「AI・機械学習の勉強を始めたい」「AIサービスを作りたい」人のための技術情報フォーラムです!:@IT/Deep Insiderの歩き方
AI技術者を応援するフォーラム「Deep Insider」が@ITに登場してから2年目。その背景やメディアのコンセプト、編集方針などをご紹介するとともに、スキルレベル別のAI・機械学習の学習方法と、それらのレベルに応じた本フォーラムのお勧めコンテンツ、準備中の記事企画についてご紹介しよう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
この記事は2023年以前の古い記事です。最新の記事が下記のリンク先にあります。
AI・データサイエンスの学びをここから
初心者向け、データ分析・AI・機械学習・Pythonの勉強方法 @ITのDeep Insiderで学ぼう
本「@IT/Deep Insider」は、機械学習エンジニアを目指す人〜初中級者のためのAI(人工知能)技術情報フォーラムです*1。主に「これから勉強したい人」〜「AIサービスを作りたい人や実践活用したい人」に向けて、Python言語連載から、技術用語解説、技術解説記事、技術事例、ニュースやイベントレポートなど、AI・機械学習・ディープラーニングに関するさまざまな情報を幅広く発信しています。
*1 私は、本フォーラムの編集長を務めさせていただいている一色政彦です。本フォーラムは、2019年6月18日にオープンし、2020年6月25日現在で、早くも約1年が過ぎたことになります。この1年間のご愛読に感謝を申し上げます。編集スタッフともども、2年目も頑張っていきますので、相変わらぬご愛読のほどよろしくお願いいたします。会員限定コンテンツも多いですが、会員登録は無料ですので、ぜひ登録していただき、各記事の最後まで読んでいただけるとうれしいです。
これからはAIの時代。自分もAI・機械学習の技術を身に付けたいけど、どこから手を付ければよいのか……。
そう思っているソフトウェアエンジニアや学生の方、その他、AIに興味・関心があって、これから本格的に学びたいと考えている人なら誰でも、本フォーラムの読者です。以下のSNSなどを通じて新着記事情報などを発信しているので、ぜひこれを機会に講読/フォロー/いいね!して、Deep Insiderの活動をウォッチしてください!
- @ITメールマガジンの講読
- Twitterアカウント(@DeepInsiderJP)のフォロー(図1)
- Facebookページ(DeepInsiderJP)のいいね!

