AI・機械学習の用語辞典
AI・機械学習の重要キーワードを解説する用語集(Glossary)。
AI・機械学習の用語辞典:
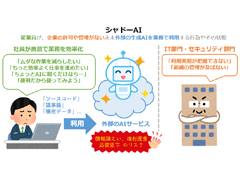
企業のIT部門やセキュリティ管理部門の許可や監視がないまま、従業員が外部の生成AIサービスを業務に利用する行為や状態。業務効率化という善意の目的でAI利用が自然と広がる一方で、情報漏えいやガバナンス上のリスクを内包する、現代的な課題として注目されている。

AI・機械学習の用語辞典:
製品やサービスのマーケティングにおいて、実際にはAI技術が中核的に使われていないにもかかわらず、「AI活用」「AI搭載」「生成AI対応」などの表現によって、あたかも高度なAIが主要な価値であるかのように見せる行為や傾向。AIブームの広がりとともに、ホワイトウォッシングやグリーンウォッシングと同様、表現と実態のズレを捉えるための言葉として使われている。

AI・機械学習の用語辞典:
AIモデルとの対話が長く続く中で、「本筋とは無関係な話題」や「途中で行き止まりになった試行」といったノイズがコンテキスト内に蓄積し、その結果として出力品質が急速に低下していく現象。やり取りが進むほど回答が乱れたり、急に話がかみ合わなくなったりする際の主因と考えられる。

AI・機械学習の用語辞典:
「指標が意思決定に使われるほど、目的を見失って行動が偏り、プロセス(=制度や活動の進め方)がゆがむ」という経験則。もともとは教育改革におけるテストスコアの扱われ方を問題提起したものだが、現在では企業のKPI運用や政策評価、AIモデルの性能指標などで引用される。

AI・機械学習の用語辞典:
「私たちは、技術の短期的な影響を過大評価し、長期的な影響を過小評価する」という言葉で知られる経験則。近年では生成AIの議論でもこの傾向が指摘されている。なお、アマラの法則における“過大評価”はハイプサイクルの「過度な期待のピーク」に、“過小評価”は「幻滅期」に重ねて語られることもある。

AI・機械学習の用語辞典:
最初に「何を実現すべきか」を“仕様”として明文化し、それを唯一の基準としてコード生成や検証を進めていく新しい開発スタイル。人間の意図を表した“仕様”が基準となるため、“雰囲気”を重視するバイブコーディングよりも高精度な開発が可能。

AI・機械学習の用語辞典:
「こういうアプリが欲しい」といった“雰囲気”(=Vibe)をAIに伝え、対話を通じてコードを生成していく新しいプログラミングスタイル。厳密な仕様や細かな指示を与えなくても、AIが意図をくみ取り、実際のコードとして形にしてくれるのが特徴。高度な専門知識がなくても試せるため、非エンジニアにも広がりつつある。

AI・機械学習の用語辞典:
2つの確率分布間の“距離”を測る指標で、「ある分布をもう一方に重ねるために、どれだけ“確率質量”を動かす必要があるか」を表す。値が0なら「完全一致」、大きいほど「異なる」ことを意味する。主に統計学や機械学習で使われ、データドリフト検出や生成モデル(WGAN)などに応用される。別名「アースムーバー距離」。

AI・機械学習の用語辞典:
2つの確率分布間の“距離”を測る指標で、値は0(一致)〜1(不一致)の範囲に収まる。ユークリッド距離に似た計算式で定義されており、確率分布の違いを直感的に扱えるのが特徴である。主に統計学や機械学習の分野で、確率分布間の比較や類似度評価に利用されている。

AI・機械学習の用語辞典:
2つ(以上)の確率分布間のズレを測る指標で、KLダイバージェンスをベースに「対称化」し、「値の範囲が0以上〜1以下に収まる」ようにしたもの。複数の分布間の類似度を測ることができ、主に自然言語処理や生成モデルの評価、クラスタリングなどで利用されている。

AI・機械学習の用語辞典:
「成功には必要条件を全て満たさなければならないが、失敗は1つ欠けるだけで起こる」という原則。文学作品の一節に由来し、生態学や経営学など幅広い分野で引用されてきたが、近年では機械学習の分野においても言及されるようになった。

AI・機械学習の用語辞典:
センサーやデータを通じて現実世界を認識、理解し、それに基づいて行動するAIのこと。ロボットや自動運転車など、物理的な環境の中で自律的に動く機械の頭脳として注目されている。特にNVIDIAや学術分野で関心が高まっており、今後は社会での実用が本格化すると見込まれている。

AI・機械学習の用語辞典:
「効率化によって、かえって消費が増えてしまう」という逆説的な現象のこと。もともとは、産業革命期に見られた蒸気機関の効率化と、それに伴う石炭消費の増加をめぐって提起されたが、現代でも電力やAIの計算資源を語る際に引き合いに出されることがある。

AI・機械学習の用語辞典:
AIに関する発言や議論の中では、ある特徴や本質をひと言で表した「明言」や、現場で広く知られる「経験則」がたびたび登場します。そうした「明言」や「経験則」の中でもAIを設計/運用/理解する当たって役立つ5つをピックアップしてご紹介します。取り上げるのは「オッカムの剃刀」「パレートの法則(80対20)」「GIGO(Garbage In, Garbage Out)」「イライザ効果」「スケーリング則」の5つです。

AI・機械学習の用語辞典:
AIには、その仕組みや性能上の限界、人間とは根本的に異なる特性などを浮き彫りにする「○○問題」と呼ばれる用語が幾つかあります。その中でも特に代表的なものをピックアップしてご紹介します。取り上げるのは「シンボルグラウンディング問題」「フレーム問題」「トロッコ問題」「ブラックボックス問題」「コールドスタート問題」の5つです。

AI・機械学習の用語辞典:
AIに関してギャップや矛盾を感じる現象には、“逆説”として法則化されているものがあります。AIの本質や限界、人間との根本的な違いを映し出すヒントになる、“逆説”にまつわる用語として「AI効果」「モラベックのパラドックス」「ポランニーのパラドックス」「グッドハートの法則」「シンプソンのパラドックス」の5語を紹介します。

AI・機械学習の用語辞典:
「未知の選択肢を試す(探索)」か、「既知の選択肢を使い続ける(利用)」か。一方を重視すれば他方がおろそかになる難しさがあり、うまくバランスを取ることが求められる。このジレンマは、さまざまな意思決定に共通する課題であり、特に強化学習ではそのバランスの調整がモデルの性能に大きく影響する。

AI・機械学習の用語辞典:
初期データが不足しているために、適切な推薦や予測ができない問題。レコメンデーション(推薦)システムやAI/機械学習では、大量のデータを用いた学習が前提となるが、新たなサービスの開始直後や、新規ユーザーの登録直後、新しい商品が追加された直後には、十分なデータが得られずにこの問題が発生する。

