[評価関数]平均絶対パーセント誤差(MAPE:Mean Absolute Percentage Error)とは?:AI・機械学習の用語辞典
用語「平均絶対パーセント誤差」について説明。評価関数の一つで、各データに対して「予測値と正解値との差を、正解値で割った値(=パーセント誤差)」の絶対値を計算し、その総和をデータ数で割った値(=平均値)を表す。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
用語解説「MAPE」
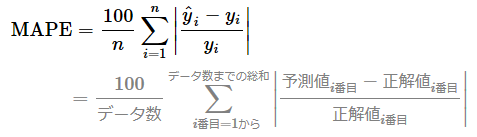
機械学習における平均絶対パーセント誤差(MAPE:Mean Absolute Percentage Error)とは、各データに対して「予測値と正解値との差を、正解値で割った値(=パーセント誤差)」の絶対値を計算し、その総和をデータ数で割った値(=平均値)を出力する関数である。(図1)。100%の確率値にするため、一般的には最後に100を掛ける(もちろん掛けなくてもよい)。なお誤差は、「予測値−正解値」ではなく「正解値−予測値」でもよい。

定義と数式
「パーセント誤差の絶対値」がイメージしやすいように、簡単なデータで手計算してみよう(図2)。
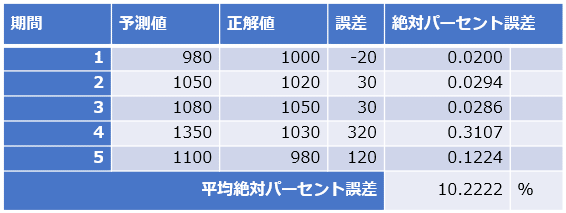 図2 平均絶対パーセント誤差(MAPE)の計算例
図2 平均絶対パーセント誤差(MAPE)の計算例図2のデータでは5個(例えば1時〜5時)の期間からなる時系列データがあり、予測値−正解値で「誤差」を計算し、|誤差÷正解値|の絶対値で「絶対パーセント誤差」を計算している。5個の計算結果を平均し、最後に100%確率値にするため100を掛けて、最終的に10.2222%という平均絶対パーセント誤差(MAPE)が計算されている。「平均して約10%前後の誤差がある」という意味になる。
用途
MAPEは、主に時系列予測や回帰問題において、モデルの予測性能を評価するための評価関数として用いられる。例えば一般のビジネスマンに向けて誤差をパーセント(確率値)で分かりやすく伝えたいときなどで役立つだろう。0に近いほどより良い。なお、数値そのものではなくパーセントという比率を評価する関数であるので、最適化を行うための損失関数としては基本的に使われない。
利点は、相対誤差であることだ。MAEやRMSEなどは絶対誤差であるため、スケール(数値の桁数)が異なる状況での評価には使いづらい。相対誤差では、ズレではなく比率(パーセント)で誤差を評価できるため、スケールが異なるデータの予測(時系列予測など)に対応できる。例えばコンビニの販売数量の予測では、店舗ごとにスケールが違う可能性があるが、そんな場合にも「この機械学習モデルの出力結果は、30%前後の誤差がある」といった形で評価できる。一方で、気温の予測のようにどこでもスケールが変わらない時系列予測の場合は、MAEやRMSEの方が適切である。
欠点は、正解値に0がある場合は割り算ができずにエラーになる問題があること。また、小数点以下で0に近い正解値の場合、極端に大きな評価値になりがちなことである。
MAPEの使い所はなかなか難しく、「適切に使えるか」を慎重に確認する必要がある。ちなみにMAPEの弱点を克服するために、さまざまな代替案(例えばMASE:Mean Absolute Scaled ErrorやSMAPE:Symmetric Mean Absolute Percentage Errorなど)が考え出されているようだが、決定打がまだ出ていないようである(参考:「What the MAPE is FALSELY blamed for, its TRUE weaknesses and BETTER alternatives! | STATWORX」)。
API
主要ライブラリーでMAPEは、次のクラス/関数で定義されている。
- scikit-learn: mean_absolute_percentage_error関数
- TensorFlow(2.x)/Keras: MeanAbsolutePercentageErrorクラスやmean_absolute_percentage_error()関数、また(compile()メソッドの引数metricsで)'mean_absolute_percentage_error'や'MAPE'など
- PyTorch: ※標準では用意されていない。カスタムで自作することは可能。外部のTorchMetricsライブラリーやPyTorch-Igniteライブラリーには用意されている
ここを更新しました(2023年12月4日)
用途の説明の一部をより正確に修正しました。PyTorchライブラリーの内容を追記しました。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。