Deep Insiderフォーラムトップの内容
新着記事をチェックするだけでなく、Deep Insiderフォーラムの既存記事の全貌を把握して、必要な過去記事も読みたいという人は、
を活用しましょう。フォーラムトップはこんな感じです(図2)。
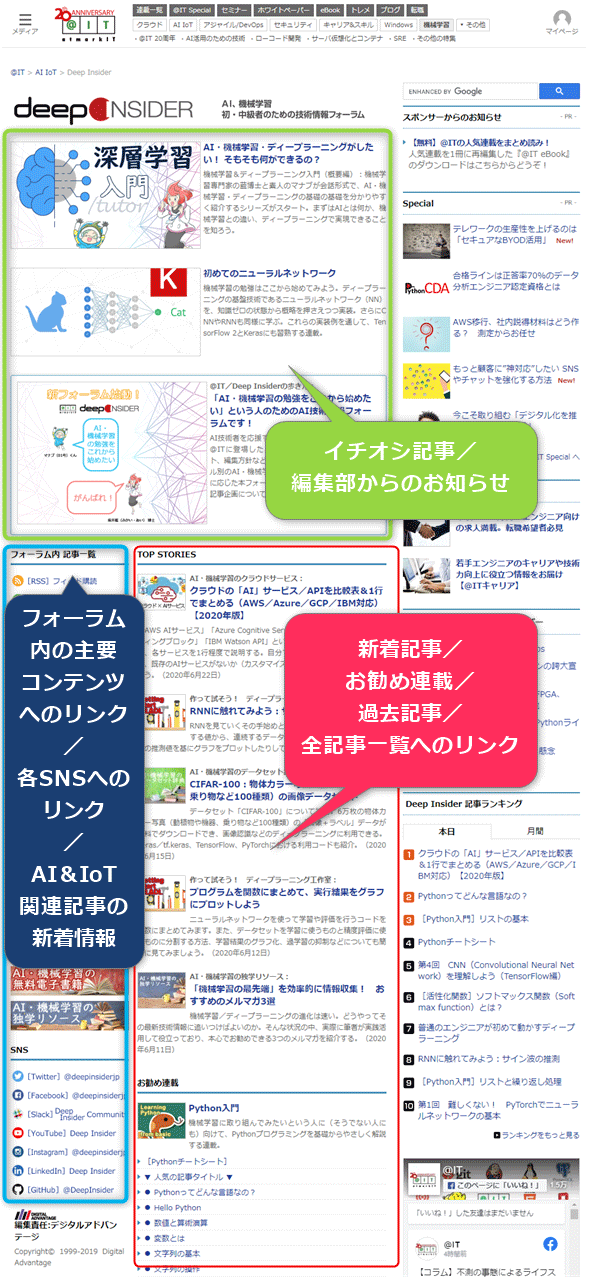 図2 Deep Insiderフォーラムトップ
図2 Deep Insiderフォーラムトップフォーラムトップの上部では、本Deep Insiderフォーラムを初めて訪れた人に向けて[編集部イチオシの記事]を表示しています。また、編集部としてその時々に注目してほしい情報(例えばアンケート調査の実施など)がある場合もここに表示しますので、まずはここに注目してください。
フォーラムトップの中央では、[TOP STORIES(新着記事)]や[お勧め連載]、[過去記事]、[過去記事一覧へのリンク]を掲載します。フォーラム全体から既存記事を探すには、ここを使ってください。特に、「手っ取り早く既存記事を一望したい」というなら、[過去記事一覧へのリンク]を使うとよいでしょう。ここには、Deep Insiderでこれまでに公開した全記事リストが表示されます。
フォーラムトップの左部では、[フォーラム内の主要コンテンツへのリンク]や[Deep Insiderが提供する各SNSへのリンク]、[AI&IoT関連記事の新着情報]などがコンパクトに掲載されます。普段使いのリンクや関連記事チェックなどにご活用ください。AI・機械学習の『用語辞典』『データセット辞典』『無料電子書籍』『独学リソース』といったコンテンツへもここからアクセスできます。
このようにフォーラムトップは、Deep Insiderフォーラム内を効率的に歩くための道しるべ(=知りたい情報にアクセスするためのナビゲーション)となる機能で構成されています。
なぜいまDeep Insiderなのか?
読者と同じ技術者目線でAI技術情報サイトを作っていこう、というのがDeep Insider設立のきっかけです。
2019年3月、日本政府は、「2025年までに年間25万人のAI人材を育成する」という「AI戦略」をぶち上げました。それから1年ほどたち、AI関連の技術記事や書籍もさらに増えてきています。しかし、その対象やレベルはまちまちで、特に初学者にとっては、それらを自分のレベルに照らして正しく位置づけることが困難で、逆に学びの妨げになっているのではないかと感じています。そこでこのDeep Insiderでは、AI・機械学習の開発/使用レベルを次のように分類して、それぞれに応じた記事を配信していきます。
Deep Insiderが考えるAI・機械学習の開発/使用レベル
AI・機械学習の開発/使用には幾つかのレベルがあり、その時々の自分のレベルに応じて必要な技術・スキルを学んでいけばよいと思います。レベルの目安を図3に示します。これはあくまで、Deep Insiderが考えるレベル感であり、一般的な解釈とは異なる部分があるかもしれませんのでご注意ください。