AI・機械学習の用語辞典:
「不要な仮定はそぎ落として、必要以上の複雑さは避けるべき」とする考え方。古くは哲学の世界で提唱された原則だが、現在では科学から日常の意思決定まで幅広く応用されている。AI/機械学習/統計/データ分析の分野でも、モデル選択や仮説評価の原則としてしばしば引き合いに出される。

AI・機械学習の用語辞典:
「指標が目標になると、それは“良い指標”ではなくなる」という逆説的な法則のこと。もともとは経済政策の現場で知られてきたが、教育評価や業績管理など、目標を数値化する場面でも応用されることが多い。AIや機械学習の文脈でも、評価指標に関する議論などで言及されることがある。

AI・機械学習の用語辞典:
成果の大半(80%)は、一部の要素(20%)から生まれる──この構図を示す経験則が「80:20の法則(パレートの法則)」。経済やビジネスの世界で広く知られ、しばしば引用される。この法則はAI・機械学習の分野でも比喩的に用いられることがあるが、そこに理論的な根拠があるわけではない点には留意しておきたい。

AI・機械学習の用語辞典:
人間は経験(=暗黙知)として知識を身に付けるが、それを言葉(=形式知)にして他人に伝えるのは難しい、という逆説を指す。このため、知的活動をAIに教えることも困難とされてきた。これはルールベースのAIの話であり、近年の機械学習では暗黙知に近い振る舞いを模倣できるようになってきている。ただし、本質的な課題は依然として残されている。

AI・機械学習の用語辞典:
用語「交差エントロピー」について説明。分類タスクを解くための機械学習モデルの訓練に広く用いられる損失関数の一つで、「“正解ラベルの確率分布”から“モデル出力の確率分布”がどれくらいズレている(=不一致)か」を数値で表す。特に、ロジスティック回帰やニューラルネットワークの分類タスクでよく使用される。

AI・機械学習の用語辞典:
用語「KLダイバージェンス」について説明。2つの確率分布間のズレを測る指標で、「ある確率分布が別の確率分布とどれだけ異なるか」を評価するために使用される。値が0なら「完全一致」、大きいほど「異なる」ことを意味する。主に統計解析や機械学習モデルの評価、データドリフト検出などで利用されている。

AI・機械学習の用語辞典:
社会人から学生まで、今や現代人の大半は生成AIと無縁ではいられないでしょう。もはや“常識”となりつつある用語として「AI」「生成AI」「AGI」「ASI」「AIアライメント」「LLM」「ローカルLLM」「マルチモーダルAI」「エッジAI」「AIエージェント」の10語を紹介します。

AI・機械学習の用語辞典:
ローカルLLMとは、ユーザーが所有するローカル環境(PCやエッジデバイスなど)で直接動作するLLM(大規模言語モデル)、またはその仕組みのこと。データをクラウドに送信せずにローカル環境内で処理するため、プライバシーが保護される。特定のタスクや業界向けの調整がしやすいメリットもある。

AI・機械学習の用語辞典:
用語「AIエージェント」について解説。特定の目標を達成するために、必要なタスクを自律的に作成し、計画的に各タスクを実行するAIシステムのこと。これにより、人間の作業を大幅に自動化できる可能性がある。また、複数のAIエージェントを組み合わせることで、より高度な自動化が期待されるAIマルチエージェントも登場している。

AI・機械学習の用語辞典:
用語「AIアライメント」について解説。AIシステム(主に大規模言語モデル)が人間の意図や倫理観に沿うように、AIを訓練、調整するための技術や理念のこと。これにより、AIが社会や人間にとって安全(つまり無害かつ正直)で、役立つ存在にすることを目指す。

AI・機械学習の用語辞典:
エッジAIとは、エッジデバイス(=インターネットにつながる“IoT”対応機器やスマートフォンなど、利用者に近い場所にある端末)上で動作するAIのこと。データをクラウドに送信せずにデバイス内で処理するため、プライバシーが保護され、限られたリソースで効率的かつ高速に動作する特徴がある。

AI・機械学習の用語辞典:
用語「ASI(人工超知能)」について解説。AGI(汎用人工知能)が人間と同等の知能を持つのに対し、ASIはそれを超えて、人間をはるかに超える知能を持ち、あらゆる分野で最も優れた能力を発揮するAIのことを指す。また、ASIは自律的に自己改善を行う特徴を持つとされている。

AI・機械学習の用語辞典:
用語「ジャッカード距離」について説明。集合間の「異なり」(=非類似度)を評価する尺度で、「2つの集合がどれだけ異なっているか」を測定するために使用される。集合間の「重なり」(=類似性)を測定するジャッカード類似度と対になる概念。値は0〜1で、1に近いほど「異なっている(=似ていない)」を意味する。

AI・機械学習の用語辞典:
用語「オーバーラップ係数」について説明。集合間の類似性を評価する尺度で、「2つの集合の共通部分が、いずれかの集合のうち小さい方の集合の大きさと比べて、どれだけ大きいか」を測定するために使用される。値が1に近いほど「似ている」を、0に近いほど「似ていない」を意味する。部分的な一致が重要視される場面で利用されている。

AI・機械学習の用語辞典:
用語「ダイス係数」について説明。集合間の類似性を評価する尺度で、「2つの集合の共通部分が、それぞれの集合の大きさと比べて、どれだけ大きいか」を測定するために使用される。値が1に近いほど「似ている」を、0に近いほど「似ていない」を意味する。少数の一致でもその正確性が重要視される場面で利用されている。

AI・機械学習の用語辞典:
用語「ジャッカード類似度」について説明。集合間の類似性を評価する尺度で、「2つの集合がどれだけ重なり合っているか」(=全体の要素数に対する共通部分の割合)を測定するために使用される。値が1に近いほど「似ている」を、0に近いほど「似ていない」を意味する。主にクラスタリングや文書比較などで利用されている。

AI・機械学習の用語辞典:
用語「レーベンシュタイン距離」について説明。2つの系列(文字列やDNA配列など)を比較して、一方から他方へ変換するのに最も少ない編集操作(挿入/削除/置換)の回数をカウントすることで、2系列間の距離を計測する方法。文章の編集作業量の計測、スペルチェック、データクリーニング、DNA配列の比較などに利用され、データ間の違いや類似度を評価できる。

AI・機械学習の用語辞典:
用語「ハミング距離」について説明。同じ長さの2つの系列(文字列やビット列)を比較して、異なる位置の数をカウントすることで、2系列間の距離(または類似度)を計測する方法。エラーチェックやデータ比較、クラスタリングに利用され、データ間の違いや類似度を直感的に評価できる。

