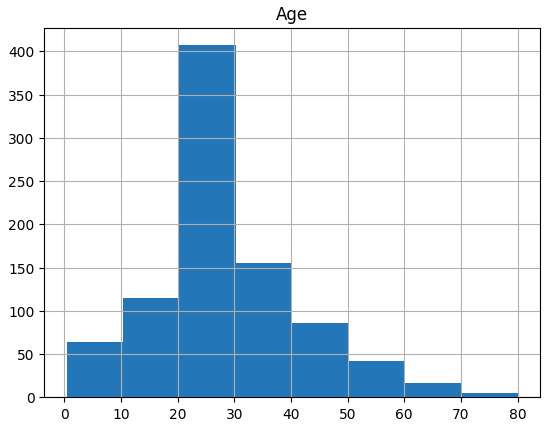 binsパラメーターに8を指定したときのヒストグラム
binsパラメーターに8を指定したときのヒストグラムでは、binsパラメーターに0から80までの9個の整数値を要素とするリストを渡してみましょう。
hist = df.hist(column='Age', bins=[0, 10, 20, 30, 40, 50, 60, 70, 80])
すると、ヒストグラムは次のようになりました。
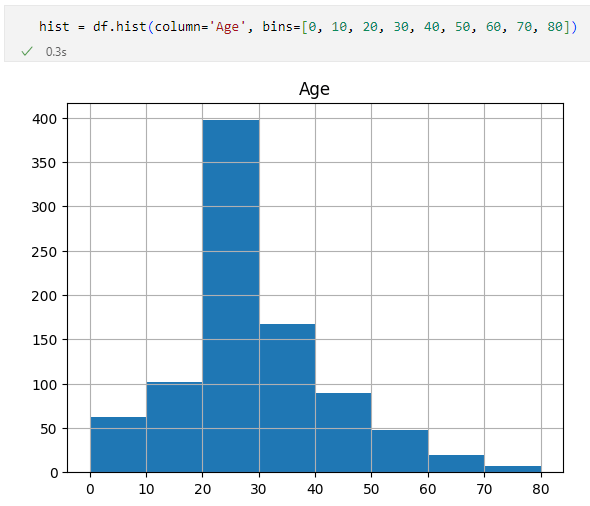 binsパラメーターにリストを渡したときのヒストグラム
binsパラメーターにリストを渡したときのヒストグラム同じように見えるといえば見えますが、20歳代のバーに着目すると先ほどのヒストグラムは400を超えているのに対して、今度のヒストグラムは400をわずかに下回っているようです(他にも細かな差があります)。筆者として同じものが出てきて「よかったよかった」と終わるつもりだったのですが、何が起こっているのでしょうか……。以下は完全に余談です。
少し調べてみたところ、pandas.cut関数ではbinsにリスト(シーケンス)を指定した場合、デフォルトでは、それぞれの区間(ビン)の最小値はその範囲には含まれず、最大値はその範囲に含まれるような半開区間となります。簡単な例を出すとbinsパラメーターに[1, 2, 3, 4]を渡すと、(1, 2]、(2, 3]、(3, 4]という3つのビンが作成されるということです(「(」はその値が範囲に含まれないことを、「]」はその値が範囲に含まれることを意味します)。
これに対して、ここでヒストグラムの描画に使用しているMatplotlibのmatplotlib.pyplot.hist関数のドキュメントによれば、binsパラメーターにリストを渡した場合、それは最後のビンを除いて、半開区間になります。ただし、半開区間になるのは同じなのですが、その開閉が逆なのです。先ほどと同じ例を出すと、binsパラメーターに[1, 2, 3, 4]を渡すと、[1, 2)、[2, 3)、[3, 4]というビンが作成されるということです。
このことが上で見たヒストグラムの微妙な違いを生んでいるのだと思われます。
ちなみにpandas.cut関数ではrightパラメーターにFalseを指定すると半開区間の開閉を逆転できます。これを使ってビニングを行い、そのヒストグラムを作成すれば、その結果はDataFrame.histメソッド(の最終的な行先と思われるmatplotlib.pyplot.hist関数)のbinsパラメーターにリストを渡したときと同様になることが期待できます。実際に、以下のコードで試してみましょう(binsパラメーターに渡すリストで90という要素を追加しているのは、境界値の上限である80に対応する行が、pandas.cut関数が返すSeriesオブジェクトから落とされているようだったからです。90をリストに追加することで、[80, 90)という半開区間に対応するビンを追加したことになります)。
tmp = pd.cut(df['Age'], bins=[0, 10, 20, 30, 40, 50, 60, 70, 80, 90],
labels=False, right=False)
hist = tmp.hist(bins=8)
これを実行すると、次のようなヒストグラムが得られました。

20歳代のバーが400を少し割り込み、他のバーも先ほどの例からは少し変動しています(30歳代のバーが少し高くなるなど)。ちなみに開閉を逆にしてビニングした結果、各列の個数は次のようになりました。
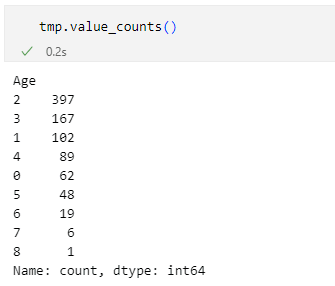 開閉を逆にしたときの年齢層の分布
開閉を逆にしたときの年齢層の分布単純にbinsパラメーターに8を指定したときのヒストグラムとなぜ似たようになるのかについての検討などが足りていないような気もしますが、これ以上続けても得られるものもないでしょうから、この辺で終わりにしておきましょう。
plotメソッドによる'Age'列のヒストグラムの描画
'Age'列のヒストグラムを描画するには、plotメソッドも使えます。plotメソッドはさまざまな種類のグラフを描画するのに使えますが、そのcolumnパラメーターにヒストグラムの作成対象となる列を指定して、kindパラメーターに'hist'を指定するだけです(メソッドの紹介は省略します)。
hist = df.plot(column='Age', kind='hist', bins=[0, 10, 20, 30, 40, 50, 60, 70, 80])
実行結果を以下に示します。

グリッド線が表示されていないこと、Y軸のラベルとして「Frequency」と表示されていること、グラフのタイトルではなく反例として「Age」が表示されていることなど、細かな点は異なりますがおおよそ同じヒストグラムが得られました。グリッド線を表示するにはgridパラメーターにTrueを指定してください。以下はその例です(コードは省略)。

また、DataFrameオブジェクトに角かっこ「[]」で列を指定してplotメソッドを呼び出してもヒストグラムを描画可能です。以下に例を示します(コードは省略)。

今回は'Age'列のヒストグラムを幾つかの方法で描画して、ビニングを行ってみました。次回はデータのスケーリングについて見ていきます。
というわけで、今回の結果についてもCSVファイルに保存しておきます。
df.to_csv('titanic_binned.csv', index=False)
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。