以下では、特に初学者にとって重要なレベル1〜3を中心に、それぞれ簡単に説明するとともに、各レベルに応じたDeep Insiderフォーラムの既存コンテンツや、今後公開予定の記事をご紹介します。
ちなみに、別の視点で「Deep Insiderのお勧め連載」をまとめた、
という記事もあるので、よりシンプルに学びたい場合は上記の記事を参考にしてください。本稿では、Deep Insiderをフル活用して、より本格的/網羅的に学ぶためのお勧めコンテンツを紹介しています。
[レベル1]クラウドのAIサービス/APIを使う(AIカスタマイズ機能も利用できる)
Microsoft Azure、AWS(Amazon Web Services)、GCP(Google Cloud Platform)といった主要クラウドプラットフォームでは、学習済みのAIモデルをAPIで簡単に利用できるようになっています。代表的なAIサービス/APIには以下のものがあります。
これらを使うのに、AI・機械学習の詳細な知識はほとんど要りません。ITエンジニアであれば、ほとんどの人が簡単に使いこなせるでしょう。これらのスキルをマスターしたいなら、本当に難しくないので、実際に上記のリンク先を開いて試してみてください。図4は実際にCognitive ServicesのComputer Vision APIを利用した画像処理のデモページを開いて試してみた例です。画像を与えると、JSON形式で認識結果が返却されています。

なお、AIのサービス/APIだからといって非力というわけではありません。むしろよく検証され確実に成果の出る優秀なAIモデルだけが、サービス化/API化されており、非常に強力なツールであると言えます。
しかも、Cognitive ServicesのCustom機能や、Google CloudのCloud AutoMLは、そういった優秀なAIモデルを、簡単かつ高速にカスタマイズできる機能を提供しています。例えば写真画像からラーメンかチャーハンかを識別するAIモデルを作成したい場合、たった数十枚のラーメンとチャーハンの写真をデータとして与えて追加で学習させるだけで(これを転移学習と呼びます)、独自で優秀なAIモデルを作成できます。
こういったレベル1の技術・スキルを対象にした記事として、
を公開しています(※毎年、更新予定です)ので、ぜひご活用ください。本Deep Insider内でも大人気の記事の一つになります。
[レベル2]サンプルのAIモデルを動かす(AI・深層学習の基本を理解)
Python関連を学ぶ
次のレベル2では、サービス化されたAPIを使うのではなく、サンプルコードが公開されているAIモデルを自分で動かします。
これには、まずはPython言語を習得し、NumPyやpandasといったPythonライブラリを使いこなす必要があります。といっても、Python言語やライブラリ利用は、慣れてしまえばそれほど難しくありませんので、ITエンジニアであれば比較的、楽に習得できるでしょう。
Deep Insiderフォーラムでは、
- 『Python入門』
という初心者向けで網羅性のある入門連載を展開しています(※要約版の『Pythonチートシート』/無料の電子書籍版[PDFファイル]もあります)。本Deep Insiderで一番人気の連載になります。上記リンク先の目次は、もちろん初心者だけでなく、中・上級者が「あれ、どう書くんだっけ?」というようなときに探すリファレンスとしても活用できるでしょう。

「プログラミングやコンピュータが初めて」という超初心者の人に対しては、最低限の基礎知識として、
という短い連載(※今後、改訂して、コンテンツ内容を改善することを検討中)も用意しています。
また、Pythonでコードを書いていくための作業環境や、Pythonユーザーの必修ライブラリとも言えるNumPyに関する基礎知識として、
という短い連載(※改訂予定)を用意しています。
人工知能と機械学習の基本概念を学ぶ
さて、Python関連が終わったら、いよいよ機械学習エンジニアのスキルが必要となってきます。まずは、AI・機械学習の知識が必要です。「推論」「ニューラルネットワーク」「バイアス」「ハイパーパラメーター」「Dropout」など、機械学習の専門用語はたくさんあります。まずはそういった基本的な専門用語に習熟する必要があります。用語を正確に理解していない部分があると、例えばディープラーニング(深層学習)の全体像の把握が難しくなります。
これに対応するためDeep Insiderフォーラムでは、
という3つの連載枠を用意し、記事を展開しています。特に『機械学習&ディープラーニング入門(概要編)』は人気コンテンツなので、無料の電子書籍版「普通のエンジニアでも分かるディープラーニング概説[PDFファイル]」も提供しています(図6)。