AI・機械学習の用語辞典:
用語「マハラノビス距離」について説明。2点間の距離を計測する方法の一つで、「“普通の距離”(=ユークリッド距離)を一般化したもの」とも言われる。データの分布(共分散行列)を考慮することで、データのばらつき具合や相関関係を反映した距離を計算できる。異常値や外れ値を識別するために有効であり、特に多次元データにおいて正確な距離測定が可能。

AI・機械学習の用語辞典:
用語「ミンコフスキー距離」について説明。2点間の距離を計測する方法の一つで、マンハッタン距離(L1ノルム)やユークリッド距離(L2ノルム)、チェビシェフ距離(L∞ノルム)などを一般化したもの。パラメーター「p」の値を調整することで柔軟に距離を表現できる。

AI・機械学習の用語辞典:
用語「チェビシェフ距離」について説明。2点間の距離を計測する方法の一つで、2つの点座標(n次元)で「次元ごとの距離(=各成分の差)の絶対値」のうち「最大値」を距離として採用する計算方法を意味する。

AI・機械学習の用語辞典:
用語「BM25」について説明。各文書中の各単語の重要性をバランスよく評価する尺度で、主に検索クエリに最も一致する文書を特定するのに用いられる。キーワード検索以外にも、類似文書の検索やレコメンデーションにも活用できる。計算式は「(ある単語の文書間でのレア度)×(ある文書における、ある単語の出現頻度、の正規化された値)」で、正規化するための調整パラメーターを持つ、tf-idfの発展版と見なせる。

AI・機械学習の用語辞典:
生成AI時代を生きる社会人に必須の基礎知識を身に付けよう。生成AIに関する用語として「生成系AI」「大規模言語モデル(LLM)」「プロンプトエンジニアリング」「ハルシネーション」「埋め込み表現」「ベクトル検索」「ベクトルデータベース」「RAG(検索拡張生成)」「事前学習」「ファインチューニング」の10語を紹介する。代表的なチャットAIやLLM、画像生成AIについても触れる。

AI・機械学習の用語辞典:
用語「RAG」について説明。ChatGPTなどのチャットAIに独自の情報源を付与する仕組みのことで、具体的には言語モデルによるテキスト生成に特定の情報源(ナレッジベース)の検索を組み合わせること。これには、生成内容の正確さを向上させるメリットがある。

AI・機械学習の用語辞典:
用語「グラウンディング」について説明。特定の知識や情報源(ナレッジベースなど)に基づいて言語モデルの生成内容を裏付けるプロセスのことで、チャットAIに独自の情報源を付与するRAG(検索拡張生成)という仕組みがその代表例。チャットAIがもっともらしいウソを答える問題(=ハルシネーション)を減らせるといったメリットがある。

AI・機械学習の用語辞典:
ベクトルデータベースとは、テキストなどのデータを数値ベクトル(埋め込み)として保存するデータベースを指す。「ベクトルストア」とも呼ばれる。ベクトル検索により、意味的に類似する情報を探せるのが特徴で、チャットAIのRAG構築に役立つ。本稿ではベクトル検索の機能を持つ代表的な製品の概要もそれぞれ簡単に紹介する。

AI・機械学習の用語辞典:
全てまたはほとんどの成分が0以外の数値を持つベクトルを「密ベクトル」と呼び、その代表例にはテキストなどのEmbedding(埋め込み表現)がある。また、大部分の成分が0で、一部のみが0以外の数値を持つベクトルを「疎ベクトル」と呼び、その代表例にはテキスト文書のtf-idf値がある。

AI・機械学習の用語辞典:
用語「ベクトル検索」について説明。テキストなどのデータを数値ベクトル(埋め込み)として表現し、それらのベクトル間の類似度を計算することで、関連する情報を見つけ出す検索方法を指す。Azure OpenAI Serviceの独自データ追加機能で利用可能な「キーワード検索」「ベクトル検索」「ハイブリッド検索」「セマンティック検索」という検索手法の違いについても言及する。

AI・機械学習の用語辞典:
用語「Embedding(埋め込み)」について説明。単語やテキスト、画像を、AI/言語モデルが扱いやすい数値ベクトル(例:[0.4, -0.1, 0.2, ...])に変換する技術のこと。Word Embedding(単語の埋め込み)では、意味的に近い単語同士がベクトル空間上で近接するように変換される。

AI・機械学習の用語辞典:
用語「移動平均」について説明。時系列データ(例: 株価)を平滑化すること、具体的には一定期間(例:5日間)の平均値を計算することをデータポイントごとに繰り返し、計算後の一連の平均値を線でつなぐこと(移動平均線)。データの長期的な傾向や短期的な動きを把握するのに役立つ。

AI・機械学習の用語辞典:
用語「トリム平均」について説明。昇順または降順に並べたデータの上位と下位から一定の個数または割合で値を除外(トリム)し、残ったデータで平均を求めること。特に外れ値を含むデータセットで統計的にデータを解釈する際に役立つ。

AI・機械学習の用語辞典:
用語「Average」と「Mean」の違いについて説明。両方とも「平均」と訳されるが、「Average」が日常的な会話や文脈の中でよく使われる一般的な用語であるのに対し、「Mean」は数学/統計学/機械学習といった専門的な文脈の中でよく使われる専門的な用語であるという違いがある。

AI・機械学習の用語辞典:
用語「調和平均」について説明。データの各数値の逆数で平均を取り、さらにそれを逆数にして戻した値を表す。計算式にすると、データ数を「データの各数値の逆数」の総和で割る形になる。速度/レート(率)のデータ(=逆数の形で加算される加法的なデータ)を平均する場合に適した平均の計算方法だ。

AI・機械学習の用語辞典:
用語「幾何平均」について説明。幾何平均はデータの各数値を掛け合わせた積のn乗根(nはデータ数)を取った値を表す。時間に応じて変化する変化率/比率/倍率のデータ(=乗算後に累積される乗法的なデータ)を平均する場合に適した平均の計算方法だ。

AI・機械学習の用語辞典:
用語「加重平均」について説明。算術平均がデータの合計値をデータ数で割った値なのに対し、加重平均は重み付けしたデータの合計値を全ての重みの合計値で割った値を表す。各データが異なる重要度を持つ場合に適した平均の計算方法だ。

AI・機械学習の用語辞典:
用語「プロンプトエンジニアリング」について説明。チャットAI(大規模言語モデル)や画像生成AIなどの生成系AIで、より望ましい返答テキストや画像などが生成されるように、ユーザーがAIモデルに入力する質問や指示のプロンプト(=テキスト)を工夫することを指す。

AI・機械学習の用語辞典:
用語「思考の連鎖プロンプティング」について説明。問題を解くまでの一連の手順をプロンプトに含めるテクニックを指す。人間の思考プロセスでは、算術などの問題を途中の手順(計算過程)に分解して段階的に解いていくことが一般的だが、それを模倣した、プロンプティングのテクニック。