なお、『基本概念』は仕切り直して連載再開予定です。『用語辞典』は順次拡充していっています(図7)。

機械学習やニューラルネットワークの仕組みと意味を学ぶ
ディープラーニングの概要と用語を理解したら、次はニューラルネットワークの仕組みと挙動の意味を理解しましょう。意味を理解することは、ディープラーニングの後ろで動く数式を理解することよりも重要です。意味を理解して初めて、思い通りの機械学習のコードを自分一人で書けるようになるからです。このレベル2では機械学習やニューラルネットワークの仕組みを学び、基礎を固めることに集中しましょう。
Deep Insiderフォーラムでは、直感的に理解できる「ニューラルネットワーク Playground - Deep Insider」(旧称:TensorFlow Playground、図8)を使った、
という連載を展開しています。これも人気連載であるため、無料の電子書籍版「普通のエンジニアが初めて動かすディープラーニング[PDFファイル]」も作成して提供しています。

サンプルのAIモデルを動かす
ニューラルネットワークの仕組みを理解し、ディープラーニングの基礎を体験したら、何かサンプルのAIモデル(学習済みのAIモデル)を動かしてみるのがよいでしょう。そこからやりたいことを広げることで、機械学習を学ぶことに、より拍車がかかるからです。
ディープラーニングの教育/学習ツールとして、AIロボットカーは楽しみながら学べる点でお勧めできます。AIロボットカーとしては、AWS DeepRacerやNVIDIA JetBotなどがあります。例えばJetBotで対象物を機械学習させて回避するようにするには、JetBot Wikiで提供されたサンプルコード(図9はその例)を手順通りに実行して、学習済みAIモデルを使ったり、自分で学習させたりするだけです。よりうまくAI自動運転を実現しようとすると、自分なりにコード(例えば数値など)を変えて学習し直す必要もあるでしょうが、そうすることでディープラーニングの意味や挙動を効率的に学べます。

Deep Insiderフォーラムでは、AWSが提供するDeepRacerを詳しく解説した、
という連載を展開しており、ディープラーニングの強化学習について学べます。
ちなみに、AWSではこの他にも、ディープラーニングに対応したビデオカメラである「AWS DeepLens」や、GANという手法で音楽を生成できるキーボードである「AWS DeepComposer」(※執筆時点で日本では購入不可)を提供していますので、そういったものにチャレンジしてみるのもよいでしょう。
[レベル3]一般的なAIモデルを作る(ネットワークを自分で作る)
次のレベル3は、機械学習エンジニアと名乗ってもよいレベルを想定しています。
機械学習ライブラリを学ぶ
機械学習/ディープラーニングの基本用語と仕組みを一通り学んだら、TensorFlow/KerasやPyTorch、scikit-learnといった機械学習ライブラリのコードが理解できるようになりましょう(※TensorFlow/Kerasの関連情報:「マルチバックエンドKerasの終焉、tf.kerasに一本化」)。
恐れる必要はありません。ライブラリを使った機械学習のコードは、数十行〜数百行程度です。例えばWebアプリ開発などの経験があるITエンジニアにとって、機械学習のコードを読み解き実行することは、それほど難しいことではないと思います。
TensorFlow/Kerasでのコードの書き方については、
で説明しています(※「第4回」となっているのは、前述の「第1回 初めてのニューラルネットワーク実装、まずは準備をしよう ― 仕組み理解×初実装(前編)」という全3回の連載記事の続編であるためです)*2。プログラミングに不慣れな人には少し骨がある内容かもしれないですが、頑張って最後まで読み通してみてください。
*2 この『TensorFlow 2+Keras(tf.keras)入門』は、TensorFlowのバージョン2をベースにしています。バージョン1と2でコードの書き方が大きく異なります。TensorFlowのバージョン1については、『TensorFlow入門』という連載で学べます。

また、PyTorchでのコードの書き方については、
で説明しています。TensorFlow/KerasかPyTorchか、どっちを学ぶべきか悩むのは初心者の誰もが通る道です(参考:「PyTorch vs. TensorFlow、ディープラーニングフレームワークはどっちを使うべきか問題」)。現時点でのDeep Insiderなりの答えは「両方とも使えるようになる」です。ただし、ネット上でPyTorchの情報はまだまだ少ないようです。しかしながら、人気急上昇中なのは間違いありません。実際に、上記の『PyTorch入門』連載は、Deep Insiderの定番人気コンテンツの一つとなっています。

なお、『TensorFlow 2+Keras(tf.keras)入門』と『PyTorch入門』の連載には、今後もコンテンツを追加していく予定です。
最後に、scikit-learnですが、Deep Insiderにはまだコンテンツがありません。Deep Insiderは、名前の通り、1年目はディープラーニングにフォーカスしてきたからです。ディープラーニングに関する基礎コンテンツも充実してきているので、2年目はscikit-learnによる機械学習に対象範囲を広げる予定です。
ライブラリを活用して実践する
ライブラリの使い方を学んだら、次にCNNやRNNといったディープラーニングの基礎的な手法を学び、さらに、より現実的な手法を学ぶとよいでしょう。
Deep Insiderフォーラムでは、
という連載を展開しており、本当の初心者からでも、著者と一緒にディープラーニングを体験しながら、基礎的な手法〜現実的な手法を身に付けていくことができます。(大げさだと思いますが)いわば「著者と二人で行うPBL(問題解決型学習)記事コンテンツ」となっています。PBLとは、自ら問題を発見し解決することで能動的に学ぶことを促す教育方法で、近年、データサイエンス学部などでの大学教育にも導入され、注目を集めています。

数学について
機械学習やディープラーニングを学び始めると、必ず数学が出てきます。ディープラーニングの仕組み自体が、数学を使った理論によって成り立っているからです。しかし「本当に数学を学ぶ必要があるかどうか?」は難しい質問です。
ディープラーニングを動かすのに必ずしも数学は必要ありません。ライブラリを道具として使えば済むからです(例えば、上で紹介した『作って試そう! ディープラーニング工作室』はあえて数学の難しい話にはなるべく触れないような内容になっています)。ただし、書籍などから多くの知識を得ようとした場合に、やはり数学力が必要です。また、例えば機械学習エンジニアとして転職した場合、チームメンバーとの会話で数学や統計学のキーワードが飛び交うことになるでしょう。「ディープラーニングの基礎を完全にマスターした」と言い切るためには、数学面からの理解は避けられないと思います。
そういった高い数学力を目指す機械学習の初心者には、まずは「数学をやらないと!」と力みすぎないことをお勧めします。数学は、積み上げ型の学問であり、ゆっくりと習熟しながら身に付ける他ありません。最低でも数カ月、できれば1年間くらいかけてゆっくり着実に学ぶことをお勧めします。それにピッタリな連載を用意しました。
この連載では、「準備(中学数学の復習)」「微分」「線形代数」「確率統計」と一通り必要な数学分野をカバーします。全12回〜20回程度で、来春までには完結する予定です。ぜひ約1年のペースでゆっくりと学んでみてください。

できるだけ多くの課題を解きまくる
あとは、さまざまな機械学習の課題にチャレンジして、技術とスキルを磨き続けることです。といっても、課題を見つけるのが大変だったり、そもそもデータ集めが難しかったりします。そんな場合は、コンペティション/コンテストに参加するのも良い方法で、特にKaggleや日本国内のSIGNATEがお勧めです(図14、Kaggleについてはこちらの記事を参考にしてください)。