AI・機械学習の用語辞典:
用語「フューショット学習」について説明。ChatGPTなどの言語モデルが少数の例文から効率的に学習し、多様なタスクを解決できることを指す。大量データが必要な一般的な機械学習や既存モデルの再学習(ファインチューニング)と比べ手軽。また、コンピュータビジョンなど他の機械学習分野でも、少量データから学習する同じ用語が使用されている。

AI・機械学習の用語辞典:
用語「ゼロショット学習」について説明。訓練データに存在しない新しいクラスやタスクに対しても有用な予測/分類を行うための学習方法のことで、特にChatGPTの言語モデルなどでは、ファインチューニングすることなく、かつ例文もない状態で、さまざまなタスクを解決する能力を持つことを指す。

AI・機械学習の用語辞典:
用語「創発」について説明。大規模言語モデルの計算量やパラメーター数が非常に大きくなると、“あるところ”を境に、突然、新しい能力を獲得して性能が大きく向上する現象を指す。

AI・機械学習の用語辞典:
用語「フランケンシュタイン・コンプレックス」について説明。自己意識を持つ機械(AI/ロボット)が暴走して人間に反逆するなど厄災をもたらすようになる可能性に対する根拠のない恐怖を指す。

AI・機械学習の用語辞典:
用語「RLHF」について説明。人間のフィードバックを使ってAIモデルを強化学習する手法を指す。OpenAIのChatGPT/InstructGPTでは、人間の価値基準に沿うように、言語モデルをRLHFでファインチューニング(微調整)している。

AI・機械学習の用語辞典:
用語「スケーリング則」について説明。自然言語処理モデルのサイズ(=パラメーター数)や、データセットのサイズ、トレーニングに使用される計算量が増えるほど、より高い性能を発揮できる、という法則を指す。

AI・機械学習の用語辞典:
用語「AI効果」について説明。「最新のAI」として話題になった技術が、一般社会に受け入れられて普通に使われるようなるにつれて、「AI」とは呼ばれなくなる現象を指す。

AI・機械学習の用語辞典:
用語「イライザ効果」について説明。コンピュータプログラム/AIモデルの動作が人間の動作に類似していると無意識に想定する傾向のこと、つまり例えばチャットボット/チャットAIを「擬人化」して感情移入することを指す。

AI・機械学習の用語辞典:
ハルシネーションとは、チャットAIなどが、もっともらしい誤情報(=事実とは異なる内容や、文脈と無関係な内容)を生成することを指す。AIから返答を受け取った人間が「本当かどうか」の判断に困るという問題がある。この問題を回避する方法として、独自の情報源を付与するRAGや、Webアクセスを含める機能などがある。

AI・機械学習の用語辞典:
用語「大規模言語モデル」について説明。大量のテキストデータを使ってトレーニングされた自然言語処理のモデルのことを指す。

AI・機械学習の用語辞典:
用語「基盤モデル」について説明。大量のラベルなしデータを使って事前学習し、その後、幅広い下流タスクに適応できるようにファインチューニングする、という2段階の訓練工程を踏んだ、1つのAI・機械学習モデルのことを指す。

AI・機械学習の用語辞典:
用語「自己教師あり学習」について説明。ラベルなしの大量データセットを使って、プレテキストタスク(疑似的なラベルが自動生成された代替のタスク)を解くための事前学習を行う学習方法のこと。その後、ターゲットタスクを解くために、(少量の)別のデータセットを使って事前学習済みモデルをファインチューニングする。

AI・機械学習の用語辞典:
用語「事前学習」「下流タスク」について説明。訓練の工程を2段階に分けて、最初に機械学習モデルを訓練することを「事前学習」、次にその事前学習済みモデルを新しいタスクに向けて転移学習/ファインチューニングすることを「下流タスク」と呼ぶ。自己教師あり学習でも同様の用語が使われる。

AI・機械学習の用語辞典:
用語「ファインチューニング」について説明。「事前学習」した訓練済みニューラルネットワークモデルの一部もしくは全体を、別のデータセットを使って再トレーニングすることで、新しいタスク向けにモデルのパラメーターを微調整することを指す。

AI・機械学習の用語辞典:
用語「生成AI」について説明。全く新しいオリジナルのアウトプットを生み出すAI、具体的にはデジタルの画像や動画、オーディオ(音声/音楽など)、文章やコードなどのテキストを生成するAI、もしくはこれらを組み合わせて生成するAIのことを指す。

AI・機械学習の用語辞典:
用語「macro-F1」「micro-F1」「マクロ平均」「マイクロ平均」について説明。macro-F1は、多クラス分類タスク(問題)に対する評価指標の一つで、クラスごとに計算したF1スコアの平均値を意味し、その値が1.0に近いほど分類を予測する機械学習モデルの性能が高い。

AI・機械学習の用語辞典:
用語「mAP」について説明。多クラス分類タスク(問題)に対する評価指標の一つで、各クラスのAP(Average Precision:平均適合率)を平均した値を意味し、mAP値が1.0に近いほど分類を予測する機械学習モデルの性能が高い。物体検知の評価指標としてよく使われている。

AI・機械学習の用語辞典:
用語「PR-AUC」、別名「AP」について説明。二値分類タスク(問題)に対する評価指標の一つで、「PR曲線の下の面積」を意味し、PR-AUC値が1.0に近いほど分類を予測する機械学習モデルの性能が高い。

AI・機械学習の用語辞典:
用語「AUC」について説明。二値分類タスク(問題)に対する評価指標の一つで、「ROC曲線の下の面積」を意味し、AUC値が1.0に近いほど分類を予測する機械学習モデルの性能が高い。

AI・機械学習の用語辞典:
用語「LogLoss」について説明。分類タスク(問題)に対する評価指標の一つで、「機械学習モデルによる予測が正解にどれくらい近いか」、つまり予測の確実性の高さを表す。

AI・機械学習の用語辞典:
用語「重み付きF値」、別名:「Fβスコア」について説明。二値分類タスク(問題)に対する評価指標の一つで、適合率と再現率のトレードオフ関係に着目し、2つの値を重み付き調和平均「(1+β二乗)×(適合率×再現率)÷(β二乗×適合率+再現率)」した値を指す。

AI・機械学習の用語辞典:
用語「F値」、別名:「F1スコア」について説明。二値分類タスク(問題)に対する評価指標の一つで、適合率と再現率のトレードオフ関係に着目し、2つの値を調和平均「2×(適合率×再現率)÷(適合率+再現率)」した値を指す。

AI・機械学習の用語辞典:
用語「特異度」について説明。二値分類タスク(問題)に対する評価指標の一つで、実際の正解値が「陰性」で、かつ、予測値も「陰性」だった正解数(=TN)を、実際の正解値が「陰性」である全てのデータ数(=FP+TN)で割った値を指す。