取りあえず始めるには、既にKaggleに関する本が何冊か出版されていますので、それらを読んで始めてみてください。次に、Slackコミュニティ「kaggler-ja」に入って、Kaggle初心者同士で情報交換をしましょう。
筆者自身もKaggleに挑戦中です。Deep Insiderフォーラムでは、今後、Kaggleに関する記事も発信していきたいと考えています。
[レベル4]/[レベル5]研究者やデータサイエンティストになる必要はない
残りの、
- [レベル4]最先端のAIモデルを使う(論文などを読んで作る)
- [レベル5]完全に独自のAIモデルを作る(理論を作って論文を書く)
は、どちらかというと研究者の領域です。研究者という言葉通り、論文収集サイト「arXiv(アーカイブ)」で機械学習の論文を探して、適切な論文を発見して読み、自分のプロジェクトに適用したり、自分の独自理論を作って論文を書いて発表したりします。まだ誰も踏み込んだことがないような領域にAI技術を適用する場合に求められるスキルレベルです。
ITエンジニアなどの初心者から始めてこの領域にまで踏み込めるに越したことはありませんが、このレベルはDeep Insiderが想定する読者レベルを超えていますので、当フォーラムでは、基本的に[レベル4]や[レベル5]の情報は提供しない予定です。
なお、本Deep Insiderがメインのターゲットにしているのは機械学習エンジニアです。もちろんデータサイエンティストが読んでも役立つコンテンツはあるとは思います。しかし、機械学習エンジニアとデータサイエンティストは、最終的な目的が異なるので、おのずと読みたい記事の傾向も異なると、Deep Insider編集部では考えています。
機械学習エンジニアは、あくまで機械学習を専門とするソフトウェアエンジニアであり、最終的な目的は主に「AIサービス/アプリ/デバイスを作る」ことです。本Deep Insiderでもその最終目的を大切にしています。実際の仕事になると、開発力とプロジェクト管理能力が要求されるでしょう。
一方、データサイエンティストは、あくまで機械学習もできるデータアナリストであり、最終的な目的は主に「データを分析してインサイト(洞察)を得る」ことです。そのために、統計学とデータベースに関する深い知識が必要不可欠です。仕事では、分析力とコンサルティング力が要求されるでしょう。
要するに、あなたはデータから「AIサービスを作りたいのですか?」「インサイトを得たいのですか?」と聞かれたときの、あなた自身の回答を用意しておくべきです。それが目指すべき職種なので、おのずと学習の内容や仕方も異なってくると思います。
また、できるだけ早い段階で、自分の得意とする専門分野を絞るべきです。画像認識や自然言語処理、異常検知、ロボット制御などに対する強化学習など、全て浅く知っておくことには賛成しますが、全てを完璧にこなすことは難しいからです。Kaggle挑戦後は、画像認識を専門にするのか、その中の物体検知を極めるのか、といった具合に、自分の強みを高めていくとよいでしょう。
@IT/Deep Insiderをよろしくお願いします!
本Deep Insiderは、この1年間、皆さまのおかげで、ページビューもうなぎ登りで成長できました。Deep Insiderは2年目を迎えて新たな野望を抱いています。調子に乗りすぎだと思いますが、
- 「“機械学習の総合ポータル”に!!! おれはなるっ!!!!」(ルフィ風)
と宣言したいと思います。そのためには、Deep Insiderのコンテンツだけでなく「世の中に埋もれている優良コンテンツを読者に紹介していくのも大事」と考え、
という連載枠に、独学用のコンテンツを紹介する記事を拡充させていっています。今後のDeep Insiderの活動にご期待ください。
また、冒頭でも示した、
をぜひぜひお願いします。今後ともよろしくお願い申し上げます。
最後に、本Deep Insiderフォーラムのイメージキャラクタを紹介します。「マナブ(01号)くん」と「深井藍(ふかい・あい) 博士」です(図15)。たまに記事で使われていることがありますので、以後お見知りおきください。
 図15 イメージキャラクタと共に学ぼう
図15 イメージキャラクタと共に学ぼうCopyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。