AI・機械学習の用語辞典:
用語「再現率」、別名:「感度」について説明。二値分類タスク(問題)に対する評価指標の一つで、実際の正解値が「陽性」で、かつ、予測値も「陽性」だった正解数(=TP)を、実際の正解値が「陽性」である全てのデータ数(=TP+FN)で割った値を指す。

AI・機械学習の用語辞典:
用語「適合率」について説明。二値分類タスク(問題)に対する評価指標の一つで、機械学習モデルによる予測値が「陽性」で、かつ、実際の正解値も「陽性」だった正解数(=TP)を、「陽性」と予測した全てのデータ数(=TP+FP)で割った値を指す。

AI・機械学習の用語辞典:
用語「正解率」について説明。分類タスク(問題)に対する評価指標の一つで、機械学習モデルによる予測結果における正解数をデータ数で割った値を指す。

AI・機械学習の用語辞典:
用語「不均衡データ」について説明。分類問題におけるラベル(目的変数)の各クラス数の比率が大きく偏っているデータを指す。不均衡データでは評価値に注意し、場合によっては不均衡を是正するための工夫を行う必要がある。

AI・機械学習の用語辞典:
用語「多クラス分類の混同行列」について説明。多クラス分類のタスク(問題)における「そのクラス数分の行項目と同数分の列項目で構成される分割表」を指す。

AI・機械学習の用語辞典:
用語「混同行列」について説明。陽性/陰性のどちらかに分類する二値分類のタスク(問題)に対する評価指標の計算式などで活用される4セル(=2行×2列)の分割表を指す。

AI・機械学習の用語辞典:
用語「DX」について説明。デジタルデータとデジタル技術(AIやデータサイエンス)を活用することによって、ビジネス上の新しい価値を生み出すことを指す。

AI・機械学習の用語辞典:
用語「マルチモーダルAI」について説明。テキスト/画像/音声/数値など複数の種類のモダリティー(データ種別)を一度に処理できる統合されたAIモデルを指す。

AI・機械学習の用語辞典:
用語「責任あるAI」について説明。倫理的な問題やプライバシー、セキュリティーなどの潜在的なリスクに企業や組織が責任を持って取り組み、作成したAIが安全で信頼できバイアスがないことを保証すること、またはそのための指針として掲げる基本原則やプラクティスのことを指す。

AI・機械学習の用語辞典:
用語「人間中心のAI」について説明。人間の能力を機械(AI)に置き換える「自律的なAI」のアプローチよりも、機械(AI)を使って人間の能力や体験を向上させる「人間中心のAI」のアプローチの方が大切だとする、AIの研究/構築方法に関する考え方を指す。その考え方では、「人間と機械の相互作用」および「人々や社会への倫理的な影響」に関心を向けることも重要視される。

AI・機械学習の用語辞典:
用語「ヒューマン・イン・ザ・ループ」について説明。機械学習においては、データ収集と前処理〜モデルの訓練〜運用監視〜継続的なアップデートというライフサイクルの中に人間との相互作用、つまり人間からのフィードバックが含まれることを指す。人間参加型のAIとも呼ばれる。

AI・機械学習の用語辞典:
用語「ドリフト」について説明。何らかの変化によってモデルの予測性能が劣化すること。その原因が、正解ラベルの概念が変化した場合は「概念ドリフト」、入力データの統計的分布が訓練時から変化した場合は「データドリフト」と呼ばれる。

AI・機械学習の用語辞典:
用語「データ中心のAI」について説明。性能を向上させるために、モデルやアルゴリズムを改善する「モデル中心」のアプローチではなく、機械学習ライフサイクル全体を通じてデータを改善する「データ中心」のアプローチの方が大切だとする、AIの開発方法に関する考え方を指す。

AI・機械学習の用語辞典:
用語「SOTA(State-of-the-Art)」について説明。機械学習では、ある特定のタスク&ベンチマークとなるデータセットにおいて論文の内容とその機械学習モデルが「現時点での最先端レベル(=最良/最高)の性能(=正解率などのスコア/精度)」を達成していることを表す。

AI・機械学習の用語辞典:
用語「tf-idf」について説明。各文書中に含まれる各単語が「その文書内でどれくらい重要か」を表す尺度で、具体的には「(ある文書における、ある単語の出現頻度)×(ある単語の文書間でのレア度)」などの計算値のこと。主に文書検索やレコメンデーションに使われている。

AI・機械学習の用語辞典:
用語「コサイン類似度」について説明。2つのベクトルが「どのくらい似ているか」という類似性を表す尺度で、具体的には2つのベクトルがなす角のコサイン値のこと。1なら「似ている」を、-1なら「似ていない」を意味する。主に文書同士の類似性を評価するために使われている。

AI・機械学習の用語辞典:
用語「残差平方和」「二乗和誤差」について説明。残差平方和は、線形回帰の最小二乗法で用いられる関数の一つで、各データに対して「観測値と予測値の差(=残差)」の平方値を計算し、それを総和した値を表す。二乗和誤差は、損失関数の一つで、各データに対して「予測値と正解値の差(=誤差)」の二乗値を計算し、それを総和した値、もしくはさらにそれを2で割った値を表す。

AI・機械学習の用語辞典:
用語「マンハッタン距離」「ユークリッド距離」について説明。いずれも2点間の距離を計測する方法のこと。マンハッタン距離とは、碁盤の目状の道を縦に横にとタクシーが進むようにn次元の距離(=差)の絶対値を合計することで距離を計算する方法。ユークリッド距離とは、n次元の距離(=差)の二乗値を合計した値の平方根を求める(=ピタゴラスの定理を適用する)ことで直線的な最短距離を計算する方法を意味する。

AI・機械学習の用語辞典:
用語「相対絶対誤差」「相対二乗誤差」について説明。相対絶対誤差は、平均絶対誤差を平均絶対偏差(=データの広がり具合)で割ることでスケールを調整(=相対化)した評価値を表す。相対二乗誤差は、平均二乗誤差を分散(=データの広がり具合)で割ることでスケールを調整(=相対化)した評価値を表す。

AI・機械学習の用語辞典:
用語「分散説明率」について説明。線形回帰モデルなどの評価関数の一つで、回帰式のモデルが「観測データの分散」のうちどれくらいの割合を説明するかを表す。決定係数R2の代わりに用いられることがある。

AI・機械学習の用語辞典:
用語「相関係数(ピアソンの積率相関係数)」について説明。相関係数とは2つの変数間の関係の強さと方向性を表す、1〜0〜-1の範囲の数値。1(強い正の相関)では、2つの変数が強く同方向に連動する。-1(強い負の相関)では強く逆方向に連動する。相関なしでは、連動しない。

AI・機械学習の用語辞典:
正規化とは、比較や分析を容易にするために、データの単位やスケールを共通の基準に整えること。単に「正規化」(Min-Max法)と言った場合は、データを最小値「0」〜最大値「1」にスケーリングすることを意味する。また、正規化の一種である標準化は、データを平均「0」、標準偏差「1」にスケーリングすることを意味する。

AI・機械学習の用語辞典:
用語「平均絶対偏差」「中央絶対偏差」について説明。いずれもデータの広がり具合を表す統計量。平均絶対偏差は、各データに対して「平均値との差」(=偏差)の絶対値を計算し、その総和をデータ数で割った値(=平均値)を表す。中央絶対偏差は、各データに対して「中央値との差」(=偏差)の絶対値を計算し、その全ての絶対値から求めた中央値を表す。

AI・機械学習の用語辞典:
用語「分散」「標準偏差」について説明。いずれもデータの広がり具合を表す統計量。分散は、各データに対して「平均値との差」(=偏差)の二乗値を計算し、その総和をデータ数で割った値(=平均値)を表す。標準偏差は、分散に対する平方根の値を表す。

AI・機械学習の用語辞典:
用語「平均値」「中央値」「最頻値」について説明。平均値はデータの合計値をデータ数で割った値、中央値はデータを順番に並べた際に中央に位置する値、最頻値は最も頻繁に出現する値を表す。

AI・機械学習の用語辞典:
用語「決定係数R2(R二乗)」について説明。線形回帰モデルの評価関数の一つで、回帰式のモデルによる予測が観測データにどれくらい当てはまるかを表す。

AI・機械学習の用語辞典:
用語「中央絶対誤差」について説明。評価関数の一つで、各データに対して「予測値と正解値の差(=誤差)」の絶対値を計算していき、それら全ての計算結果における中央値を表す。

AI・機械学習の用語辞典:
用語「Huber損失」について説明。損失関数の一つで、各データに対する「予測値と正解値の差(=誤差)」が、指定したパラメーター値の範囲内の場合は二乗値を使った計算、範囲外の場合は絶対値を使った計算の結果値のこと、もしくはその計算結果の総和をデータ数で割った値(=平均値)を表す。

AI・機械学習の用語辞典:
用語「平均二乗パーセント誤差の平方根」について説明。評価関数の一つで、各データに対して「予測値と正解値との差を、正解値で割った値(=パーセント誤差)」の二乗値を計算し、その総和をデータ数で割った値(=平均値)に対する平方根の値を表す。

AI・機械学習の用語辞典:
用語「平均絶対パーセント誤差」について説明。評価関数の一つで、各データに対して「予測値と正解値との差を、正解値で割った値(=パーセント誤差)」の絶対値を計算し、その総和をデータ数で割った値(=平均値)を表す。

AI・機械学習の用語辞典:
用語「平均二乗対数誤差」について説明。損失関数/評価関数の一つで、各データに対して「予測値の対数と正解値の対数との差(=対数誤差)」の二乗値を計算し、その総和をデータ数で割った値(=平均値)を表す。

AI・機械学習の用語辞典:
用語「平均二乗誤差」について説明。損失関数/評価関数の一つで、各データに対して「予測値と正解値の差(=誤差)」の二乗値を計算し、その総和をデータ数で割った値(=平均値)を表す。

AI・機械学習の用語辞典:
用語「平均絶対誤差」について説明。損失関数/評価関数の一つで、各データに対して「予測値と正解値の差(=誤差)」の絶対値を計算し、その総和をデータ数で割った値(=平均値)を表す。

AI・機械学習の用語辞典:
用語「評価関数」について説明。機械学習モデルの性能/精度をスコアリングして評価するための関数を指し、例えば回帰問題なら平均二乗誤差、分類問題なら正解率などの関数がある。

AI・機械学習の用語辞典:
用語「損失関数」について説明。「正解値」と、モデルによる出力された「予測値」とのズレの大きさである損失値を計算するための関数を指し、例えば平均二乗誤差などの関数がある。

AI・機械学習の用語辞典:
用語「シンプソンのパラドックス」について説明。主に層別の分割表において、グループ間に見られる相関関係が「全体でも成り立つだろう」と直感的に推測されるのに対し、場合によっては、全体では異なる結果になる現象を指す。

AI・機械学習の用語辞典:
用語「身体性」について説明。物理的に身体が存在することによる効果を論じる問題を指す。現状のコンピュータ/人工知能は必ずしも身体性を有していないので、人間と同じようには知能を獲得できないとされる。

AI・機械学習の用語辞典:
用語「シンボルグラウンディング問題」について説明。記号(言葉)が実世界の意味に結び付いているかを論じる問題を指す。現状のコンピュータ/人工知能は必ずしも結び付いておらず、言葉を理解していないとされる。

AI・機械学習の用語辞典:
用語「無色の緑の考えが猛烈に眠る」について説明。文法的には正しいが意味的にはナンセンスな文章の例として、言語学や自然言語処理でよく用いられている。

AI・機械学習の用語辞典:
用語「中国語の部屋」について説明。チューリングテストへの反論として提起された思考実験。中国語による質疑応答テストで、英語しか分からない人が中国語の質問に適切に回答できる方法を提示することで、この種のテストに合格しても「中国を理解していることは意味しない」という点を反論の根拠とする。

AI・機械学習の用語辞典:
用語「チューリングテスト」について説明。人工知能(「機械」や「コンピュータ」とも呼ばれる)が人間をどれだけ真似られるかをテストすること。審査員は自然言語による会話を通じて、相手が人工知能か人間かを判定する。ただし、人工知能の「知性」や「知覚力(感覚を通じた情報の認識・解釈能力)」を測定するものではない。

AI・機械学習の用語辞典:
用語「トロッコ問題」について説明。「多くの人を助けるためなら、1人を犠牲にしてもよいのか」という倫理的ジレンマを問う思考実験を指す。この問題に正解はない。自動運転で注目されている。

AI・機械学習の用語辞典:
用語「フレーム問題」について説明。有限の処理能力しか持たないAI/ロボットは、無限の可能性を含む現実的な課題において、その課題に関係のあることだけを選び出して(=フレームを設定して)適切に実行するのが難しいことを指す。

AI・機械学習の用語辞典:
用語「Garbage In, Garbage Out」について説明。ゴミ(Garbage)のような不良データを入力すると、出来上がる機械学習モデルもゴミのように不良なものになる、という戒め/金言のこと。ゴミを入れないのは簡単なように見えて難しい。

AI・機械学習の用語辞典:
用語「トイプロブレム」について説明。迷路やオセロのようにルールとゴールが決まっている世界の問題をAIで解くことであり、転じて、そのような世界観の問題しか解けないことを指す。第1次AIブームを終焉(しゅうえん)させた理由とされる。

AI・機械学習の用語辞典:
用語「モラベックのパラドックス」について説明。機械学習モデルを含むAI(人工知能)やロボット工学において、大人が行うような高度な知性に基づく推論よりも、1歳児が行うような本能に基づく運動スキルや知覚を身に付ける方がはるかに難しい、という定説を示す。

AI・機械学習の用語辞典:
用語「偏りと分散のトレードオフ」について説明。機械学習モデルによる予測において汎化誤差を最小化させるために、偏り誤差を小さくするとバラツキ(分散)誤差が大きくなり、逆にバラツキ誤差を小さくすると偏り誤差が大きくなるという、両者のトレードオフの関係性を示す。

AI・機械学習の用語辞典:
用語「内挿/外挿(Interpolation/Extrapolation)」について説明。機械学習モデルで、訓練データの範囲内で出力を求めることを「内挿」、範囲外で求めることを「外挿」と呼ぶ。機械学習モデルは、原理的に内挿は得意だが、外挿は苦手。

AI・機械学習の用語辞典:
用語「バーニーおじさんのルール(Uncle Bernie's rule)」について説明。ニューラルネットワークの重みパラメーター数の10倍以上の訓練データが最低限必要であるとする経験則を指す。

AI・機械学習の用語辞典:
用語「みにくいアヒルの子の定理(Ugly Duckling theorem)」について説明。何らかの仮定/前提知識がないと、分類やパターン認識は不可能であることを指す。

AI・機械学習の用語辞典:
用語「ノーフリーランチ定理(No Free Lunch theorem)」について説明。全ての問題において優れた性能を発揮できる“万能”の「教師ありの機械学習モデル」や「探索/最適化のアルゴリズム」など(=無料のランチ)は理論上、存在しないことを指す。

AI・機械学習の用語辞典:
用語「次元の呪い」について説明。特徴量などの次元が多くなるほど、必要な訓練データの量が「指数関数」的に増えてしまう現象を指す。

AI・機械学習の用語辞典:
用語「SELU(Scaled Exponential Linear Unit)」について説明。「0」を基点として、入力値が0以下なら「0」〜「-λα」(λは基本的に約1.0507、αは基本的に約1.6733)の間の値を、0より上なら「入力値をλ倍した値」を返す、ニューラルネットワークの活性化関数を指す。ReLUおよびELUの拡張版。

AI・機械学習の用語辞典:
用語「ELU(Exponential Linear Unit)」について説明。「0」を基点として、入力値が0以下なら「0」〜「-α」(αは基本的に1.0)の間の値を、0より上なら「入力値と同じ値」を返す、ニューラルネットワークの活性化関数を指す。ReLUの拡張版。

AI・機械学習の用語辞典:
用語「PReLU(Parametric ReLU)」について説明。「0」を基点として、入力値が0より下なら「入力値をα倍した値」(αはパラメーターであり学習により決まる)、0以上なら「入力値と同じ値」を返す、ニューラルネットワークの活性化関数を指す。ReLUやLeaky ReLUの拡張版。

AI・機械学習の用語辞典:
用語「Leaky ReLU(Leaky Rectified Linear Unit)/LReLU」について説明。「0」を基点として、入力値が0より下なら「入力値とα倍した値」(α倍は基本的に0.01倍)、0以上なら「入力値と同じ値」を返す、ニューラルネットワークの活性化関数を指す。ReLUの拡張版。

AI・機械学習の用語辞典:
用語「Mish関数」について説明。「0」を基点として、入力値が0以下なら出力値は「ほぼ0」だが(わずかに「負の値」になる)、0より上なら「入力値とほぼ同じ値」を返す、ニューラルネットワークの活性化関数を指す。類似するReLUやSwish関数の代替として使われる。

AI・機械学習の用語辞典:
用語「ソフトプラス関数」について説明。途中から右肩上がりになる滑らかな曲線で、「0」〜「∞」の間の値(入力値が0以下なら「0」に近い数値、0より上なら「入力値と同じ値」に近い数値)を返す、ニューラルネットワークの活性化関数を指す。

AI・機械学習の用語辞典:
用語「Swish関数」について説明。「0」を基点として、0以下なら「ほぼ0」だが(わずかに「負の値」になる)、0より上なら「入力値とほぼ同じ値」を返す、ニューラルネットワークの活性化関数を指す。類似するReLUの代替として使われる。

AI・機械学習の用語辞典:
用語「ソフトマックス関数(Softmax function)」について説明。複数の入力値(=ベクトルの各成分)をそれぞれ「0.0」〜「1.0」の確率値に変換し、複数の出力値(=ベクトルの各成分)の合計が常に「1.0」(=100%)になる関数を指す。ニューラルネットワークの出力層での活性化関数として、特に多クラス分類問題で使用される。

AI・機械学習の用語辞典:
用語「恒等関数(線形関数)」について説明。入力値と全く同じ数値を返す、ニューラルネットワークの活性化関数を指す。

AI・機械学習の用語辞典:
用語「活性化関数」について説明。人工ニューラルネットワークにおける、ある1つのニューロンにおいて、入力を受けて、次のニューロンへ出力するために行う「非線形変換の処理(関数)」もしくは「恒等関数」を指す。

AI・機械学習の用語辞典:
用語「tanh関数(双曲線正接関数)」について説明。座標点(0, 0)を基点(変曲点)として点対称となるS字型の滑らかな曲線で、「-1」〜「1」の間の値を返す、ニューラルネットワークの活性化関数を指す。

AI・機械学習の用語辞典:
用語「ReLU(Rectified Linear Unit)/ランプ関数」について説明。「0」を基点として、0以下なら「0」、0より上なら「入力値と同じ値」を返す、ニューラルネットワークの活性化関数を指す。

AI・機械学習の用語辞典:
用語「シグモイド関数(Sigmoid function)」について説明。座標点(0, 0.5)を基点(変曲点)として点対称となるS字型の滑らかな曲線で、「0」〜「1」の間の値を返す、ニューラルネットワークの活性化関数を指す。

AI・機械学習の用語辞典:
用語「ステップ関数(Step function)」について説明。「0」を基点(閾値)として、0未満なら「0」、0以上なら「1」を返すような、ニューラルネットワークの活性化関数を指す。

AI・機械学習の用語辞典:
用語「公平性(Fairness)」について説明。機械学習モデルが不当な差別(人種差別/民族差別や、性別差別、文化差別/地域差別など)を引き起こさないように、不公平なバイアスを排除することを指す。

AI・機械学習の用語辞典:
用語「アカウンタビリティ(Accountability)」について説明。ガバナンスと倫理の観点で、AIシステムの設計/実装の情報開示から結果/決定の説明までを行い、利害関係者に納得してもらう責任を指す。簡単に言うと、「AIシステムの挙動に対して、誰が/何が、責任を持つのか」を明らかにすること。

AI・機械学習の用語辞典:
用語「MLOps(“Machine Learning”と“Operations”の合成語)」について説明。機械学習モデルの実装〜運用のライフサイクルを円滑に進めるために築かれる、機械学習チーム/開発チームと運用チームが協調し合う管理体制(機械学習基盤)を指す。

AI・機械学習の用語辞典:
用語「透明性(Transparency)」について説明。機械学習のプロセスや内容が誰にでもはっきりと分かるようになっていること、またはそのような状態にすることを指す。

AI・機械学習の用語辞典:
用語「説明可能なAI」および「解釈性」について説明。推定結果に至るプロセスを人間が説明できるようになっている機械学習モデル(=AI本体)のこと、あるいはその技術・研究分野を指す。

AI・機械学習の用語辞典:
用語「PoC貧乏」について説明。AIテクノロジー企業にとって、PoCばかりを行い、実際のプロジェクトが何も開始できない事態を指す。

AI・機械学習の用語辞典:
用語「PoC(Proof of Concept:概念実証)」について説明。コンセプト(概念)の実現可能性を検証することを指す。

AI・機械学習の用語辞典:
用語「シンギュラリティ」について説明。人工知能がさらに優れた人工知能を再帰的に創造していくことで、人間を完全に超える圧倒的に高度な知性が生み出されるとする仮説を指す。

AI・機械学習の用語辞典:
用語「人工知能」について説明。人間が行う「知的活動」をコンピュータプログラムとして実現することを指す。

AI・機械学習の用語辞典:
用語「精度検証データ」「評価データ」について説明。モデルの性能評価/精度検証で使うチューニング用データを指す。

AI・機械学習の用語辞典:
用語「教師なし学習」について説明。正解が決まっていないトレーニングデータを使って学習する方法を指す。正解のラベル(教師データ)は必要ない。

AI・機械学習の用語辞典:
用語「転移学習」について説明。ある特定領域で学習済みのモデルに追加学習させることでカスタマイズし、別の領域に適応させる技術を指す。

AI・機械学習の用語辞典:
用語「トレーニングデータ」について説明。学習において、モデルのトレーニングに使うデータを指す。

AI・機械学習の用語辞典:
用語「トレーニング」について説明。機械学習モデルのパラメーター(ニューラルネットワークであれば重みやバイアスなど)を自動的に調整していくことを指す。

AI・機械学習の用語辞典:
用語「テストデータ」について説明。完成候補のモデルに対して使う最終テスト用のデータを指す。

AI・機械学習の用語辞典:
用語「TensorFlow」について説明。グーグルが公開している機械学習用のオープンソースライブラリを指す。特にニューラルネットワークの実装でよく使われている。

AI・機械学習の用語辞典:
用語「教師あり学習」について説明。正解が決まっているトレーニングデータを使って学習する方法を指す。正解は、ラベル(教師データ)として学習前に作成しておく必要がある。

AI・機械学習の用語辞典:
用語「音声生成」「音楽生成」について説明。AIにより、音声を機械的に作成すること、または作曲することを指す。


AI・機械学習の用語辞典:
用語「半教師あり学習」について説明。教師あり学習と教師なし学習を組み合わせて学習する方法を指す。

AI・機械学習の用語辞典:
用語「RNN」について説明。ネットワーク内部に再帰構造を持つ、ディープニューラルネットワークのアルゴリズムの一種を指す。

AI・機械学習の用語辞典:
用語「強化学習」について説明。プログラムの行動に対するフィードバック(報酬・罰)をトレーニングデータとして使って学習する方法を指す。


AI・機械学習の用語辞典:
用語「自然言語処理」について説明。言葉を理解して情報を抽出して識別や未来予測をすること(認識モデル)、もしくは会話文章などを生成すること(生成モデル)を指す。

AI・機械学習の用語辞典:
用語「ニューラルネットワーク」について説明。人間の神経回路を真似して、入力層→1つ以上の隠れ層(中間層)→出力層という多層ネットワークを構成する手法を指す。

AI・機械学習の用語辞典:
用語「モデル」について説明。機械学習において、学習後の具体的な計算式/計算方法を指す。基本的に[入力]→[モデル]→[出力]という関係性がある。

AI・機械学習の用語辞典:
用語「機械学習」について説明。人間が行う知的活動の一つである「学習」をコンピュータプログラムによって実現することを指す。人工知能(AI)の一種。

AI・機械学習の用語辞典:
用語「LSTM」について説明。ネットワーク内部での短期記憶を長期間、活用できる構造を持つ、ディープニューラルネットワークのアルゴリズムの一種を指す。RNNの拡張バージョンであり、長期的な依存関係を学習できるという、より良い特長がある。

AI・機械学習の用語辞典:
用語「学習方法」について説明。モデルを作るための「学習」の方法を指す。教師あり学習/教師なし学習/強化学習などがある。


AI・機械学習の用語辞典:
用語「ラベル」について説明。個々のデータに付与される正解情報を指す。

AI・機械学習の用語辞典:
用語「推論」について説明。機械学習のモデルを「使う」ことを指す。



AI・機械学習の用語辞典:
用語「表現学習」について説明。画像/音声/自然言語から特徴表現(feature)を自動的に抽出する学習を指す。

AI・機械学習の用語辞典:
用語「次元削減」について説明。情報量を本来よりも減らすことで、本質的なデータ構造(特徴:features)を表現することを指す。

AI・機械学習の用語辞典:
用語「ディープニューラルネットワーク」について説明。ニューラルネットワークをディープラーニングに対応させて、ネットワークの階層を深くしたもののことを指す。

AI・機械学習の用語辞典:
用語「ディープラーニング」について説明。機械学習の手法の一つで、通常は、ニューラルネットワークの階層を深くしたもの(ディープニューラルネットワーク)を用いた学習のことを指す。

AI・機械学習の用語辞典:
用語「CNN」について説明。ネットワーク内部に畳み込みとプーリングの層を持つ、ディープニューラルネットワークのアルゴリズムの一種を指す。

AI・機械学習の用語辞典:
用語「クラスタリング」について説明。入力値を、事前に定義されていないグループに分割することを指す。

AI・機械学習の用語辞典:
用語「分類」について説明。離散的な入力値を、事前に定義された複数のクラスに分類することを指す。

AI・機械学習の用語辞典:
用語「AutoML」について説明。機械学習モデルの設計・構築を自動化するための手法全般、またはその概念を指す。

AI・機械学習の用語辞典:
用語「オートエンコーダー」について説明。ネットワークへの入力と出力が同じという構造を持つ、ディープニューラルネットワークのアルゴリズムの一種を指す。


AI・機械学習の用語辞典:
用語「アルゴリズム」について説明。機械学習において、学習前の抽象的な計算式や計算方法を指す。

AI・機械学習の用語辞典:
用語「強いAI」「弱いAI」について、また類義語として「汎用型AI(AGI)」「特化型AI」について説明。「人間が行う知的活動を完全に模倣できるAI」もしくは「特定のタスク(処理)のみを実現するAI」を指す。
注目のテーマ

![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。